dba-kit
2024 年2 月 19 日 09:59
1
查询SQL为:select count(1) from table_ch ch where ch.create_time >= '2024-01-01' and ch.create_time < '2024-02-01' and ch.capital_mode = '8' and ch.account_id != '';
测试案例
查询耗时
备注
6.5.80.707 s
7.5(local)0.855 s
7.5(s3) no-cache72.605 scache总数据量为5.6 G,最大S3下载速度为190 MB/s
7.5(s3) cached2.613 s
可以看到采取存算分离架构后,第一次查询速度会特别特别慢,看起来是卡在从S3下载数据的速度上。而当数据缓存到计算节点后,之后的查询会对比第一次快些,但是比local模式下要慢上个3倍左右。
有什么参数可以调整从S3下载的速度或者并发么?
为什么数据已经缓存到本地后,查询还是比普通模式要慢很多?
有没有什么办法,主动将某些表的数据一直缓存到本地?(重点保障某些表的查询效率,让其不至于衰减那么严重)cache.capacity的限制后,又被从cache里删掉。
dba-kit
2024 年2 月 19 日 10:04
2
还有另外一点,不知道为什么同样的查询6.5.8竟然比7.5.0还快一些,7.1不是有延时物化的优化么?理论上应该更快吧?
changpeng75
2024 年2 月 19 日 10:09
