在创建changefeed时,如果上游TiDB中的表没有主键和唯一索引,那么会提示是否忽略它们。changefeed创建以后,后续再创建的不兼容的表,不会被CDC同步到下游,会直接被忽略掉。那么有没有办法查询到后续哪些表被忽略掉了,除了去搜cdc的日志以外,有没有其它途径?
查看changefeed的配置,确认同步了哪些表,就知道其他的那些表被忽略掉了
cdc cli changefeed query --server=http://10.0.10.25:8300 --changefeed-id=simple-replication-task
直接在上游数据库查询哪些表没有主键和唯一索引不就行了
1.上游创建不会提示是否忽略,自动忽略。
2.查询一下没有主键和唯一非空索引的表,就是没有同步的。
3.建议开启主键参数,创建表必须有主键才能成功,可以避免不同步问题。
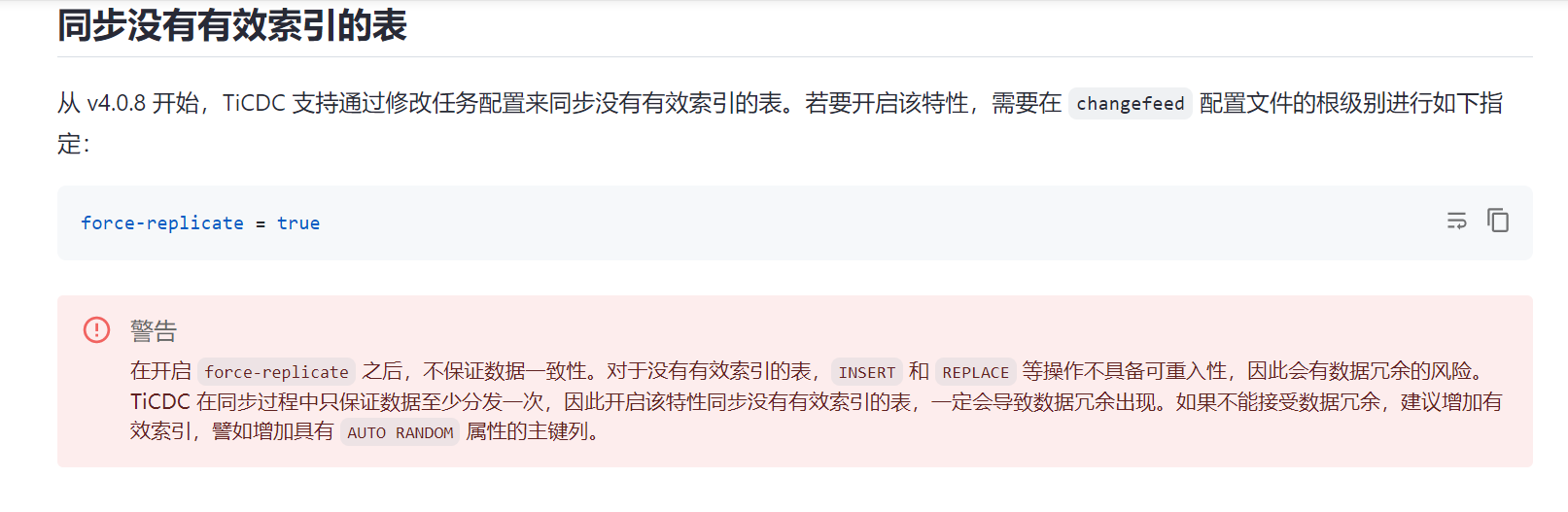
一些业务场景下,有些表确实不适合创建主键和唯一性(比如分区日志表),如果需要同步可以开启参数 force-replicate=true,来支持这些表
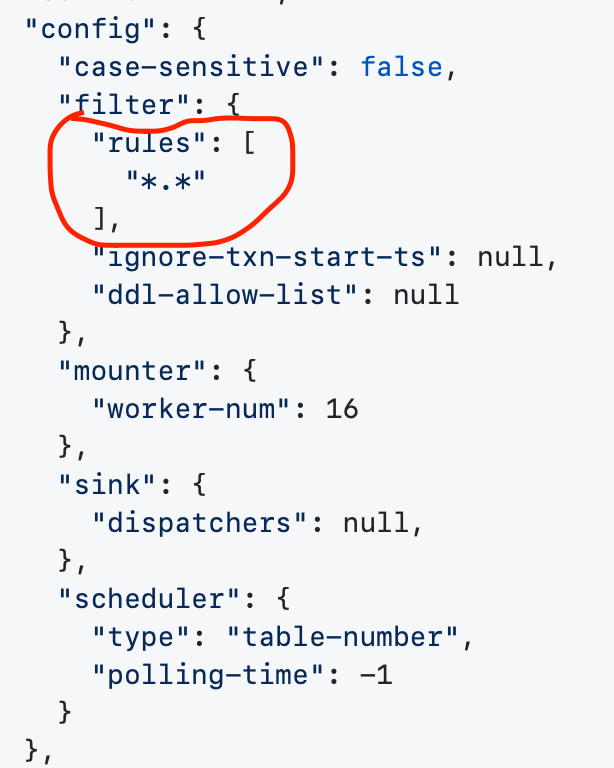
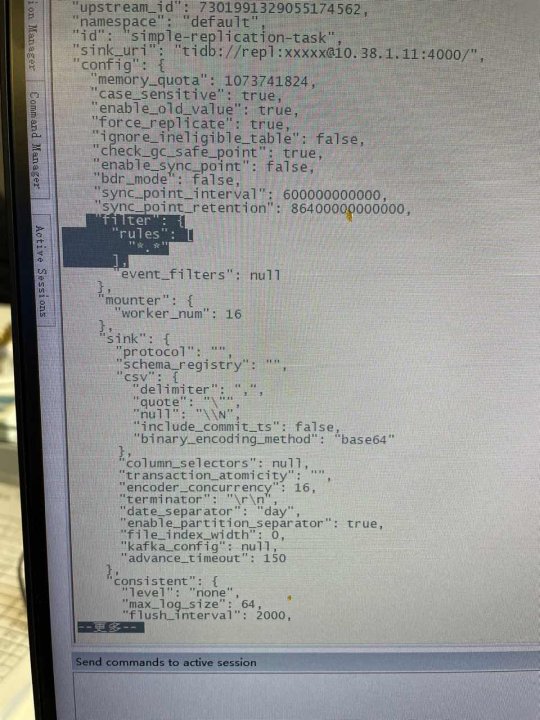
谢谢,关于过滤rules这里,想请教一下,我配置的是*.*,想连同mysql库一起复制到下游cdc,但是我发现在mysql库里面新建表,或者create user,都无法同步到下游,这里是什么原因呢?
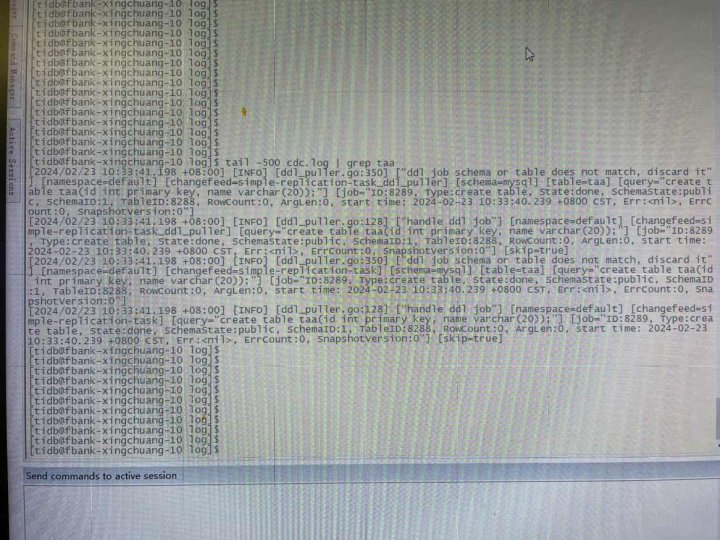
cdc日志里提示create table taa被discard了
谢谢,我试一下这个参数
直接在上游查询没有主键和唯一索引的表,无法区分是我在创建changefeed时主动忽略的表,还是changefeed运行起来后,它自动忽略的表
那在结合下你配置文件中的表对比下不就是自动忽略的表吗?不过cdc确实在创建的时候会提示类似信息让你确认,一般看到这个我都会确认下忽略有没有问题,没有问题我才会y确认。
[WARN] some tables are not eligible to replicate, []
v2.TableName{
v2.TableName{Schema:“tpcc”, Table:“history”, TableID:550, IsPartition:false},
v2.TableName{Schema:“citizencard-pay”, Table:“cc_merchant_bill”, TableID:827, IsPartition:false},
