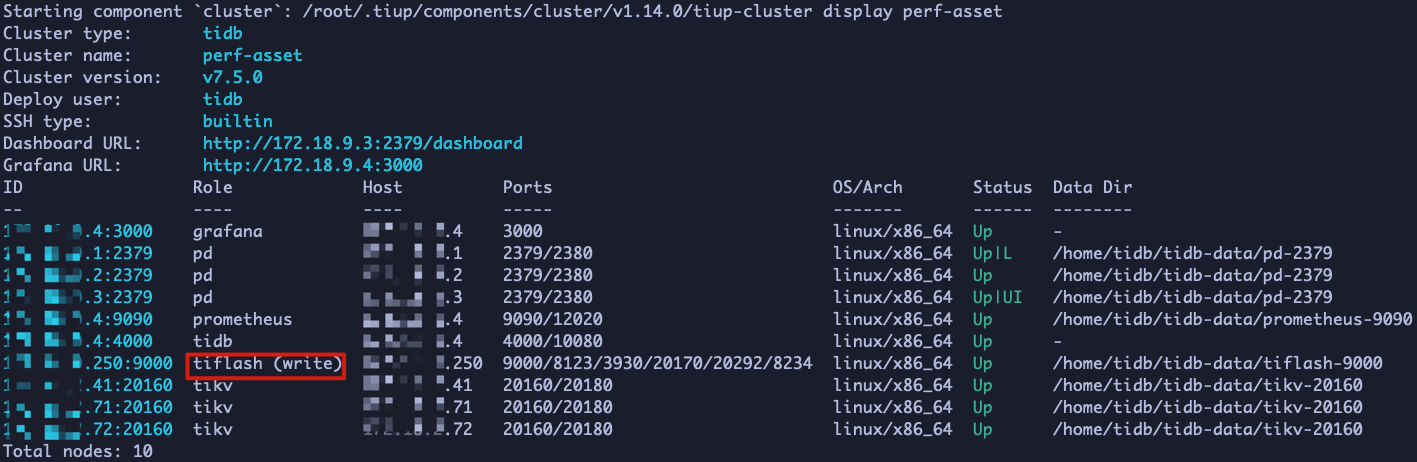
集群配置,只有一个tiflash write_node节点,并没有计算节点:
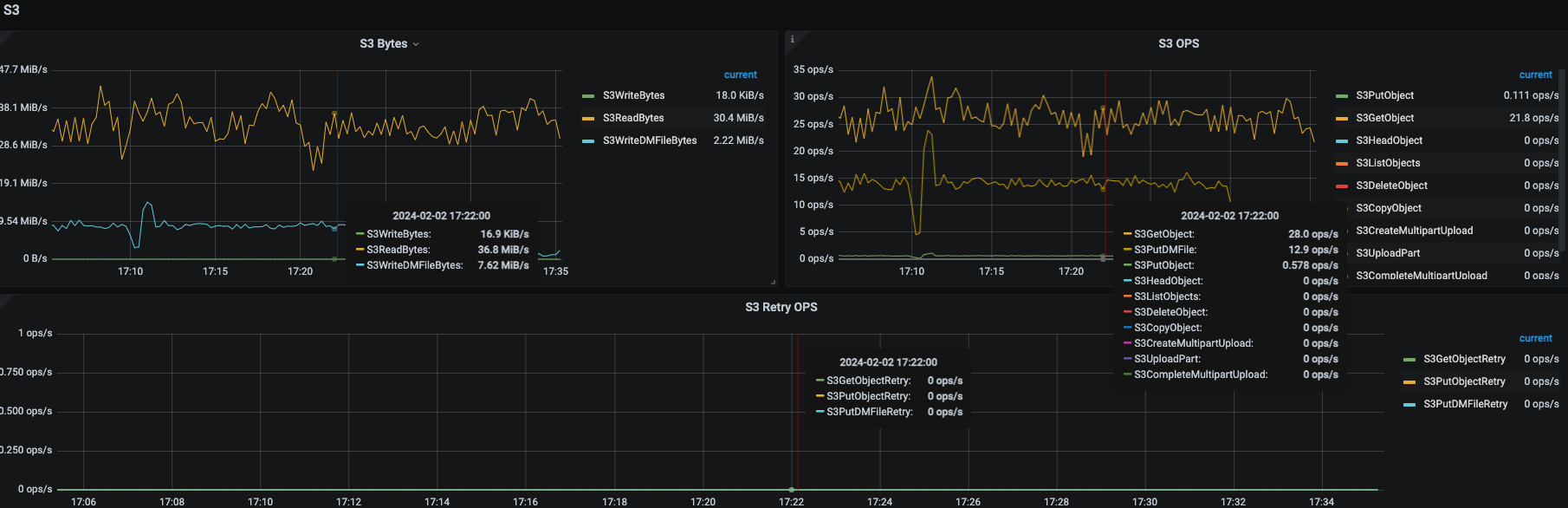
看监控可以看到,在set tiflash replica 1后,tiflash对OSS的操作,Read竟然比Write的量大很多,这个原因是?