3
既然是从S3下载数据慢,问什么数据不存储在TiFlash节点上?
dba-kit
2024 年2 月 19 日 10:21
4
现在就是在测试TiFlash存算分离架构,看是否还有优化空间。如果真的是现在的效率,肯定会慎重考虑是否使用新架构的。
changpeng75
2024 年2 月 19 日 10:40
5
TiDB的存算架构中的TiKV/TiFlash就是‘存’,‘算’是TiDB Server,本身就是存算分离的架构。分布式系统本来就是多节点使用本地存储来达到高并发,但也有多副本带来的存储容量上升,廉价的本地存储可以抵消部分的成本。如果TiFlash这样的存储节点不使用本地存储,而通过网络去访问S3这样的对象存储,那么分布式的存储节点还有什么意义呢,直接用TiDB Server访问S3不是更好么?
dba-kit
2024 年2 月 19 日 10:46
6
你这么理解也是对的,但是如果TiDB能做到在S3上的访问效率和本地差不多,岂不是更好?
dba-kit
2024 年2 月 19 日 10:48
7
官方宣传的文章在这里,不是只有高性能OLTP场景,TiDB还有一些场景是用在AP类需求,这些场景下对查询耗时并不敏感,反而成本很重要。
changpeng75
2024 年2 月 19 日 10:52
8
考虑过成本没有?从原理角度出发,不可能做了额外的工作之后,效率比直接去做还要高,除非付出额外的代价。
changpeng75
2024 年2 月 19 日 10:54
9