v2.TableName{Schema:“citizencard-pay”, Table:“cc_scan_pay”, TableID:831, IsPartition:false},
v2.TableName{Schema:“citizencard-biz”, Table:“cc_banking_outlets”, TableID:1260, IsPartition:false},
v2.TableName{Schema:“citizencard-biz”, Table:“cc_merchant_bill”, TableID:1272, IsPartition:false},
v2.TableName{Schema:“citizencard-biz”, Table:“cc_message_set_attr”, TableID:1278, IsPartition:false},
v2.TableName{Schema:“citizencard-biz”, Table:“cc_scan_pay”, TableID:1294, IsPartition:false},
v2.TableName{Schema:“citizencard-biz”, Table:“cc_t_robot_knowledge_20230216”, TableID:1300, IsPartition:false},
v2.TableName{Schema:“citizencard-biz”, Table:“cc_t_robot_knowledge_20230316”, TableID:1302, IsPartition:false},
v2.TableName{Schema:“citizencard-biz”, Table:“cc_banking_outlets_1228”, TableID:1622, IsPartition:false}}
嗯嗯,这个方式固然可行,但是从监控和运维角度来说风险还是蛮大的。比如你去年用CDC搭了一套异地灾备,跑了一年多忽然要做灾备切换,然后在TiDB备集群上一看少了很多表,那这些表是DBA主动忽略的,还是在这运行的一年时间里,应用程序或者研发自己建上去的,很难说清楚,而且这个提示信息只显示一次就没了,cdc的日志也可能被清理掉。
如果有API接口或者表视图什么的能查询或者监控这些被discard的表,那其实是能够在事前避免掉的

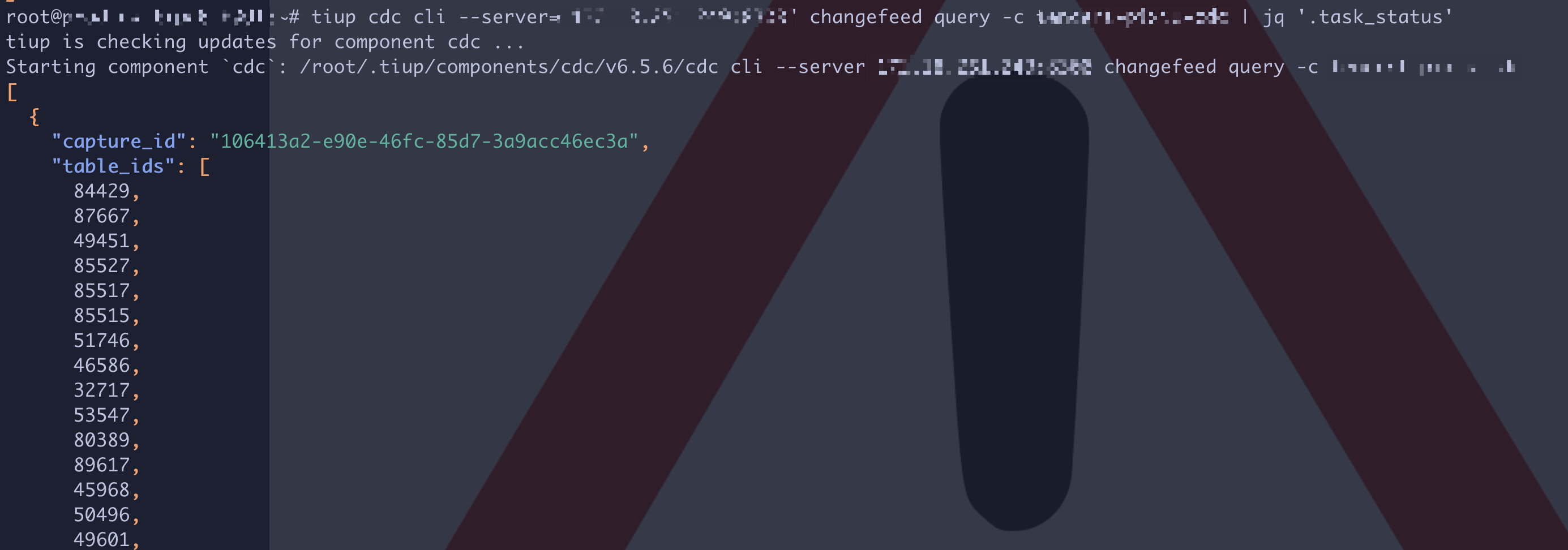
