【 TiDB 使用环境】生产环境
【 TiDB 版本】7.1.0
从部署使用到现在有两年左右的时间,期间内存一直缓慢上升(可能是由于数据量一直在增长),期间每次超出k8s的内存限制就会更新配置,tikv节点会滚动重启,但是慢慢又达到临界值,请问这种情况是正常的吗?有没有什么办法可以控制?
配置文件:
tidb.yml (36.3 KB)
内存截图

tikv 配置下storage.block-cache.capacity 试试呢
好的,我试一下
可以考虑配置 20~30GB 试试。
1 个赞
tikv所在节点的内存是多少?节点上有其他服务吗?
1 个赞
限制并发、使用小事务、控制内存使用最大参数等等都可以试一下
1 个赞
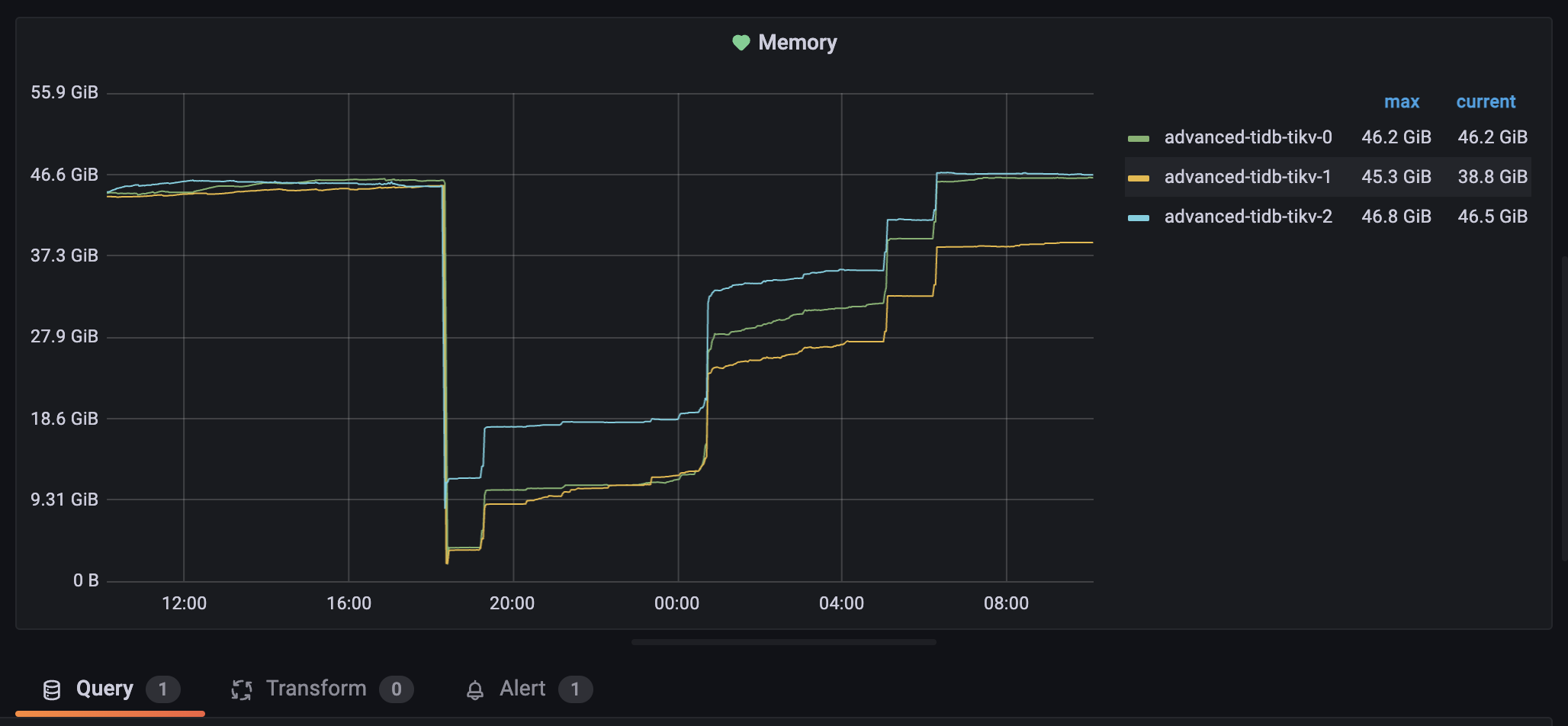
物理节点96g,节点上有k8s部署的其他服务
这些试试
memory-usage-limit = "40G"
[server]
grpc-memory-pool-quota = "1G"
[storage.block-cache]
capacity = "30GB"
[rocksdb]
max-total-wal-size = "2GB"
enable-statistics = false
[rocksdb.defaultcf]
write-buffer-size = "512MB"
max-write-buffer-number = 5
[rocksdb.writecf]
write-buffer-size = "512MB"
max-write-buffer-number = 5
[rocksdb.lockcf]
write-buffer-size = "512MB"
