这个prometheus目录下数据过大,如何清理
可以按照时间把排序后,把不要的时间段的文件删除掉
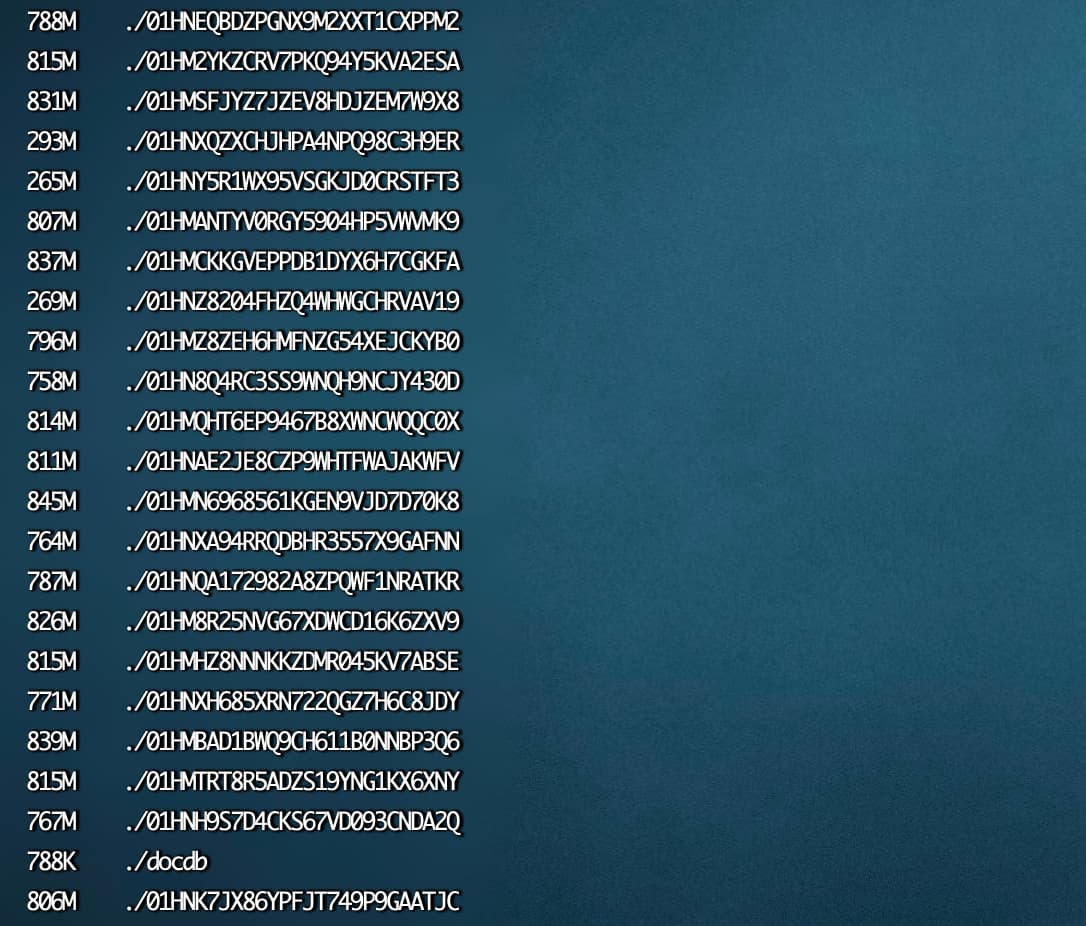
./prometheus-9092目录下面哪个文件夹占用空间大?