直接显示表名的没有,不过可以通过tiup cdc cli --server="" changefeed query -c changefeed-test | jq '.task_status'来获取已经同步的table_ids,再写个SHELL根据table_id获取对应的表名(select table_schema, table_name from information_schema.tables where tidb_table_id in (id1, id2,....);
如果想脚本化处理,可以考虑使用下TiCDC Open API来获取任务信息,下面两个API应该就够了:
1 个赞
这个是通过智谱清言AI生产的脚本代码,大概看了一下,应该还可行,可以试下
为了使用pymysql查询MySQL数据库,你首先需要安装这个库(如果你还没有安装的话):
pip install pymysql
以下是一个Python脚本的示例,它使用pymysql来执行构建的SQL查询,并打印查询结果:
import pymysql
import requests
# 获取所有同步子任务列表
url = "http://127.0.0.1:8300/api/v2/processors"
response = requests.get(url)
data = response.json()
# 解析所有同步子任务的信息
processors = data.get("items", [])
# 存储每个changefeed_id对应的table_id列表
table_id_mapping = {}
for processor in processors:
changefeed_id = processor.get("changefeed_id")
capture_id = processor.get("capture_id")
# 构建查询详细信息的URL
detail_url = f"http://127.0.0.1:8300/api/v2/processors/{changefeed_id}/{capture_id}"
detail_response = requests.get(detail_url)
detail_data = detail_response.json()
# 获取指定同步子任务的table_ids信息
table_ids = detail_data.get("table_ids", [])
# 将table_ids添加到对应的changefeed_id列表中
if changefeed_id not in table_id_mapping:
table_id_mapping[changefeed_id] = {}
