业务背景
某省妇幼健康管理系统建设内容包括:妇幼健康信息数据库;妇幼健康信息采集系统、妇幼健康信息管理及分析系统;母子健康管理APP、妇幼健康管理与分析 APP 等 62 个功能模块。
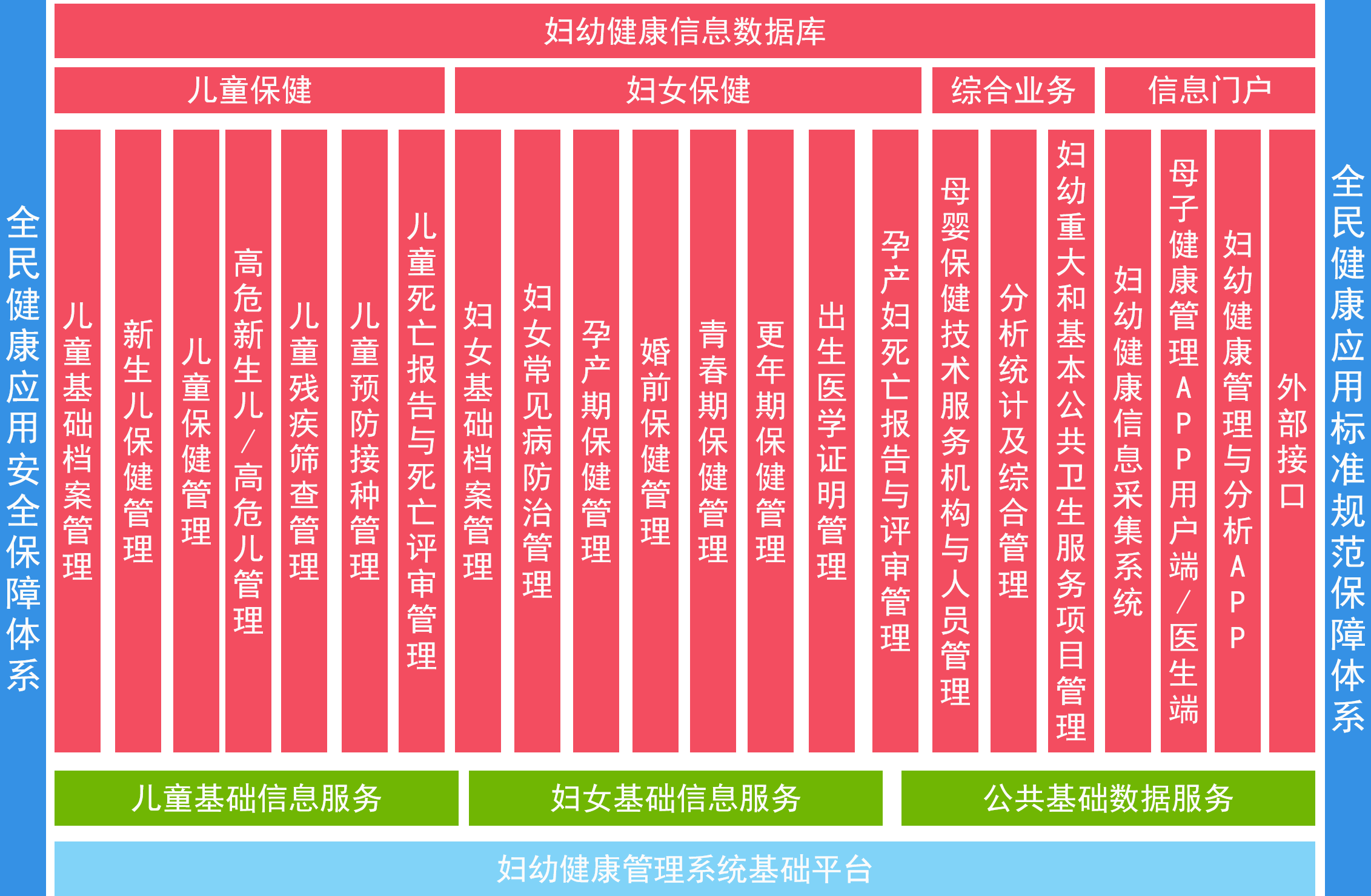
原有数据库架构
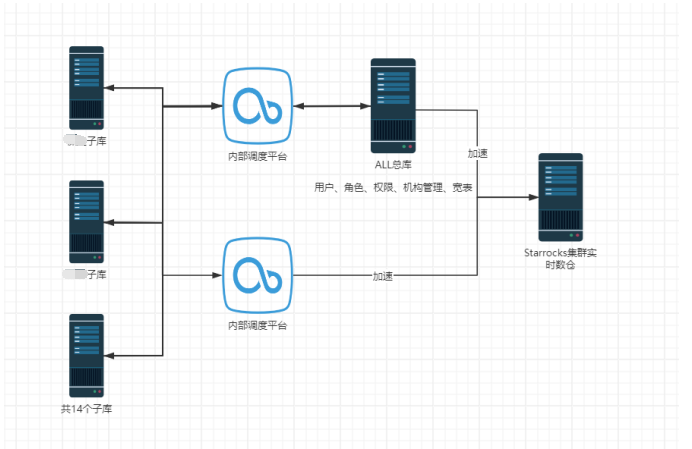
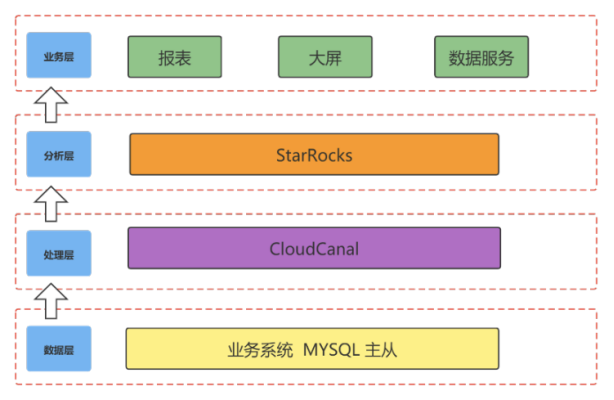
原有技术架构以及痛点
我们选择Starrocks 作为分析层,通过 DataX + CloudCanal 的模式实现实时+离线数据同步。随着业务的迭代,这套架构不太适应妇幼业务的发展需要。
架构总体上分为四块,自底向上分别是:
- 数据层:源端数据源主要是 MySQL 为主的关系型数据库。分别搭建5套(10台)主从分别承接14个子库和1个总库 mysql子库700+表。
- 处理层:使用CloudCanal+datax进行实时和离线的数据同步。
离线:将报表、大屏、数据交换服务采用离线方式构建 DM 主题数据集市。使用到的就是Datax 工具结合实现。
- 实时:使用CloudCanal 将MySQL 数据1:1同步到 Starrocks 中。
- 分析层:分析层会保存计算好的指标数据以及用于加速查询的中间结果数据。
- 使用3台32C128G搭建SR集群,分别对应 报表业务、大屏业务、数据交换服务、数据查询加速。
- 痛点:
- 业务变动频繁:开始为了满足业务需求每周至少2次数据库结构变更,经与事业部协商后控制在每周一次变更。变更需要DBA对14个地市mysql 、Starrocks 以及数据调度进行调整。
- 服务器资源浪费:Mysql出于数据安全的考虑是主从架构,从库资源没有得到有效利用。