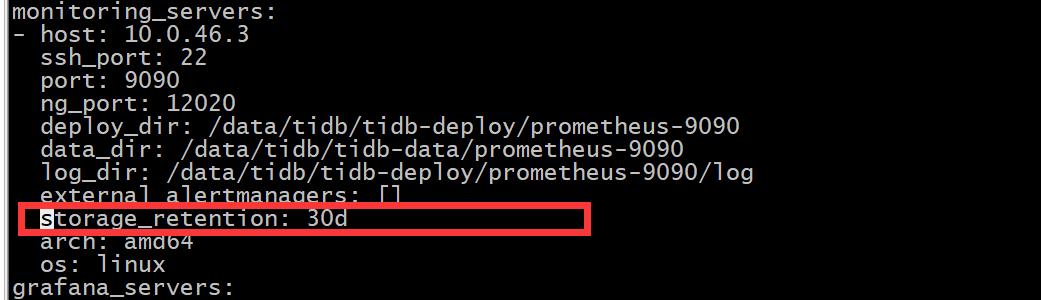
https://docs.pingcap.com/zh/tidb/stable/tiup-cluster-topology-reference#monitoring_servers 参考这里面有配置,设置storage_retention
storage_retention:Prometheus 监控数据保留时间,默认 “30d”
storage_retention 设置短点,会自动删除。如果数据不要也行,可以scale_in掉监控再scale_out
设置参数storage_retention ,如果不需要保留时间太长,可以把值设置小一些
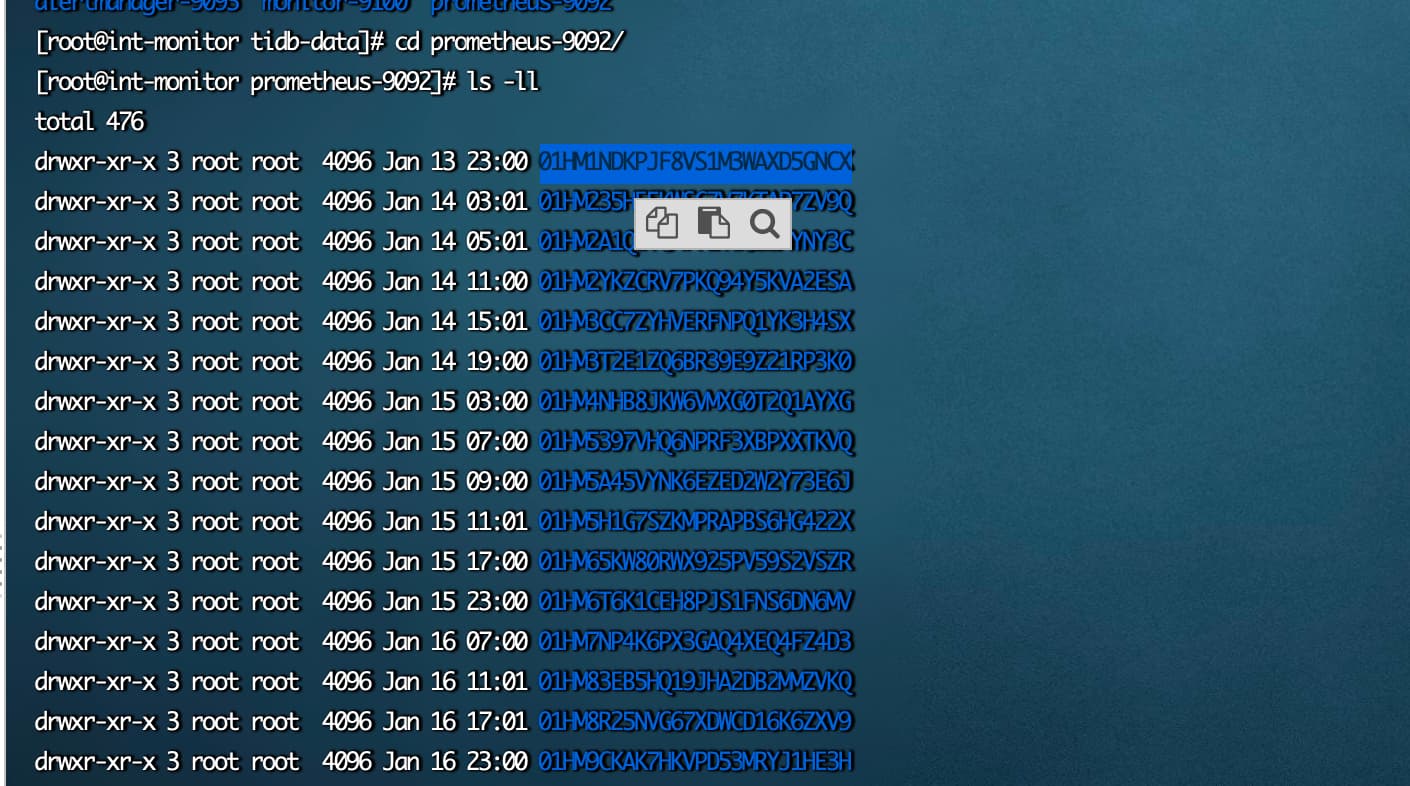
1、prometheus data 01开头的目录占用多,说明采集到的数据多,可以通过curl tidb/tikv/pd各组件的metrics接口, 看下返回行数。如果返回行数在数十万、百万行的话,确实不正常,这就需要抛弃掉一些metrics了。一般来讲tikv的metrics可能会异常,可以在 prometheus.yml文件 - job_name: "tikv"处最下方增加如下配置来减少数据采集,然后通过tiup 重启下prometheus。不过拓扑变更的话此配置会被回滚掉。
