【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.2
【遇到的问题:问题现象及影响】业务晚上一跑loaddata,就会有TiKV_async_request_write_duration_seconds告警
【资源配置】tikv都是nvme盘,写入IO没有看到瓶颈
请问大佬门,如何避免这样的告警,调大阈值的话,白天事务交易可能就受影响,可以调raftlog的参数解决吗?
根据经验:
这种问题一般是热点问题,或者是大事务,可以先看一下 tikv thread 面板 中的 Scheduler worker CPU ,是不是都是均衡的。
第二种可能性是磁盘抖动,这种问题要看一下 disk io 的监控。
1 个赞
第二种情况磁盘检查了,没问题。
第一种情况,确定是大事务的情况下,不拆事务怎么搞?业务不愿意拆,推不动。能不能在数据库侧解决
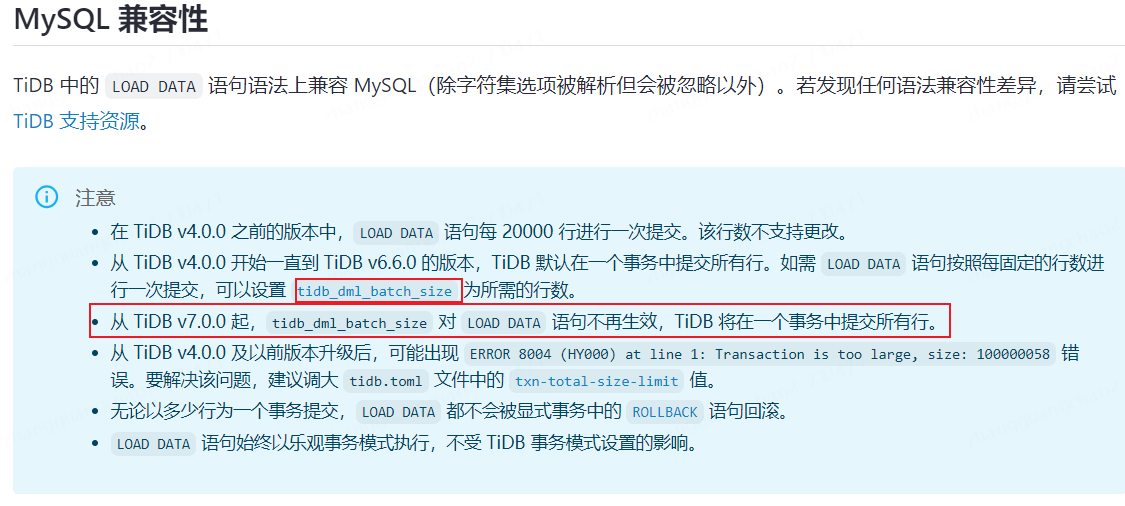
loaddata我理解可以,insert呢。有insert values 1w行的 ![]() 。
。
这种不改的话不好弄,改改的话,有batch
https://docs.pingcap.com/zh/tidb/v6.5/sql-statement-batch
也能非事务的写入
1 个赞
尝试增加raft_log_gc_threshold参数的值,以减少Raft日志的清理频率
这里的优化方法参考一下
https://docs.pingcap.com/zh/tidb/stable/alert-rules#tikv_async_request_write_duration_seconds
1 个赞
batch场景太有限了
我理解这是raft日志同步慢,减少不就同步更慢了吗?
参考了的,就是想问问有没有人改过raftstore.store-pool-size参数,效果怎么样对大事务
我没改过,但是看专栏里有人修改过。
2 个赞
目前没看到调整raft log大小(类似Oracle redo大小),只能调整store的cpu的个数尝试一下
1 个赞
raft log 的 GC 触发阈值,这个能调
请教一下,这个参数具体叫啥?
我觉得按照你的描述,如果io,或者网络不是瓶颈所在。那确实应该调大cpu个数试试看。
起码把io或者网络中的一项跑满才算正常。
是的,这个告警应该分场景。夜间大批量写入数据是可以不关注的,但是白天又是oltp,写入慢就有问题了。调大cpu只是一种对策。htap这样的库,告警也应该搞两套。
我搜了下,alertmanager确实没有周期性静默告警的方法。
只能是下面这样。处理一下。
需求:我需要每天屏蔽某个时间段的某些告警项
比如:凌晨4点会异地备份,导致流量报警,我想屏蔽每天4点-4点30分的该告警项
思路:
直接操作是没有这个步骤的,曲线救国吧;
(1)定时任务,每天凌晨四点的 silences
(2)定时任务中使用 alertmanager api 来建设
1 个赞
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。