【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.5.1
【遇到的问题:问题现象及影响】
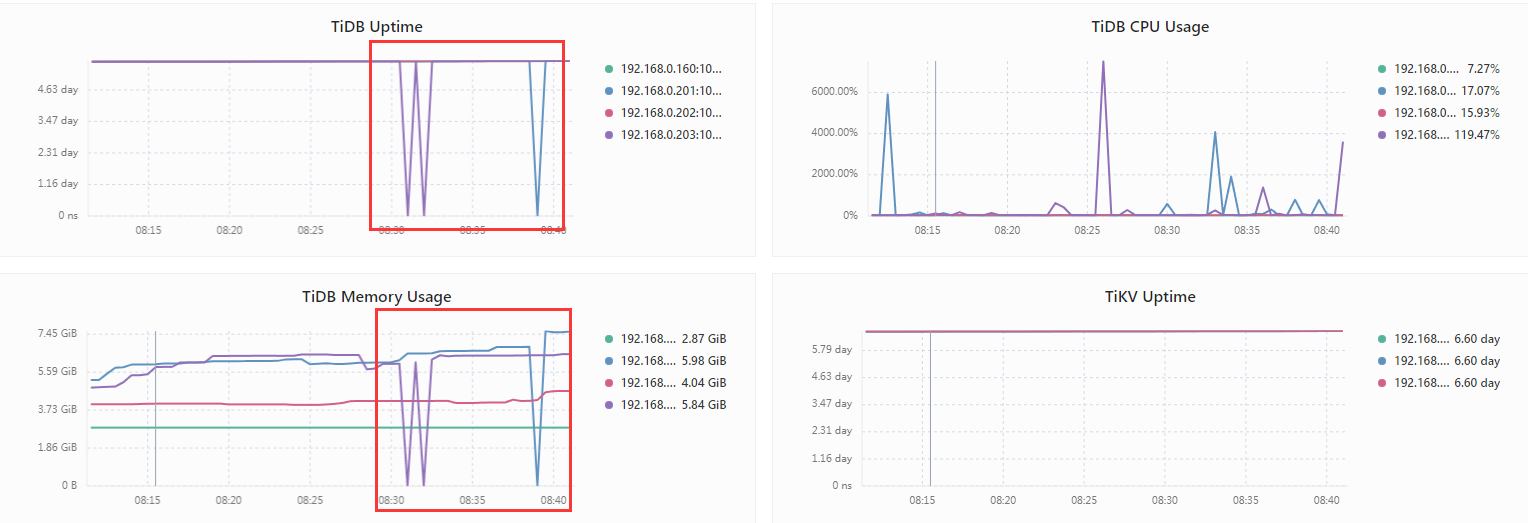
每天有5-6次会存在 tidb-server会突然掉线然后几秒恢复正常,类似这种情况应该如何排查问题呢?
下面是掉线时tidb-server CPU和内存使用情况
你集群的配置咋样,另外看下tidb-server的日志报啥错
oom了吧
肯定有error日志吧
看存活时间不是重启了,网络不通?