- 业务更新对业务的影响:应用层面使用微服务架构,涉及到的研发人员较多,研发人员只关注自己的业务模块,通过sql审计平台提交ddl语句,最后由DBA执行,DBA对业务并不熟悉,无法检查ddl语句是否符合实际业务需求。造成平台发布后第二天会出现异常频发的情况(测试环境无法复现的一些问题)。
- 研发与DBA人员对sql调优技能无法得到提高:由于mysql数据1:1打到Starrocks中,复杂查询全部用MPP替代,在sql调优,数据表合理拆分方面不再关注(以前感觉这是个好事情,提高研发人员效率),这个问题会在MPP瓶颈后统一爆发,只能通过升级服务器配置解决。无法从根本上解决问题。
- DBA感觉很吃力:这个架构有点废人,按照一周一次的频率,DBA会在晚上6点后业务低峰期进行ddl操作,DBA需要维护30套数据库,近20000张表。操作完之后,发布程序然后测试再跟进。已经到半夜,如果出现问题在回滚操作,对业务影响较大。
- 数据库按照地市分割对于跨市的业务服务不能很好兼容、如报表只能通过打宽表做数据库汇总后展示(宽表越来越多)以及出现重复档案、跨地市不能查询服务记录等。
- 无法应用自动化数据库审计平台,数据库分散操作复杂,自动化实现难度高。
基于以上的痛点我们在寻找一个更优的技术架构……
数据库合并
| 表合计 | 过10万的表数量 | 过100万的表数量 | 过1000万的表数量 |
| 792 | 156 | 58 | 5 |
寻找一个数据库解决在数据库合并后写入和Online-ddl操作得到保证。
先后测试过Polardb、tidb、OceanBase 最终 选择了Tidb
tidb特点
- 高度兼容 MySQL,大多数情况下无需修改代码即可从 MySQL 轻松迁移至 TiDB,即使已经分库分表的 MySQL 集群亦可通过 TiDB 提供的迁移工具进行实时迁移。
