vcdog
(Vcdog)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.0
【复现路径】今天10:00左右,集群中的一台tidb-server内存突然被打满,3分钟后,产生OOM,实例自动重启
【遇到的问题:问题现象及影响】
tidb和tikv的配置如下:
server_configs:
tidb:
log.level: error
new_collations_enabled_on_first_bootstrap: true
performance.max-procs: 30
performance.txn-total-size-limit: 4221225472
prepared-plan-cache.enabled: true
tidb_mem_oom_action: CANCEL
tidb_mem_quota_query: 1073741824
tmp-storage-path: /acdata/tidb-memory-cache
tmp-storage-quota: -1
tikv:
coprocessor.region-max-size: 384MB
coprocessor.region-split-size: 256MB
raftstore.region-split-check-diff: 196MB
raftstore.store-pool-size: 2
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: false
readpool.unified.max-thread-count: 24
server.end-point-concurrency: 16
server.grpc-concurrency: 28
storage.reserve-space: 0MB
storage.scheduler-worker-pool-size: 16
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
vcdog
(Vcdog)
2
vcdog
(Vcdog)
3
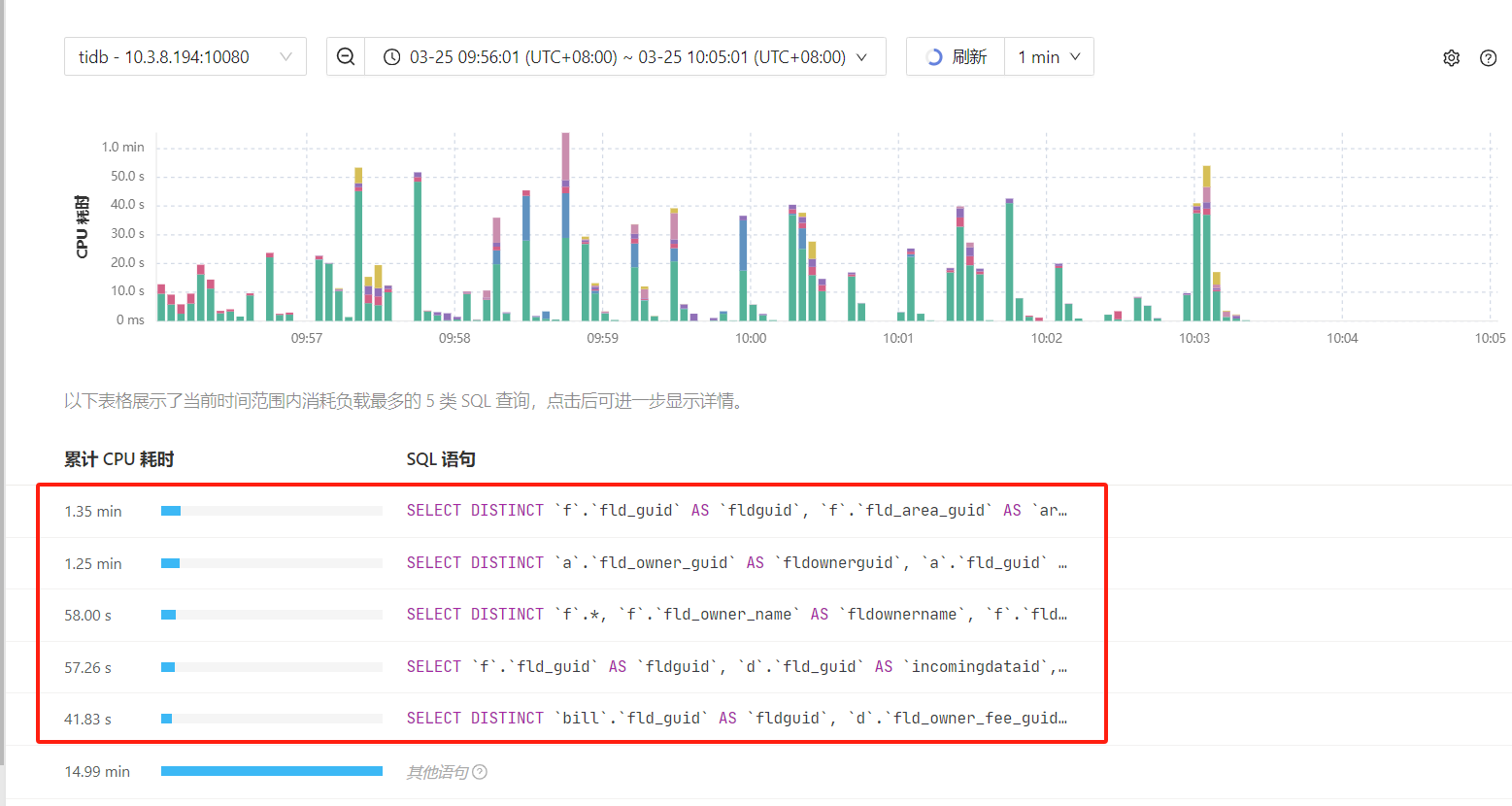
查询dashboard和oom文件夹,都没有发现当时内存被打满时对应的慢SQL,这个有什么好的思路可以追踪一下吗?