OLAP如果对性能没有要求,就不会发展出列式数据库,也不会流式的即时OLAP了。
dba-kit
2024 年2 月 19 日 13:51
11
dba-kit:
7.1不是有延时物化的优化么
后面测试了下,当 set tidb_opt_enable_late_materialization=off;关闭延迟物化后,速度是0.926 s,反而和7.5本地盘TiFlash差不多了
dba-kit
2024 年2 月 19 日 13:54
12
另外还试了下,把storage.remote.cache.capacity设置为0,速度会比不为0的时候快很多,16s就结束了。应该是没有写本地磁盘,直接全部放到内存里导致的。
dba远航
2024 年2 月 20 日 00:30
13
最好 发一下执行计划,再就是表是否已经存储到tiflash
你不用这个本地缓存那不都得用内存了?这对tiflash节点机器的内存考验也太严重了吧。。。
dba-kit
2024 年2 月 20 日 06:17
15
额,并不是这个问题导致的,重新扩缩容+重新同步一次tiflash replica后,发现开/关延迟物化对查询Latency的影响很小,首次查询都是70多s,有缓存后第二次查询都是2s多。 等过了一段时间后(标志是监控面板中S3的读写请求消失 ),这个时候再查询,首次查询只需要16s,有缓存后第二次查询都是0.9s左右,多查几次后,甚至会变成0.7s。profiling-write-node-during-query.zip (95.4 KB)profiling-comput-node-during-query.zip (164.1 KB)