metric_relabel_configs:
2、如果wal多,可能是prometheus没有及时checkpoint, 一般是因为采集数据量大
可以在log/promethues.log日志文件过滤Starting TSDB …和TSDB started关键词,看prometheus是否经常重启。不过按照第1步操作的话会减少这种情况。
修改完,立即生效吗
应该是立即生效的
我们线上设置的是14天,保留两周的数据
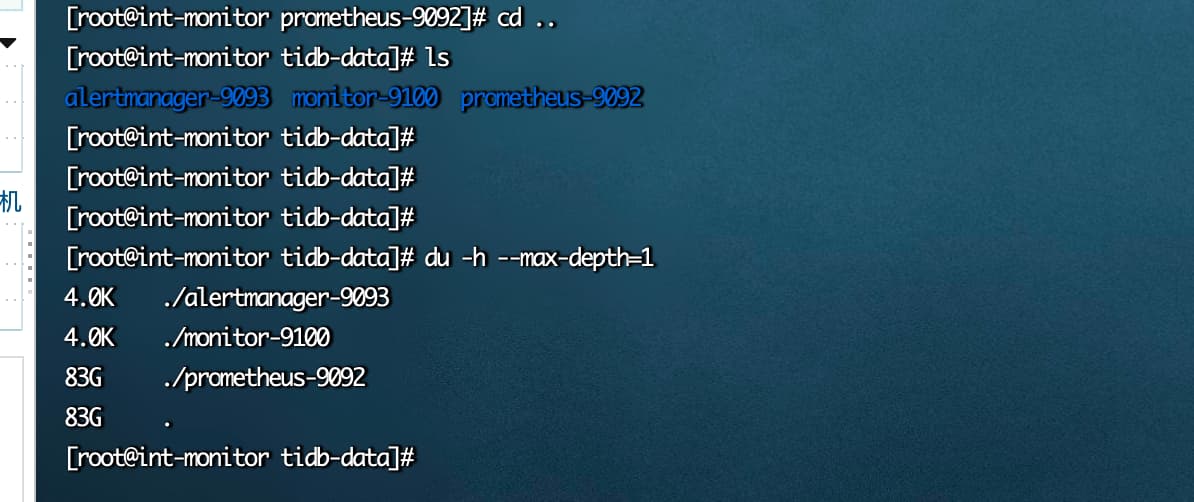
还好吧,才83G,默认保留30天,我们是保留90天,有时候需要查历史监控来排查问题,如果不需要这么多可以调小点
storage_retention 调整一下保留策略
自动清理异常,可以考虑先scale-in, 再scale-out
监控机的磁盘也太小了
之前我也发帖讨论过类似问题,最后因为其他事情忙丢一边没处理。
改参数调时间,重启promehteus
修改参数storage_retention
修改抓取周期,从原来的15秒修改成1分钟
修改保留策略。
至于Prometheus目录下的数据,我直接删过目录。从老的往新的删除,反正是监控数据,删除后如果有问题大不了从今天重新抓。
楼上说得对,应该从频率和保留时间两个方面考虑