for table_id in table_ids:
if table_id not in table_id_mapping[changefeed_id]:
table_id_mapping[changefeed_id][table_id] = []
table_id_mapping[changefeed_id][table_id].append(capture_id)
# 构建SQL查询
sql_query = ""
for changefeed_id, table_id_list in table_id_mapping.items():
for table_id in table_id_list:
if sql_query:
sql_query += ","
sql_query += f"'{table_id}'"
# 添加SQL查询
sql_query = f"SELECT table_schema, table_name FROM information_schema.tables WHERE tidb_table_id IN ({sql_query});"
# 打印SQL查询
print(sql_query)
# 连接到MySQL数据库
connection = pymysql.connect(host='localhost',
user='your_username',
password='your_password',
database='your_database',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
# 执行SQL查询
cursor.execute(sql_query)
# 获取查询结果
result = cursor.fetchall()
for row in result:
print(row)
finally:
connection.close()
在这个脚本中,你需要将your_username, your_password, your_database替换为你的MySQL数据库的实际登录凭证和数据库名称。此外,如果你的information_schema.tables表中的列名不是tidb_table_id,你需要根据实际情况调整SQL查询。
脚本首先构建一个包含所有table_id的SQL查询,然后执行这个查询并打印查询结果。注意,这个脚本使用了一个名为DictCursor的游标类型,它可以将结果集中的每一行转换为Python字典,使得访问列的属性更加方便。
请确保在运行这个脚本之前,你已经正确配置了MySQL数据库连接的凭证,并且数据库服务器正在运行且可访问。