小龙虾爱大龙虾
(Minghao Ren)
4
v6.5版本,可以使用top sql功能对照监控的内存上涨时间点看下,定位SQL后优化下SQL
在dashboard-topsql中选择你oom的tidb节点,选择时间段。就能看到那个时间段消耗资源最多的sql
vcdog
(Vcdog)
7
tiDb的dashboard功能很强大,还支持日志搜索。
优化sql呗,数据库的资源监控、topsql、慢查询是每天都要持续关注提前解决问题的,不能等oom了再排查
有猫万事足
12
[2024/03/25 09:56:33.077 +08:00] [ERROR] [client.go:555] [“[pd] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
还是看看整体的监控吧。当时的pd leader也在这台上?报oom前,已经不能获取tso了。
你部署的拓扑,和整体的内存监控来一份。
如果是混布 ,oomkiller选中了tidb。不代表就是tidb的内存失去了控制。
oom 不是说那个sql 而是整体上内存用的多了
你要从整体上解决问题
先解决那些资源占用最多的
我这边直接设置了一个超过60秒的sql直接杀掉的参数,完美解决哈
vcdog
(Vcdog)
17
pd和tikv,tidb-server等组件均为独立部署,不存在共享服务器的情况。
1 个赞
vcdog
(Vcdog)
18
但是,不知道为啥tidb-server的日志里打印pd的信息
有猫万事足
19
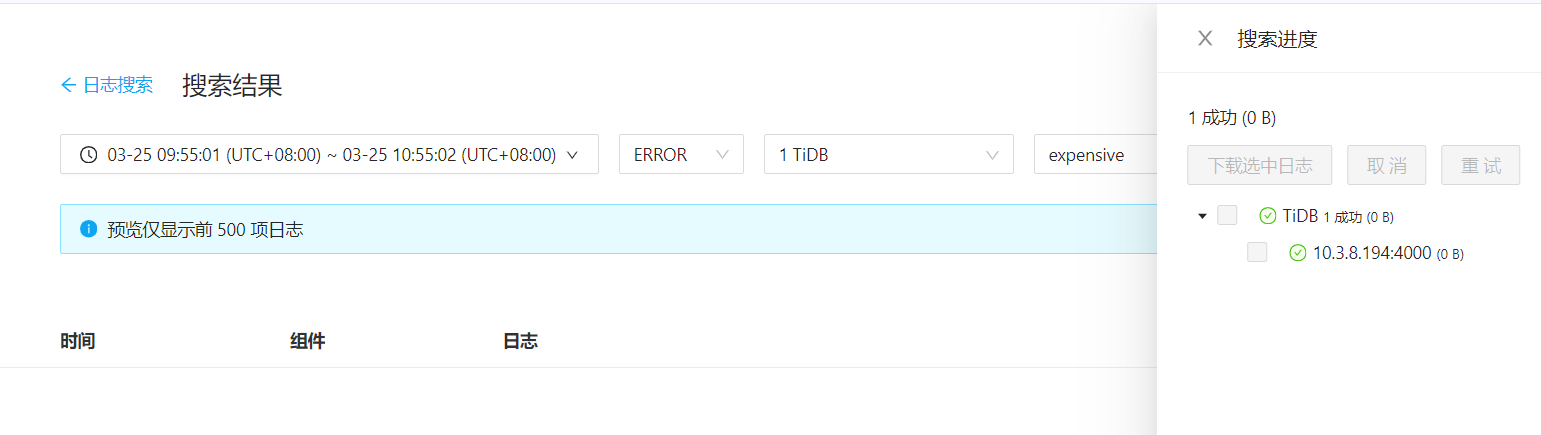
https://docs.pingcap.com/zh/tidb/stable/identify-expensive-queries#expensive-query-日志示例
找不到expensive 是因为你的tidb日志级别太高了。
expensive 是个warning级的告警。
你的配置上可以看到:
tidb:
log.level: error
DBAER
(66666)
20
dashboard 的 top sql 和流量分析图 、日志记录expensive sql 都可以查看一下