版本:v5.4.3
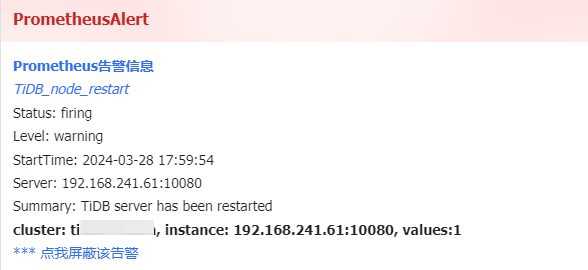
问题:最近一直收到告警 TIDB_node_restart
查看监控使用内存很多导致,因为业务很杂使用的很多,我想定位到具体的问题SQL怎么定位?
下面是一些问题截图:

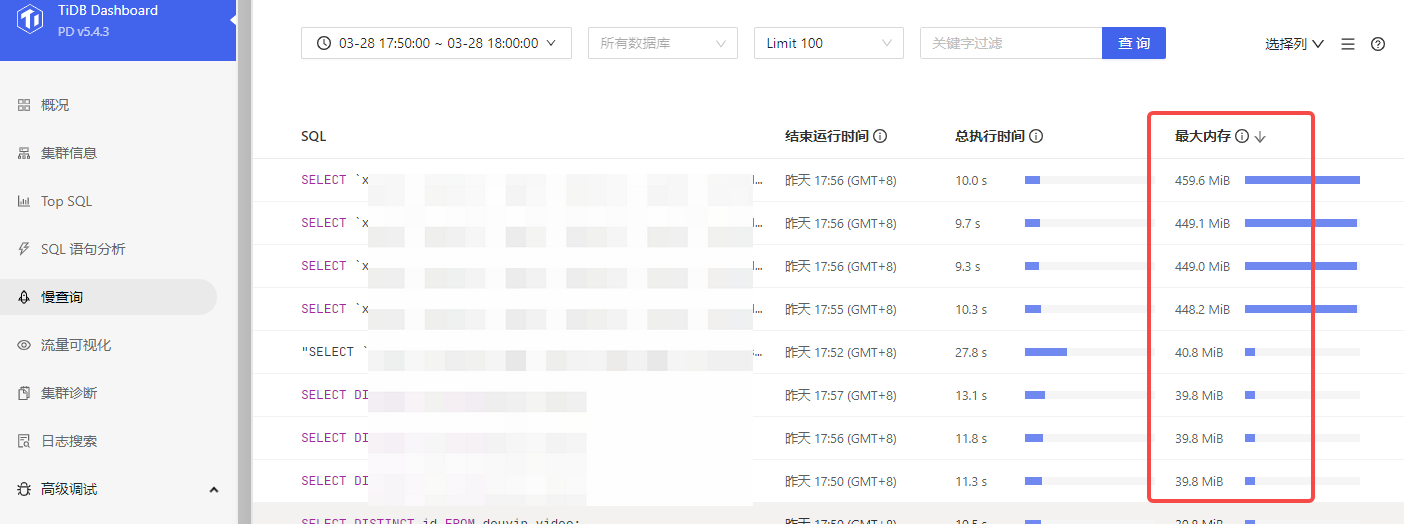
尝试过在Dashboard上搜索慢查询SQL,好像并没看到占用这么大内存的SQL,不知是不是因为SQL没有执行完成所以日志没记录,具体要怎么定位呢?
版本:v5.4.3
问题:最近一直收到告警 TIDB_node_restart
查看监控使用内存很多导致,因为业务很杂使用的很多,我想定位到具体的问题SQL怎么定位?
下面是一些问题截图:
尝试过在Dashboard上搜索慢查询SQL,好像并没看到占用这么大内存的SQL,不知是不是因为SQL没有执行完成所以日志没记录,具体要怎么定位呢?
你自己已经定位到了 就是这些sql
查看tidb日志,会有expensive的SQL
把写sql的人骂一顿。然后把他关小黑屋。把他们组的应用单独部署在一个tidb server前端组件里面。给他们升级专线。哪个tidboom 他自己业务就不可用 不影响他人
你上面的第一条sql先把执行计划发出来看看
这个可以的
才4条400多M的,不至于啊。我们以前集群内存才16G*3,晚上的时候经常被统计的应用弄N条最大内存1G的也没事。会不会是别的原因
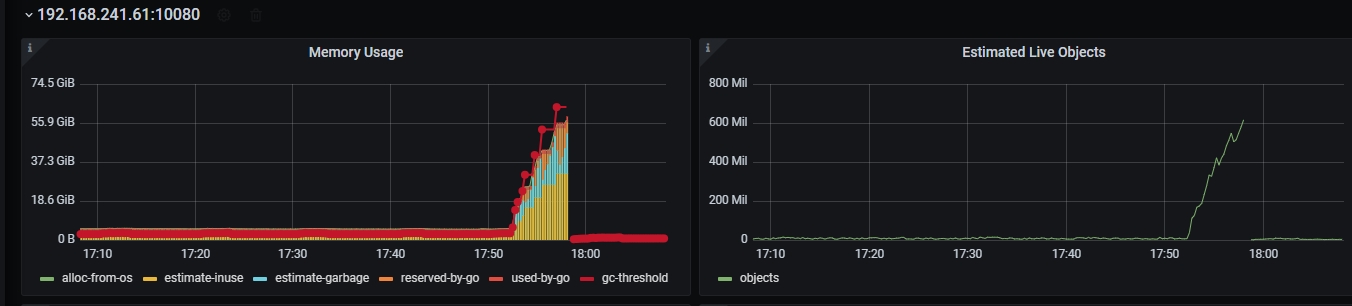
你看我监控,我OOM时的内存占用达到了60多G ,dashboard里面才几百M ,对不上啊
先把top10的sql优化完再看看效果的,很多时候不是单独的某一条sql导致的。
这个可以的
一般都是看tidb 日志中的expensive日志
Slow log 是 SQL 执行结束的时候记录的,oom 的时候进程直接被杀,确实有可能记录不到,记录到的你可以先看看为啥占用内存过多,然后去 Dashboard 上日志搜索功能搜索 tidb server 的日志,搜索 expensive 关键字,又能找到一些 SQL
直接做个监控查日志里面的关键字expensive,不过有的抓不到
基于dashboard 自己优化吧