- 水平弹性扩展,通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
- 分布式事务,TiDB 100% 支持标准的 ACID 事务。
- 真正金融级高可用,相比于传统主从(M-S)复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复(auto-failover),无需人工介入。
Tidb数据库架构介绍
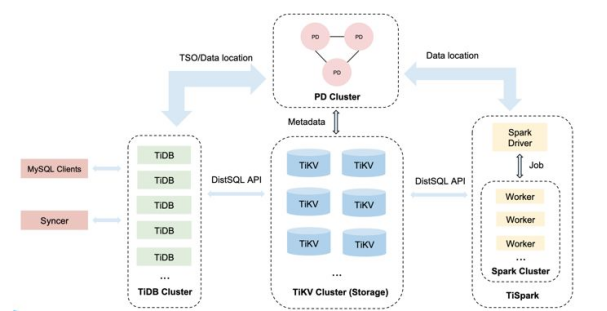
技术架构

新数据库架构
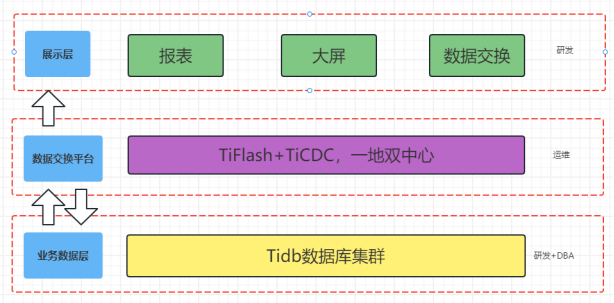
新架构层次划分去掉了Starrocks分析层,发挥Tidb的TiFlash组件OLAP功能,数据交换使用CloudCanal,分析层和业务层进行合并,业务即宽表,统一通过Tifalsh进行加速,在运维成本,业务扩展上也带来了极大的提升。
引入 yearning 自动化sql审计平台
Yearning 拥有以下功能:
-
自动化SQL语句审核,可对SQL进行自动检测并执行
-
DDL/DML语句执行后自动生成回滚语句
-
审核/查询 审计功能
-
支持LDAP登录/钉钉及邮件消息推送
-
支持自定义审核工作流
-
支持细粒度权限分配
-
-
“后续有专项培训讲解数据库审计平台”
关于sql优化

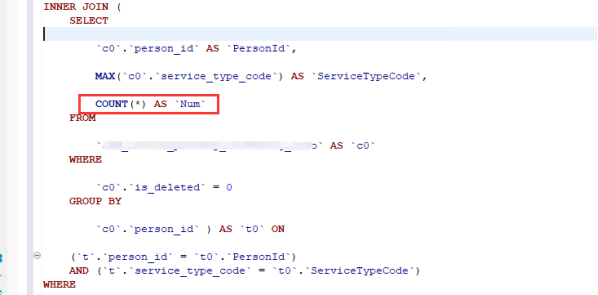
dba对监测慢语句逐一记录跟踪反馈与持续优化
分析层改造后收益
将Starrocks替换为Tifalsh后,整体查询效率(对比按地市分库的Starrocks)没有明显提升。通过sql优化后基本符合预期。
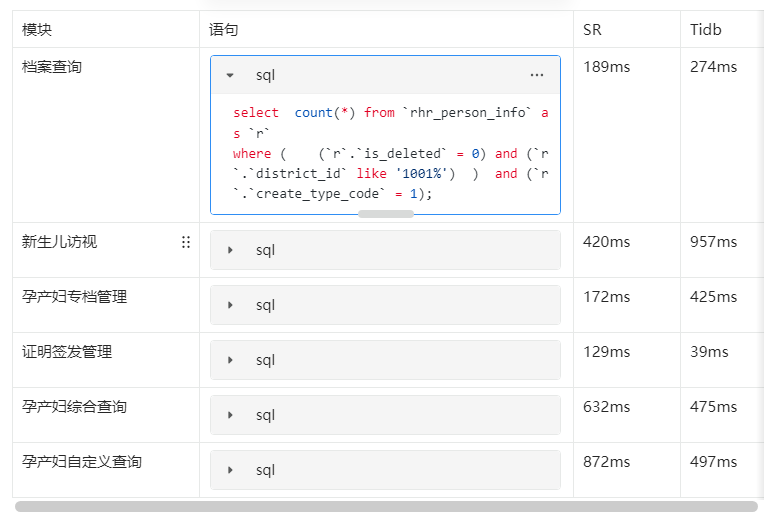
