【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.5.8
【遇到的问题:问题现象及影响】TIDB 在模糊查询场景是否也能用到计算下推特性,例如:
select col1,col2 from tab where col3=xxx and col4 like ‘%aaaa%’ order by col5 asc,这种前后百分号的模糊查询,经过测试发现【执行计划TableRangeScan在万row的量级】,TIDB执行时间确实没有比原生MySQL有明显提升,哪位大神遇到过么?
数据量很大tikv数量多,tidb才有明显优势
TiDB的最佳使用场景是有比较大数据量的系统,通常是千万行、亿行以上的,数据规模在TB级别。如果是MySQL 单机能解决的场景,可以就考虑用MySQL
1 个赞
嗯,分布式需要大数据量,不能通吃
从行检索看是在百万行左右,但是性能这块与MySQL差异不大 ![]()
我看到官方文档了,但是LIKE模糊查询也分几个场景,估计前边没有%的场景加速会快些,如果前后%效果就不明显了
官方文档是支持的
![]() 有可能,不过还是要实践确认一下
有可能,不过还是要实践确认一下
真实测试了,效果提升不明显
刚试了一下,确实不支持,前边加百分号的场景不支持,右边加百分号的场景支持。看explain analyze的结果就不一样
咋测了半天成不能了呢,like 属于比较常见的了,应该是可以的
像这种在TiKV上执行也需要全表扫描,这种还是挺适合下推到TiFlash上的。
1 个赞
嗯嗯,我也发现这个问题了
分几种模式,主流数据库应该表现都是一致的, %目标值 不会走索引,目标值% 能够走索引。
1 个赞
![]() 其实我们开发规范里都写了,尽量不用 like ‘%目标值’。
其实我们开发规范里都写了,尽量不用 like ‘%目标值’。
提前规避了,哈哈,对于这种模糊查询看来还是的用检索型数据库产品
![]() 能在应用层解决的,就不要麻烦DBA
能在应用层解决的,就不要麻烦DBA
咋没下推啊?
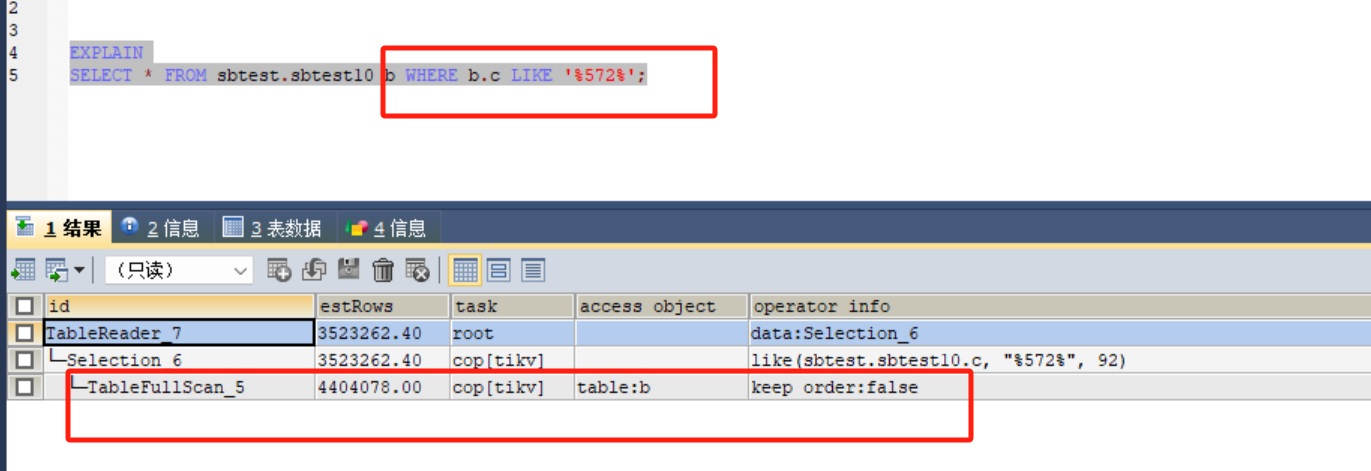
这不是下推到tikv去过滤了吗?
经过测试发现【执行计划TableRangeScan在万row的量级】,TIDB执行时间确实没有比原生MySQL有明显提升,
那肯定的了,万row量级的数据,在tidb估计也就1个region,tidb多个tikv节点的下推效果也体现不出来了,甚至加了tidb这层,效率还得下降。。。
你如果是亿row量级的数据,tikv节点很多,就能看出明显提升了
task字段里有cop[tikv]是代表索引下推了?