dba-kit
2024 年2 月 20 日 06:29
17
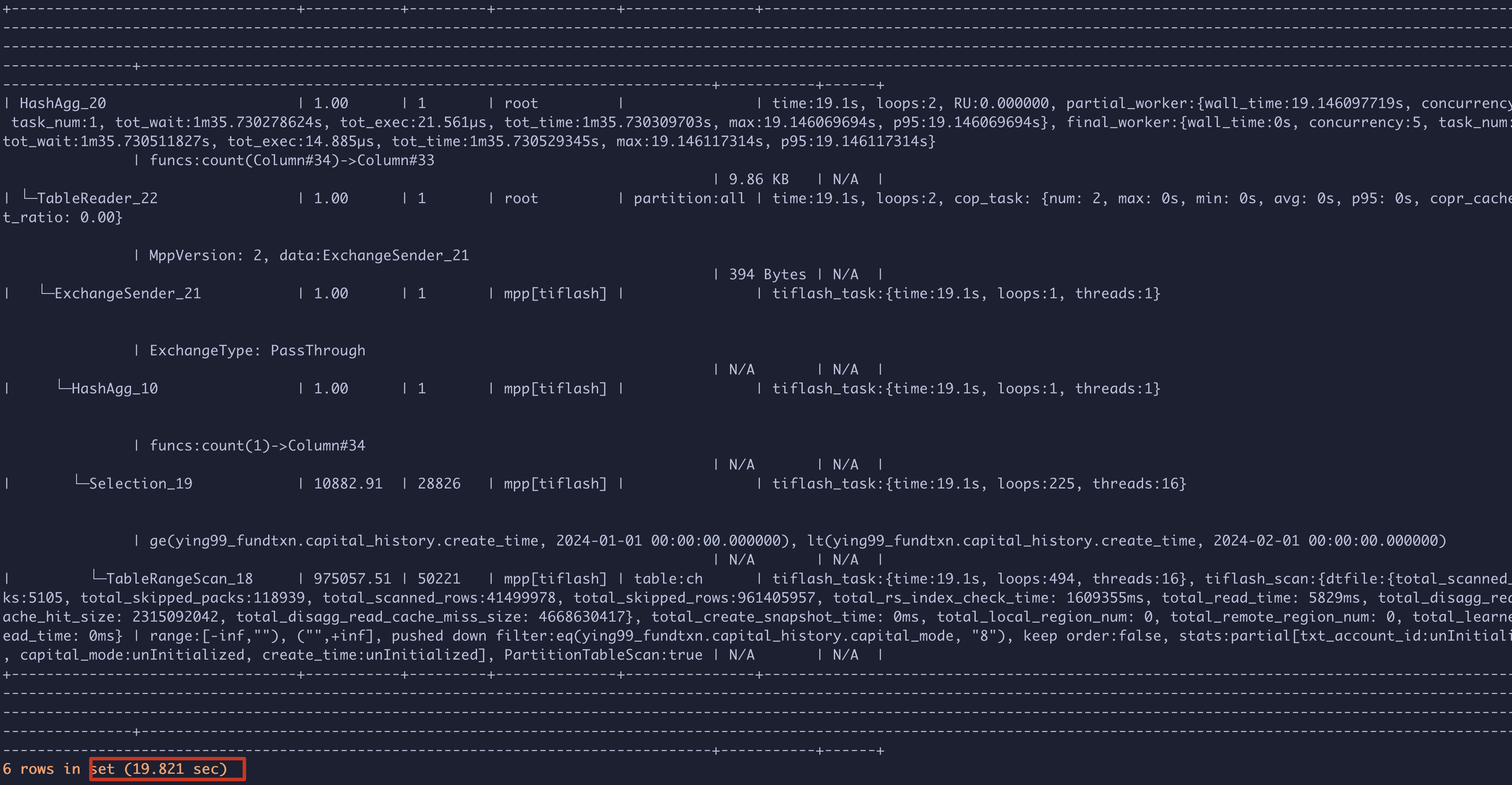
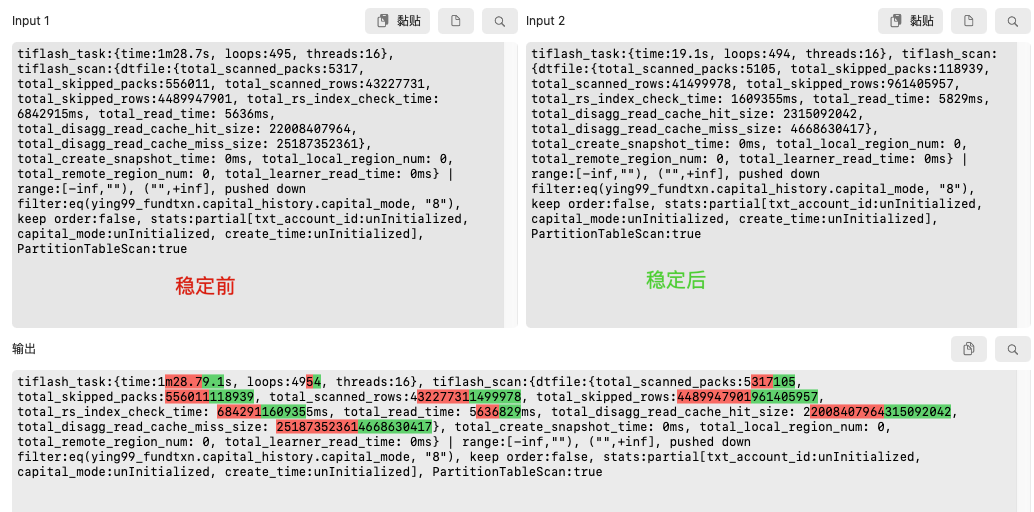
对比执行计划,发现稳定前
total_skipped_rows/total_skipped_packs是稳定后的5倍左右,而真正的
total_scanned_rows/total_scanned_packs差别不大。是因为刚增加tiflash replica后,文件碎片比较多导致的,因为看到即便tiflash replica已经可用后,tiflash即便在静态无数据写入的情况下,依旧会持续对S3进行读写,持续3、4个小时后,才会不对S3进行请求。
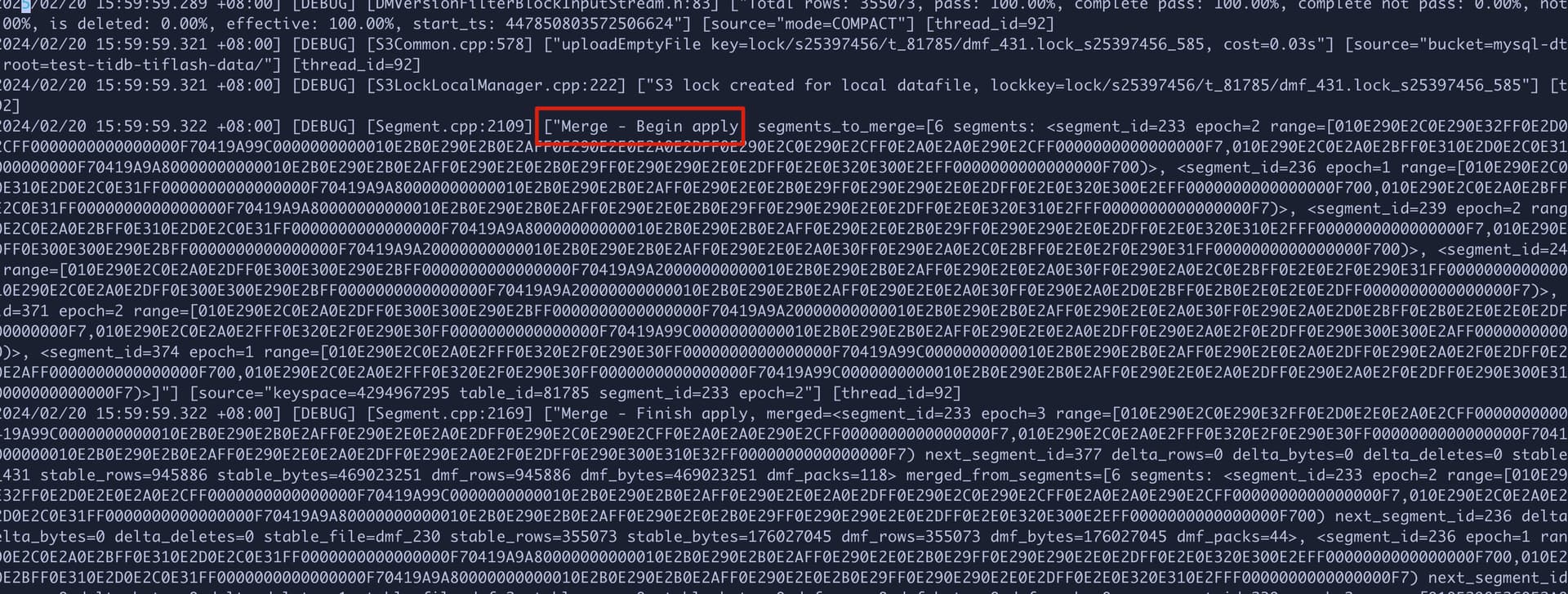
在查询稳定之前,tiflash wn 不断的在做 segment merge。所以可能是由于刚导入完成后 segment 太小有关系。具体原因还要再深入看看
1 个赞
dba-kit
2024 年2 月 20 日 14:16
19
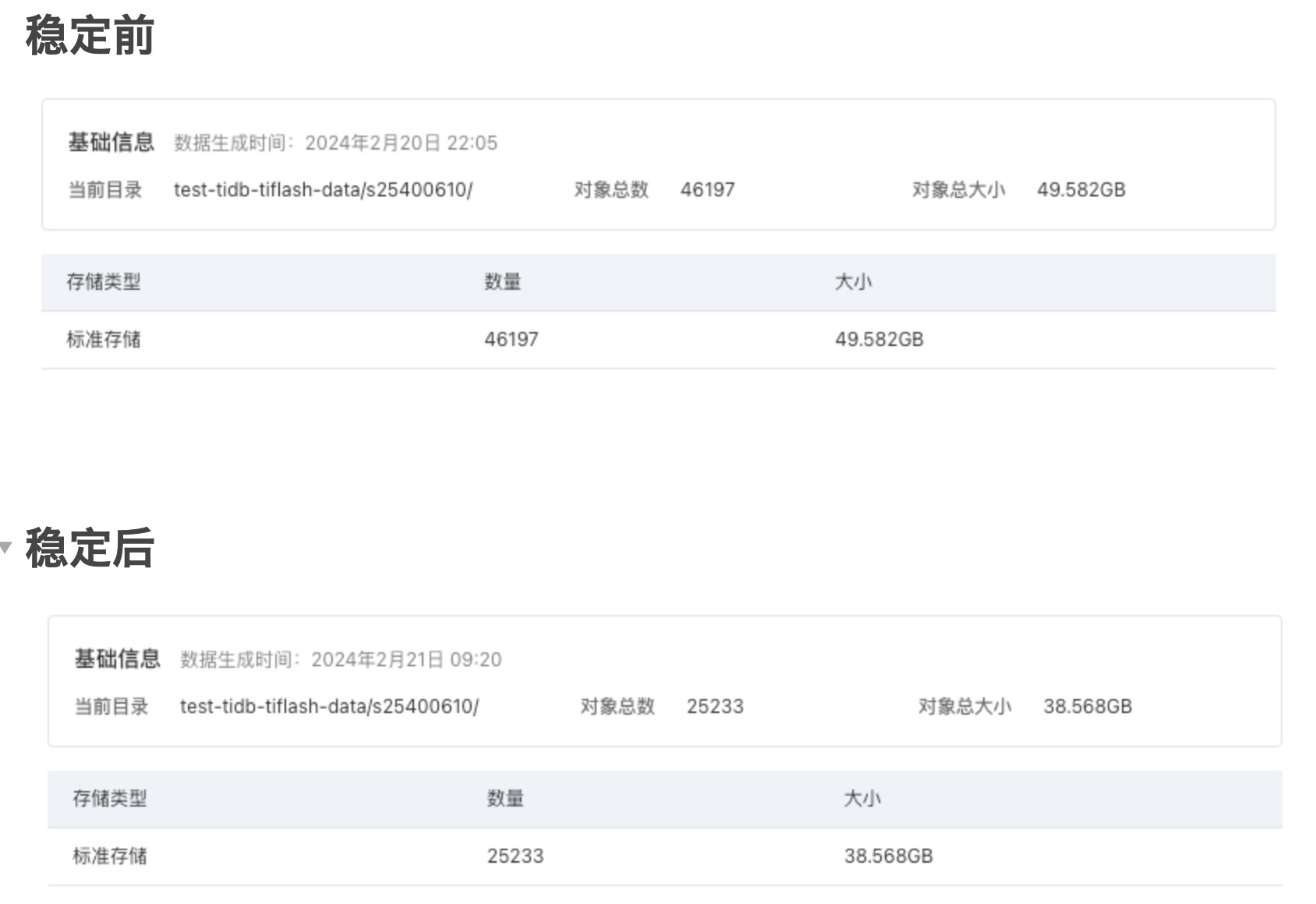
又重新扩缩容了一下write-node节点,确实差别挺大的,19:30所有副本都已经上传完毕了,经过3个小时的整理,看api请求已经删除了3次了,当前的object个数还是稳定后的1.78倍。