【 TiDB 使用环境】生产/开发/测试/ Pre
【 TiDB 版本】7.5.0
【复现路径】
sql.txt (3.6 KB)
【遇到的问题:问题现象及影响】
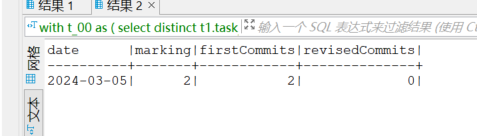
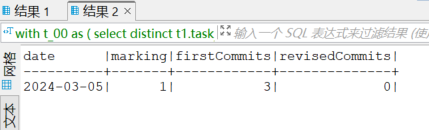
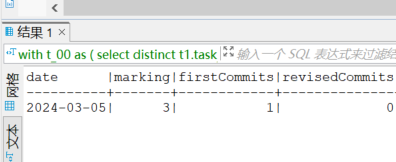
【执行计划】
_explain_analyze_with_t_00_as_select_distinct_t1_task_id_t2_anno_202403071456(1).csv (18.7 KB)
【 TiDB 使用环境】生产/开发/测试/ Pre
【 TiDB 版本】7.5.0
【复现路径】
sql.txt (3.6 KB)
【遇到的问题:问题现象及影响】
【执行计划】
_explain_analyze_with_t_00_as_select_distinct_t1_task_id_t2_anno_202403071456(1).csv (18.7 KB)
确定源头表没有变更吗?
你的查询嵌套太多层,建议一层层往上拆解,确认变化的源头。
比如第一步把最后的group语句改写成普通select。
不一致你能确定哪个是对的吗,数据有没有在变化
把这个sql和同样的数据放入mysql,对比测试下。如果和mysql的结果不一致,就给tidb提个bug,让他们查查。sql太复杂了。
是不是有表不是静态的
不能。这样吓人哩
这个逻辑一层又一层的,有点复杂…
可能一边操作,一遍有业务数据变化。
查询前开启一个事物试试在
数据在变吧 如果tidb有这种bug,那岂不是太低端了
SELECT COUNT(DISTINCT task_subject_id)
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY task_subject_id ORDER BY sub_create_time DESC) as rn
FROM
t_06
) t
WHERE rn = 1 and status = 1;
单独查询这一段,看看是是不是因为 sub_create_time 创建时间 和 status 状态,一直都在变化。
) AS marking,
COUNT(DISTINCT CASE WHEN tsl.annotate_type = 0 AND tsl.status = 2 THEN tsl.task_subject_id END) AS firstCommits,
COUNT(DISTINCT CASE WHEN tsl.annotate_type >= 1 AND tsl.status = 2 THEN tsl.task_subject_id END) AS
revisedCommits
FROM
t_06 tsl
WHERE
(tsl.status = 1 OR (tsl.annotate_type = 0 AND tsl.status = 2) OR (tsl.annotate_type >= 1 AND tsl.status = 2))
GROUP BY date
order by date;
这两个分类是不是 因为 status 数据状态变化,会产生数值 不一致
数据没有在变化
单独查询这一段,结果的值在0,1,2中随意跳。
task_subject_log表里的数据是没有变化的。只有11条数据,状态没有变化。
我现在怀疑是t_00中distinct的每次会筛选出不同的数据,导致结果的值不同
应该是变化了
cte的bug不少,我也遇到过union all后部分查询数据丢了问题
这应该是TIDB被黑的最惨的一次
提提bug看看
这样嵌套针对好么, 要不梳理一下逻辑, 改写下SQL,或许就不存在这个问题啦。
0,1,2,3
不加上status = 1 ,结果恒定为4