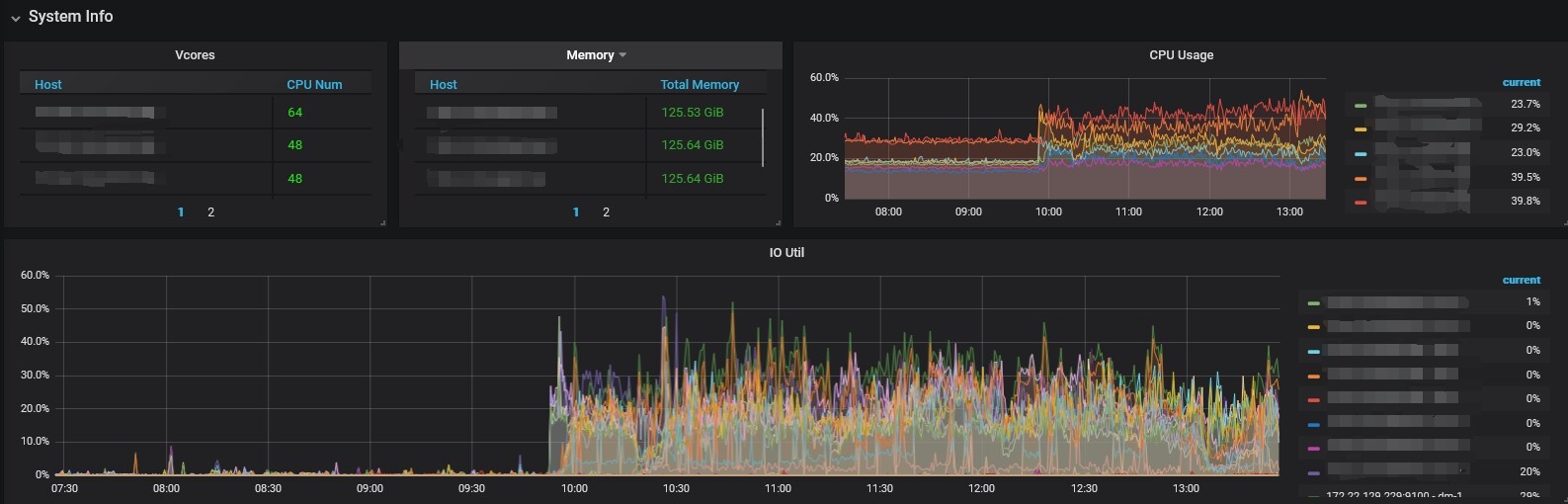
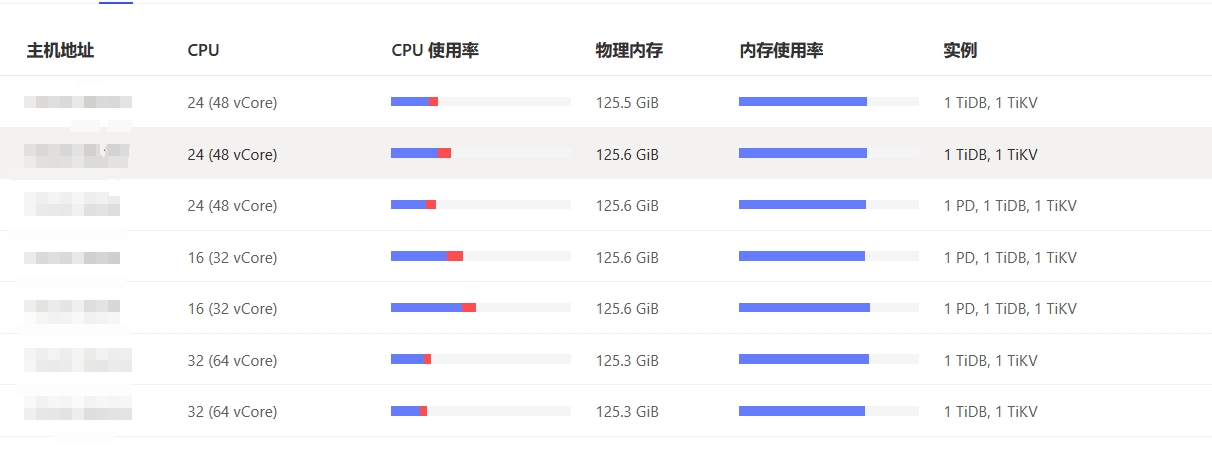
我有点不太理解,raftstore.store-pool-size目前设置为8,在什么都不做的情况下,raft store cpu在500%到600之间,Async apply cpu接近为0。
启动sqoop任务,Async apply cpu会上升,为什么raft store cpu会下降,这让我感觉tikv好像设置了整体资源使用的上限,没有充分发挥服务器性能。
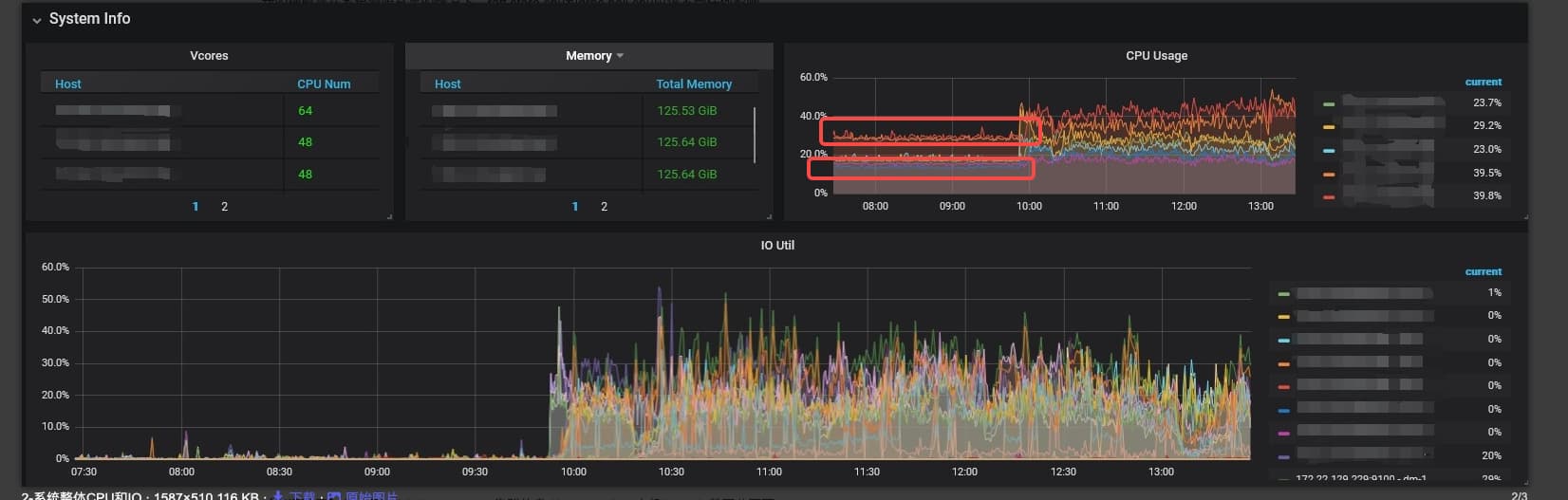
10 点前,你有 raft store cpu 和 grpc CPU。没有 schedule CPU,那么应该无写入。不确定你的业务模型。
比较奇怪的是,10 点后,你的 sqoop 任务应该启动了,这个时候可以看到 schedule cpu 上升,但是初始的时候不是很均衡,而且10.30,13.00 有不均衡的情况。这个代表有写入热点。关于写入热点你可以晚上看看材料进行优化。
你现在的问题我理解是为什么我整体 CPU 使用率下降了,但是 raft cpu 和 grpc CPU 缺下降了。
我觉得可能是因为 Sqoop 业务启动后,占用了一些资源,比如硬盘 IO 或者你的应用服务器或者你的网络资源。导致你以前的业务受到了影响,导致原先业务 A 给到的压力反而下降,导致你 grpc cpu 和 raft 的 cpu 有下降 。