【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.2
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
同样一个SQL在MySQL执行时间为0.7s
在tidb执行要1min+
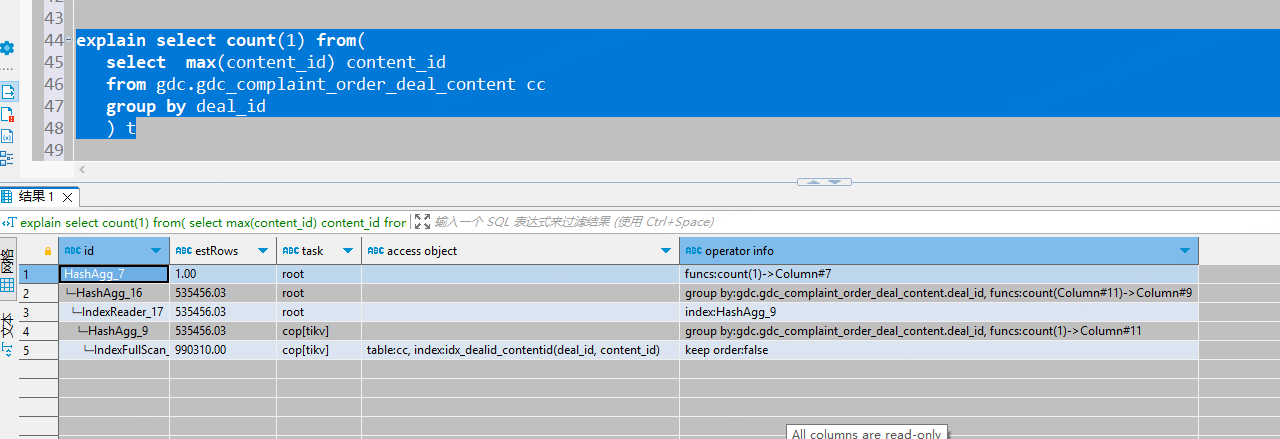
select count(1) from(
select max(content_id) content_id
from gdc.gdc_complaint_order_deal_content cc
group by deal_id
) t
tidb执行计划:
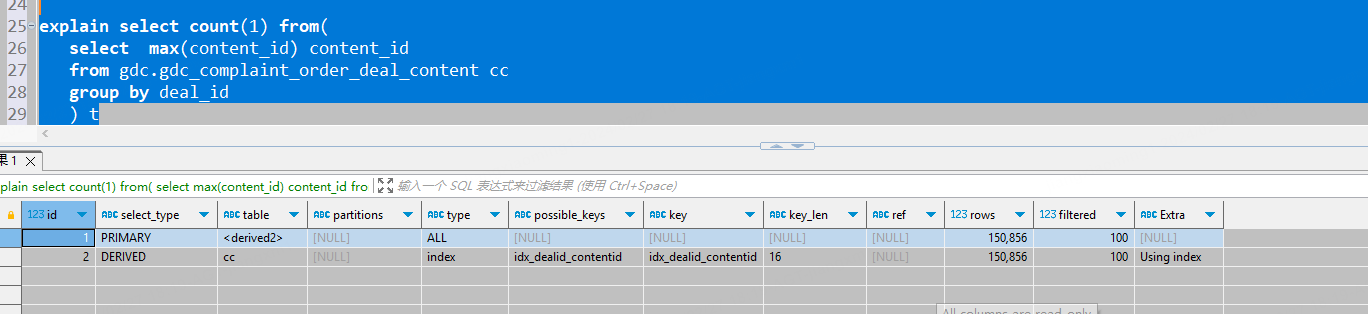
mysql执行计划:
【资源配置】
看下tikv资源使用情况。
count(1) 如果没索引就全表了,count(*) 会走主键索引等
你的资源配置什么样,磁盘什么类型。
多少条数据 0.7s
你看看这个表的DML非常是不是有点频繁,看看把应用停掉后怎么样
1 个赞
tidb跟mysql里面的数据量是一样的吗?