max-write-buffer-number = 5
[raftdb.defaultcf]
write-buffer-size = "128MB"
max-write-buffer-number = 5
[raft-engine]
memory-limit = "512MB"
节点内存使用情况正常吗
好的,我试一下
挺正常的,就是tikv这个pod总是缓慢增长,最后oom
查找你持续增长的原因。应该是有些操作没释放。如果一直增长,最后肯定是OOM了啊。内存毕竟有限。
storage.block-cache.capacity这个值设置为你认为tikv能占用的内存总量的45%,假如你96G物理机只跑tikv,设置40G我认为问题不大,但是如果上面跑的其他pod很多,建议设置再小一点。。。
突破很正常,这个配置推荐配置为你给 pod 的 limit mem 配置的 45% 左右,你给 40 肯定超。
这个是主要内存占用,tikv 还有其他内存占用。有一些 cache 和 gRpc 等通讯使用的内存占用。
tikv 如果集群写如比较多, 内存上升突破正常的, memory-usage-limit = 这个值设置为总内存的75%
share 下 kubectl -n default get tc advanced-tidb -oyaml 的输出,另外参考官网试下 (修改会滚动重启 TiKV)
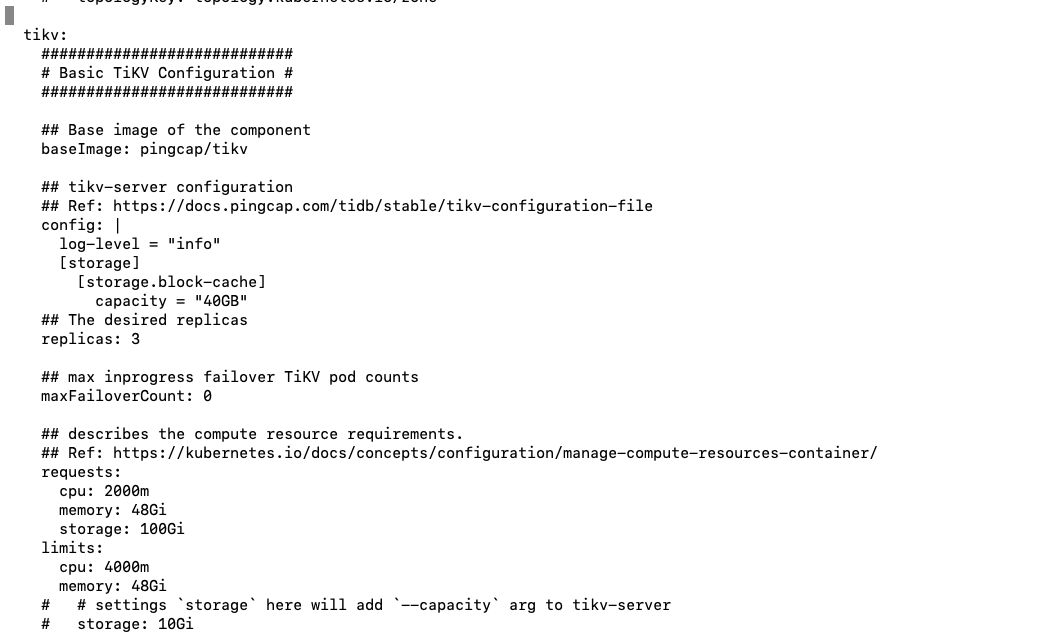
tikv:
requests:
cpu: "2000m"
memory: "48Gi"
storage: "100Gi"
limits:
cpu: "4000m"
memory: "48Gi"
好的好的,我试一下,谢谢!
好的,多谢