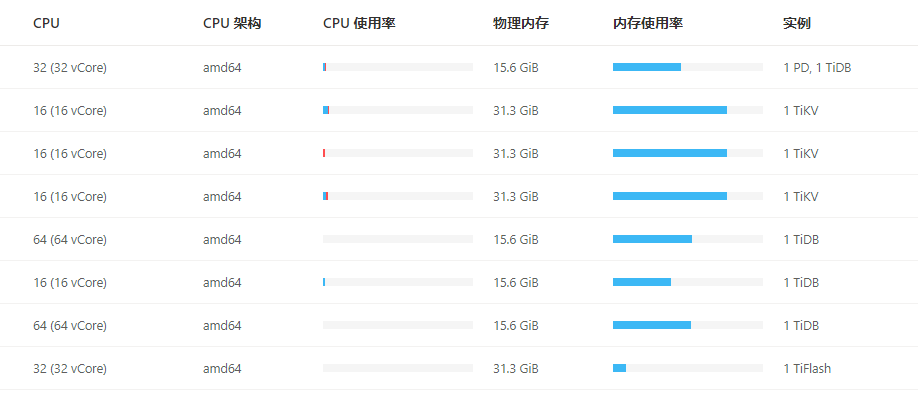
重启这个203上面的tidb是哪个,64C这两个中的一个?CPU使用率能达到6000%多。。。
这是tidb.log中今天打印出的日志信息
[2024/03/15 00:12:31.194 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 00:12:31.204 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: [PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:12:31.209 +00:00] [ERROR] [pd.go:236] [“updateTS error”] [txnScope=global] [error=“[PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:39:04.806 +00:00] [ERROR] [advancer.go:398] [“listen task meet error, would reopen.”] [error=“etcdserver: mvcc: required revision has been compacted”]
[2024/03/15 00:39:04.816 +00:00] [ERROR] [domain.go:1743] [“LoadSysVarCacheLoop loop watch channel closed”]
[2024/03/15 00:39:04.824 +00:00] [ERROR] [domain.go:1680] [“load privilege loop watch channel closed”]
[2024/03/15 00:39:04.847 +00:00] [ERROR] [pd_service_discovery.go:257] [“[pd] failed to update member”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetMember]get member failed”]
[2024/03/15 00:41:36.166 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 00:41:36.166 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: [PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:41:36.167 +00:00] [ERROR] [pd.go:236] [“updateTS error”] [txnScope=global] [error=“[PD:client:ErrClientTSOStreamClosed]encountered TSO stream being closed unexpectedly”]
[2024/03/15 00:53:11.374 +00:00] [ERROR] [pd_service_discovery.go:284] [“[pd] failed to update service mode”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetClusterInfo]error:rpc error: code = DeadlineExceeded desc = context deadline exceeded target:192.168.0.160:2379 status:READY: error:rpc error: code = DeadlineExceeded desc = context deadline exceeded target:192.168.0.160:2379 status:READY”]
[2024/03/15 00:53:11.377 +00:00] [ERROR] [pd_service_discovery.go:284] [“[pd] failed to update service mode”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetClusterInfo]error:rpc error: code = Unavailable desc = error reading from server: EOF target:192.168.0.160:2379 status:CONNECTING: error:rpc error: code = Unavailable desc = error reading from server: EOF target:192.168.0.160:2379 status:CONNECTING”]
[2024/03/15 00:53:11.377 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 00:53:11.377 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: rpc error: code = Unavailable desc = error reading from server: EOF”]
[2024/03/15 00:53:11.378 +00:00] [ERROR] [pd.go:236] [“updateTS error”] [txnScope=global] [error=“rpc error: code = Unavailable desc = error reading from server: EOF”]
[2024/03/15 00:53:11.478 +00:00] [ERROR] [pd_service_discovery.go:257] [“[pd] failed to update member”] [urls=“[http://192.168.0.160:2379]”] [error=“[PD:client:ErrClientGetMember]get member failed”]
[2024/03/15 01:04:24.717 +00:00] [ERROR] [tso_dispatcher.go:202] [“[tso] tso request is canceled due to timeout”] [dc-location=global] [error=“[PD:client:ErrClientGetTSOTimeout]get TSO timeout”]
[2024/03/15 01:04:24.718 +00:00] [ERROR] [tso_dispatcher.go:498] [“[tso] getTS error after processing requests”] [dc-location=global] [stream-addr=http://192.168.0.160:2379] [error=“[PD:client:ErrClientGetTSO]get TSO failed, %v: rpc error: code = Canceled desc = context canceled”]
会有几次达到6000%,达到后很快会掉下来
考虑网络闪断, 结合网络监控看看。
1 个赞
一共就一个PD么,把PD扩容成三个看看
好,我试下
把 PD 的节点独立出来,不要和 tidb 混合在一起…
看样子是挂了,又起来了
tidb 需要和 pd 进行通信,这样子看上去是连不上 pd 了。把 pd 独立出来,在看下这个时间点的 topsql。
遇到过类似问题,可能是对应时间段有大sql或者批任务同时在跑,然后oom,后续可能sql执行结束或者失败了就又降下来了
应该是OOM了,排查下慢日志和tidb日志
看看日志
你这个配置有点意思, 几个tidb节点资源都不一样, 你要混合部署,至少也要挑资源高的机器啊
建议两台cpu64core的机器上scale-out pd节点