dba-kit
(张天师)
1
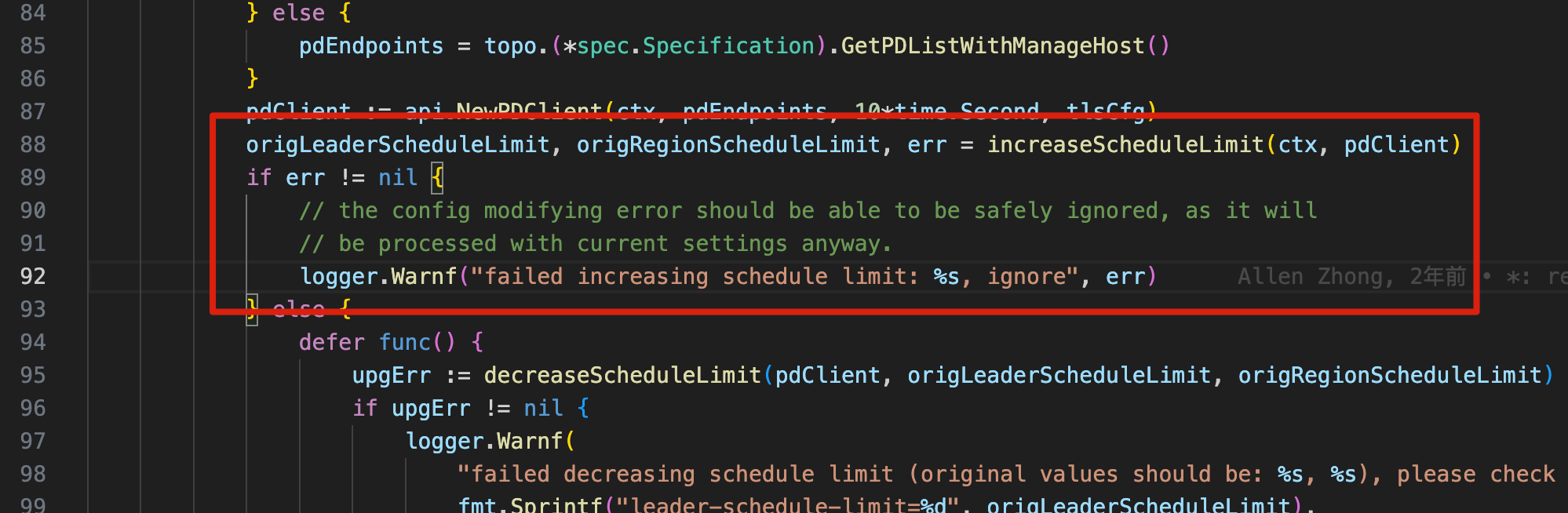
报错内容如下,虽然后续也会继续TiKV节点,但是不知道这里有没有继续重试修改schedule limit,我在测试环境是直接用的–force,并不会进行transfer-leader,所以看不到效果。
如果没有增加的话,会导致升级TiKV时间变长,增加升级的变更时间。
+ [ Serial ] - UpgradeCluster
Upgrading component pd
Restarting instance 172.30.240.10:2379
Restart instance 172.30.240.10:2379 success
Restarting instance 172.30.240.4:2379
Restart instance 172.30.240.4:2379 success
Restarting instance 172.30.240.12:2379
Restart instance 172.30.240.12:2379 success
Upgrading component tikv
failed increasing schedule limit: no endpoint available, the last err was: error requesting http://172.30.240.4:2379/pd/api/v1/config, response: redirect to not leader
, code 500, ignore
Restarting instance 172.30.240.3:20160
Restart instance 172.30.240.3:20160 success
dba-kit
(张天师)
2
看起来选择的pd节点后续又触发了重新选举,Leader切换到其他节点了。
dba-kit
(张天师)
3
自己翻了下代码,报错代码如下,在执行失败后,就只打日志,并没有重新尝试调整PD参数。
而
increaseScheduleLimit这个函数,会修改的PD参数只有下面两个,逻辑也很简单,当参数小于
LimitThreshold时,会尝试设置为
+offset。
- leader-schedule-limit:不超过64
- region-schedule-limit:不超过1024
leaderScheduleLimitOffset = 32
regionScheduleLimitOffset = 512
leaderScheduleLimitThreshold = 64
regionScheduleLimitThreshold = 1024
如果在生产升级时候遇到这个报错,又觉得transfter-leader太慢,想加快速度,可以通过pd-ctl手动调整一下这两个参数
1 个赞
Kongdom
(Kongdom)
4
1 个赞
我们也是,虽然TiDB提供在线升级,但是整个升级耗时还是挺久,我们是不到万不得已还是选择离线升级,简单快捷点,受影响时间短。
Kongdom
(Kongdom)
9
1 个赞
dba-kit
(张天师)
关闭
11
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。