wfxxh
2024 年3 月 14 日 07:09
1
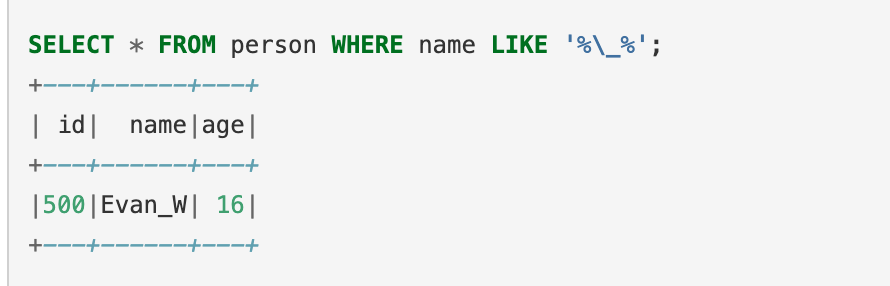
tispark版本:3.3_2.12-3.2.2select count(1) from zl.patent_element where class_code like 'H%' or class_code like '%\%H%';
这条语句用tispark查询会比用tidb直接查询少很多。
tispark执行计划:
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[], functions=[specialsum(count(1)#876L, LongType, 0)])
+- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=447]
+- HashAggregate(keys=[], functions=[partial_specialsum(count(1)#876L, LongType, 0)])
+- TiKV CoprocessorRDD{[table: patent_element] TableReader, Columns: class_code@VARCHAR(4294967295): { TableRangeScan: { RangeFilter: [], Range: [([t\200\000\000\000\000\000\r\311_r\000\000\000\000\000\000\000\000], [t\200\000\000\000\000\000\r\311_s\000\000\000\000\000\000\000\000])] }, Selection: [[[class_code@VARCHAR(4294967295) STARTS_WITH "H" reg: "H%"] OR [class_code@VARCHAR(4294967295) LIKE "%\%H%" reg: "%\%H%"]]], Aggregates: Count(1) }, startTs: 448371119139061761} EstimatedCount:131451015
tidb执行计划:
|HashAgg_13|1.00|root||funcs:count(Column#61)->Column#60|
|---|---|---|---|---|
|└─TableReader_14|1.00|root||data:HashAgg_6|
| └─HashAgg_6|1.00|cop[tikv]||funcs:count(1)->Column#61|
| └─Selection_12|126192974.40|cop[tikv]||or(like(zl.patent_element.class_code, H%, 92), like(zl.patent_element.class_code, %\%H%, 92))|
| └─TableFullScan_11|131451015.00|cop[tikv]|table:patent_element|keep order:false|
WalterWj
2024 年3 月 14 日 07:28
2
确保 “验证了转义规则” 是正确的。MySQL :
SELECT COUNT(1) FROM zl.patent_element WHERE class_code LIKE 'H%' OR class_code LIKE '%\\H%'
对于 Spark SQL :
SELECT COUNT(1) FROM zl.patent_element WHERE class_code LIKE 'H%' OR class_code LIKE '%\\\\H%'
1 个赞
wfxxh
2024 年3 月 16 日 01:56
3
试过了,\ 、 \\ ,对于tispark数据始终和tidb直接查询的对不上
wfxxh
2024 年3 月 18 日 00:57
5
对不上。
| class_code |
| G01D13/22%H02K21/14 |
| H02K%B60K%G01D13 |
| G01H/4%B70K |
我的数据是这样用%分割的多个class_code,我想要把里面所有%拆分后的H开头的全部取出来,即第1条和第二条。 这里用tidb直接执行 where class_code like ‘H%’ or class_code like ‘%\%H%’ 查询可以,用tispark只能查出来第二条。虽然可以执行spark函数进行分割后过滤,但是我们其他同事并不熟悉spark函数,因此普适性不强。
WalterWj
2024 年3 月 20 日 03:25
6
首先,确保你的 Spark SQL 配置允许使用反斜杠作为转义字符。然后你可以在查询中这样使用:
sql
复制
SELECT * FROM tab WHERE c LIKE '%\\%%' ESCAPE '\\'
在上面的例子中,\\ 表示字面量的反斜杠(因为反斜杠需要被转义),\\%% 表示字符串中包含 % 的情况。
WalterWj
2024 年3 月 20 日 03:34
7
不过看了下。。。。 spark 3.0 官网,好像转义一个 \ 就行。哎https://spark.apache.org/docs/3.0.0/sql-ref-syntax-qry-select-like.html
推荐用
SELECT DISTINCT original_class_code
FROM (
SELECT explode(split(class_code, '%')) AS split_code, class_code AS original_class_code
FROM zl.patent_element
) AS exploded_table
WHERE split_code LIKE 'H%'
或者试试 regexp
SELECT class_code
FROM zl.patent_element
WHERE class_code REGEXP '(^H|%H)';
wfxxh
2024 年3 月 21 日 01:48
9
explode方法不行,我们其他同事不会spark函数,内置方法不具有普适性;我试试REGEXP
wfxxh
2024 年3 月 21 日 02:00
10
应该不是spark的问题,用spark jdbc方式执行结果是正确的。目测应该是tispark的问题。顺便问一句,tispark现在是不维护了吗?
WalterWj
2024 年3 月 21 日 03:36
11
维护,只是不做新功能了。我可以反馈这个问题,或者你这边去 github 上提 issue。
system
2024 年5 月 21 日 00:15
15
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。