Tidb 和Starrocks 几个常用查询效果对比(数据量和结构相同)
查询响应时间比较(受限于编辑器sql贴的图片)
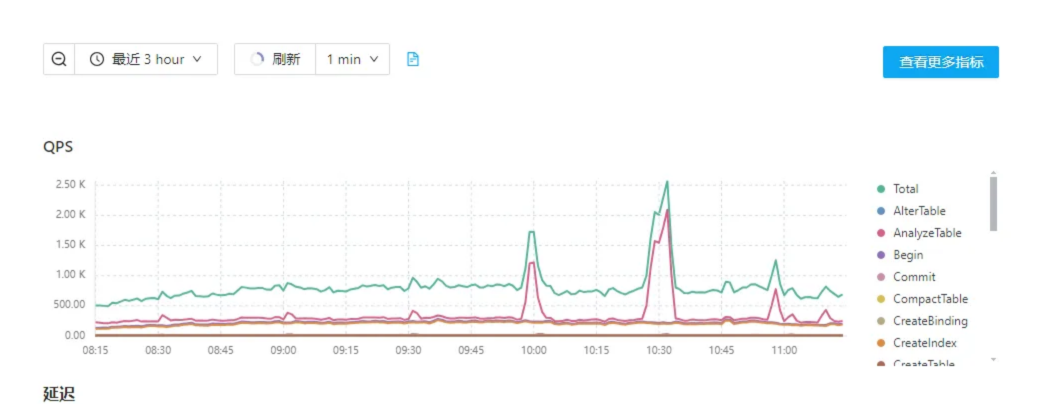
自带监控 tidb Dashboard
QPS
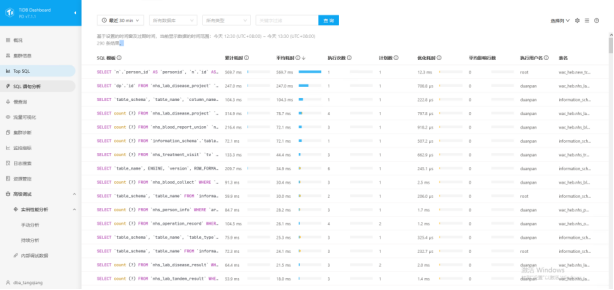
SQL 语句分析
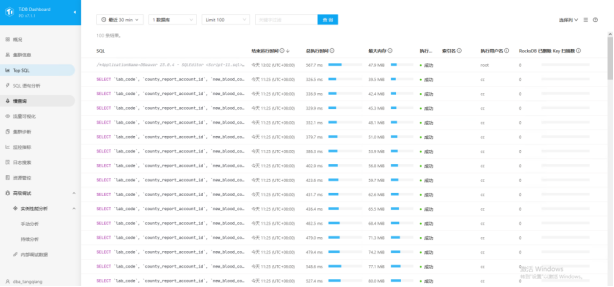
慢查询
流量可视化
删库、删表恢复
示例
- 恢复被 DROP 删除的 test 数据库:DROP DATABASE test;FLASHBACK DATABASE test;
- 恢复被 DROP 删除的 test 数据库并重命名为 test1:DROP DATABASE test;FLASHBACK DATABASE test TO test1;
--恢复删除表示例
- 恢复被 DROP 删除的表数据:DROP TABLE t;FLASHBACK TABLE t;
- 恢复被 TRUNCATE 的表数据,由于被 TRUNCATE 的表还存在,所以需要重命名被恢复的表,否则会报错表 t 已存在。TRUNCATE TABLE t;FLASHBACK TABLE t TO t1;
备份/还原应用超乎预期
Tidb 提供了BR集群快照备份功能,直接将日志备份到MinIO中。目前某省妇幼一天两次快照0时、12时,由于备份受限于存储,目前只能保留一天内的快照也未做日志备份。(全量快照+实时日志备份)可保证数据不丢失。BR还原数据超乎预期,300G数据还原用时20分钟(v7.1.3),官方最新版本v7.6最新版本BR还原能力提升10倍。
一地两中心的尝鲜(银行业务:至少两地三中心)
考虑到妇幼数据的重要性,在政务云实施搭建一地两中心,通过TiCDC实现主库集群实时将数据写入到从集群,同时从集群担负报表业务以及研发测试库环境。