看两个执行计划的估算的rows好像差的有点多
Kongdom
(Kongdom)
8
建议使用tiflash组件,列存速度飞起。
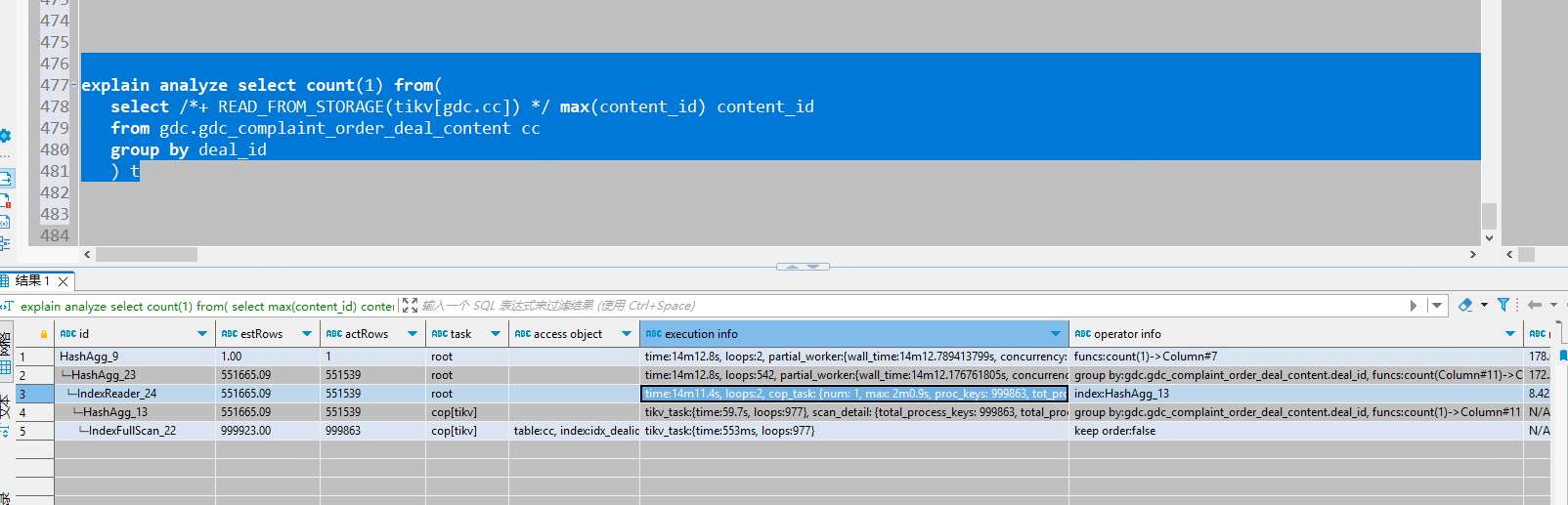
tidb的使用explain analyze替换explain试试
1 个赞
zhanggame1
(Ti D Ber G I13ecx U)
9
explain analyze看看扫描的key数量
changpeng75
(Ti D Ber Aw K Xsgx O)
10
tidb中和MySQL中数据一致吗?看到mysql中rows是150856,而tidb中是990310。
如果一致的话,analyze table 收集一下统计信息。
有猫万事足
11
当在tidb的执行计划中,看到整个计划的根是hashagg这个算子的时候,最佳的解决方案就是tiflash+mpp。
可以看到tidb执行这个sql的时候,是先到tikv上做了一次聚合,但因为数据是分布式存储的,每个tikv上聚合的结果不可避免的需要到tidb再聚合一次,没有办法像单机存储的情况那样,直接聚合一次就能得到结果。
你这个是适配tiflash场景的sql啊,加个tiflash节点,把gdc_complaint_order_deal_content 这个表设置一个tiflash副本,这个sql绝对快到飞起。。。
select count(distinct deal_id)
from gdc.gdc_complaint_order_deal_content cc;
sql是不是可以改成这样呢
设置tiflash确实快,但是tikv为啥慢那么多?感到不解
你用explain analyze看下执行计划,看看慢在哪里,我在写复杂sql的时候tidb会出现这种问题,就是group和max一起使用的时候
你用explain analyze执行下这个sql再贴下执行计划,这种其实就是olap类型的sql了,如果你没有content_id,deal_id联合索引会更慢,有也会对整个索引进行索引全扫描,sql首先下推到对应所有的tikv节点,将每个tikv节点上的deal_id对应最大的content_id拿出来,然后在tidb-server层面对所有tikv节点返回的deal_id对应最大的content_id汇总,如果有多个节点都返回了各自节点上同一个deal_id对应最大的content_id,这个时候需要再将这多条数据中选出同一个deal_id对应最大的content_id,最后才会返回出单个deal_id**对应最大的content_id,最后进行count汇总,肯定慢了。
dba远航
(Ti D Ber M Lo7 Bqhk)
18
看执行计划没有异常,应该explain analyze实际 执行一下看真实的执行计划如何
有猫万事足
19
你可以explain analyze 一下看看,具体这1分钟慢在哪里。