TIDB6.x或者7.x单表中根据条件怎么快速删除超4亿的数据。之前5.x的版本是通过代码循环删除有些慢。
如果是全表删除可以使用truncate,如果是部分删除,如果留下数据部分很小,可以使用create table tab_name select * from table +过滤条件,然后删除旧表,重新命名新表。
2 个赞
你可以试下 ![]()
还是循环删除,注意循环不要用limit 10000这种,要不越删越慢,最好where条件加主键范围跑。
上面的说的新建表如果剩余数据也上亿那就别折腾了
1 个赞
所以在新版本还慢么?
哪个版本也慢,删除分2部分,1、查询要删除的数据 2、写入数据
数据量大了哪一步都慢
根据表的数据量大小来说,如果保留量和删除量(你要删除4亿条)差不多相当的话,就使用原来的方式删除,应该没啥可提高性能的。如果是保留的数据远小于删除量或者全部删除,可按2楼的方式处理
直接上脚本连接,复制不了

这个量级的删除,预计保留的数据量也不会小, 考虑直接dumpling加条件导出需要保留的数据,然后原表改名,新建表,利用tidb-lighning 导入
该表是时刻在写入数据,如果新建表的话会有部分数据丢失的
![]() 如果要删除4亿数据,那这个表很大啊。还是建议按主键分批删除好一点。
如果要删除4亿数据,那这个表很大啊。还是建议按主键分批删除好一点。
1 个赞
这样就只能用脚本循环删除了,其他办法不适用
这种一般建成分区表最好,直接truncate掉指定的分区,如果没建成分区,保留数据量很多的话建议先把对应条件的主键记录下来,然后分块并行删除,如果保留数据量小的话,建议业务暂停时通过rename表新建原表然后反插保留数据到原表。
1 个赞
你说的这个比较靠谱
参考 https://docs.pingcap.com/zh/tidb/stable/dev-guide-paginate-results 分批删,手动控制速度不要太快 (根据 GC 配置)
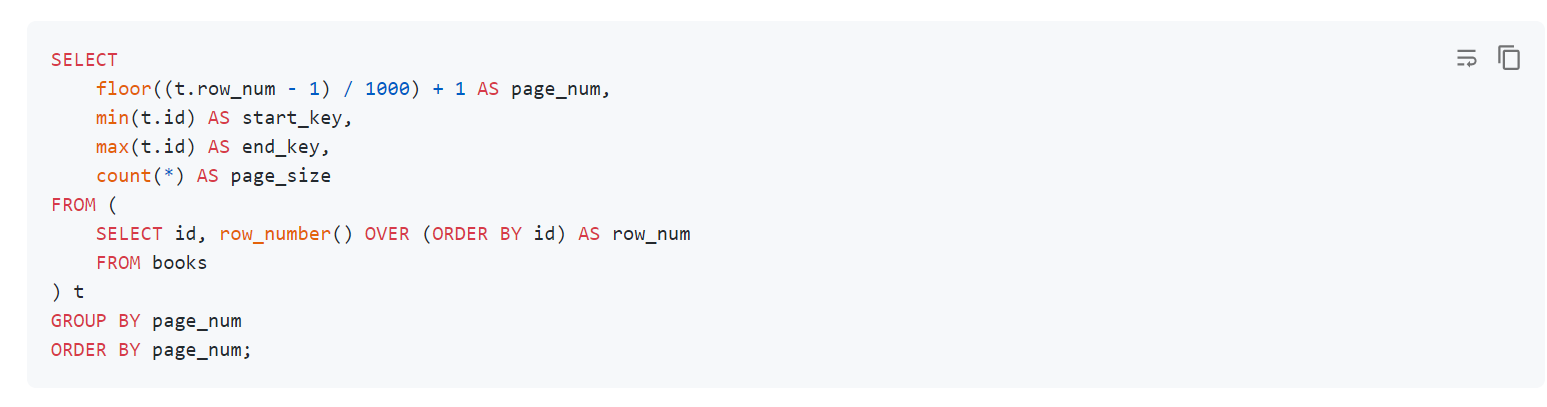
学习了
这种表是开始没有规划好, 如果表的历史数据需要定期清理,应该像 tidb菜鸟一只 说的建成分区表,然后过期数据直接drop partition即可。
要下决心改造,实在不行向业务申请停止服务一段时间,改造好了,以后就方便了
分区表有分区表的问题,tidb到下个版本分区表可能才好用点,我测试中遇到的问题多了