pt-kill应用针对捕获正在运行中的SELECT|ALTER等DML/DDL消耗资源过多的查询,过滤它们,然后杀死它们(可选择不杀)且发邮件/微信报警给DBA和相关开发知悉,避免因慢SQL执行时间过长对数据库造成一定程度的伤害。
https://github.com/hcymysql/pt-kill
后台运行
shell> nohup php pt-kill.php -u username -p pwd -h 10.10.159.0 -P 3306 -B 10 -I 15 --match-info=‘select|alter’ --match-user=‘dbuser’ --kill --mail --weixin --daemon 1 &
杀死的慢语句会在后台日志文件中进行保留,下一步要对sql进行优化。
新架构效果说明
服务器资源合理利用
| 对比 | 数据层 | 处理层 | 分析层 |
| 原架构 | 10台 | 2台 | 3台 |
| 新架构 | 11台 | 1台 | 0台 |
人力成本的释放
原架构在数据层和处理层DBA人员根据发布周期对数据库进行ddl操作以及调整和调度。新架构省去了调度的维护工作同时引入sql审计平台可实现自动化ddl。但是DBA同时需要更加关注Tidb的各项指标。
运维成本的降低
Tidb部署不需要大数据组件的支撑,部署运维都很简单。Tidb兼容Mysql生态,业务使用可直接使用Mysql JDBC 进行连接,不用再担心SQL语法差异问题,原来mysql主从架构和sr集群以及调度任务运维工作都可以省掉。
未来规划
目前我们有两套数据架构 mysql+starrocks 和Tidb 这两套架构各有优势(也可以结合使用),结合事业部需求,根据不同业务线需求去确定使用哪套架构。