【 TiDB 使用环境】生产环境
4013
【复现路径】做过哪些操作出现的问题
其中一个节点的cpu比其三个节点cpu高
【遇到的问题:问题现象及影响】
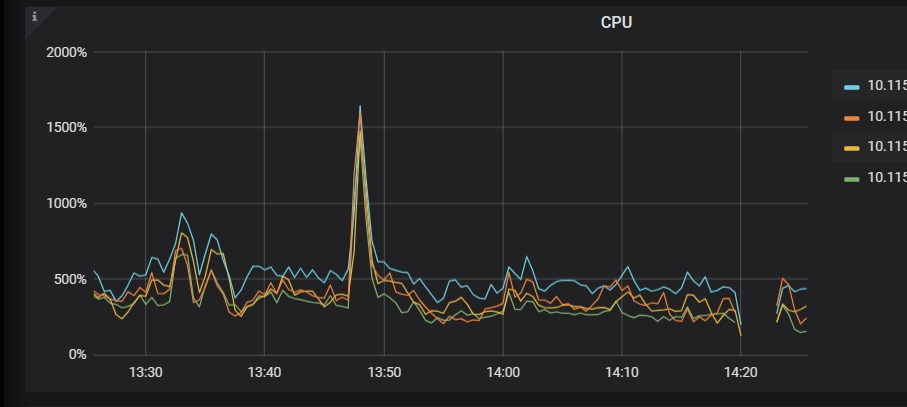
继续排查发现是.unified-readpool-cpu这一个高
【 TiDB 使用环境】生产环境
4013
【复现路径】做过哪些操作出现的问题
其中一个节点的cpu比其三个节点cpu高
【遇到的问题:问题现象及影响】
已经排查四个节点的cpu型号,核数,内存。磁盘类型都是一样的
而且这四个节点的leader数量和region数量几乎一样
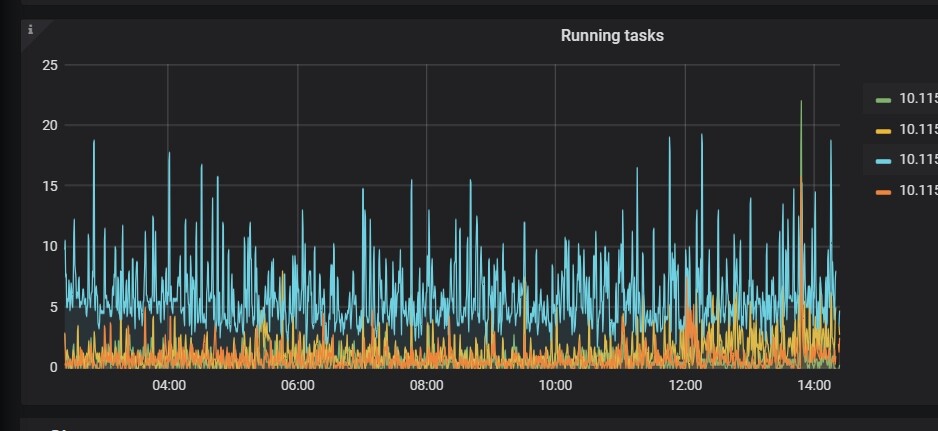
是不是相关业务查询的数据的leader正好在这个高的节点呢?
那不可能一直在这个节点啊,leader也会转移吧,我怀疑的那个running task导致的,但是那个task都有哪些,咋查啊
优化下慢SQL吧
unified-readpool-cpu这个就是你查的数据量大了,消耗的cpu就多,你看下leader和region在tikv上的分布情况呢?是不是cpu高的这个leader要多一点
整体cpu都不高,也没有啥特定时间的慢sql,慢sql都优化完了
热点有吗,对应热点表看下region的leader是不是都在这台高cpu节点上
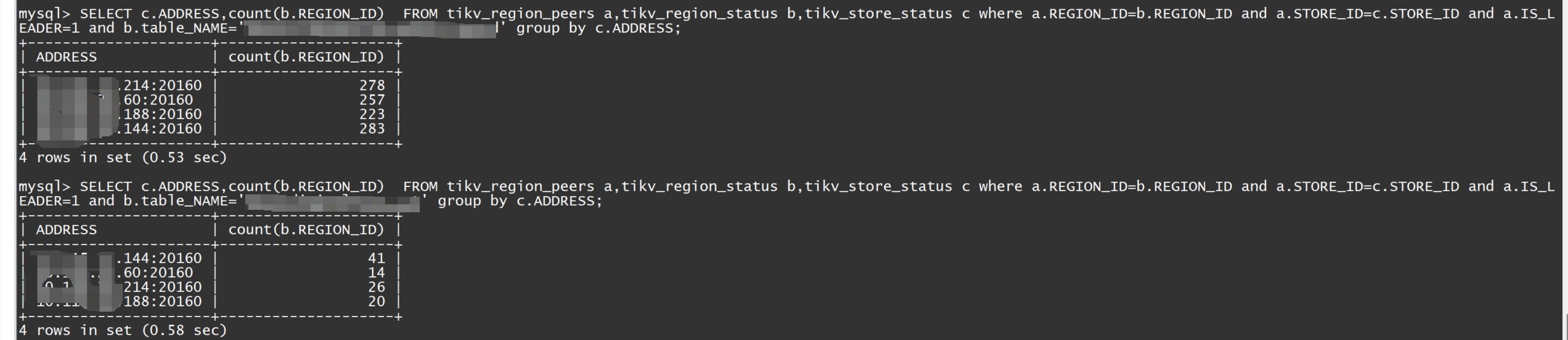
读热点很高,我查一下那些热点表在每个节点的数量统计一下看看
144这个tikv确实热点leader比较多,那这个咋移动啊,我们人为可以干预吗
可以针对热点表进行下热点问题处理,https://docs.pingcap.com/zh/tidb/v7.1/troubleshoot-hot-spot-issues#使用-shard_row_id_bits-处理热点表
这些表已经打散了,我们的主键id都是随机生成的字符串,不是自增的
operator add transfer-leader 2 5:将 Region 2 的 Leader 迁移至 Store 5每个主机的配置一样吗?
应该是正好这个热点表的region在那个114节点多,我查了其他的表,每个实例上的对应表的region都是有多有少,这个概率问题
配置肯定都是一样的