集群配置,只有一个tiflash write_node节点,并没有计算节点:
看监控可以看到,在set tiflash replica 1后,tiflash对OSS的操作,Read竟然比Write的量大很多,这个原因是?
TiFlash副本之间在同步数据
数据分片读
tiflash本来就是面向MPP的,就是应对大量读的
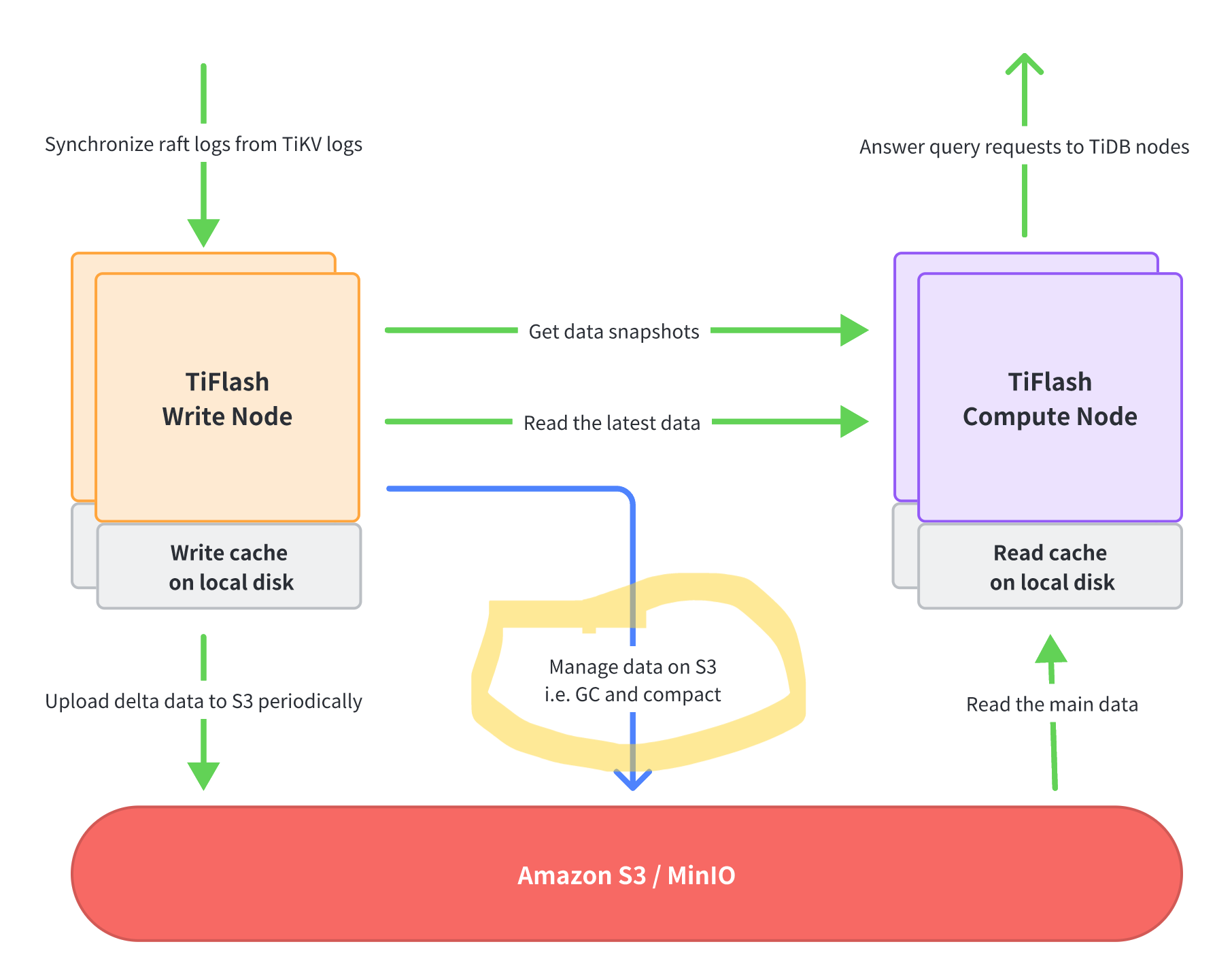
仔细看了下文档,现在大概明白了,所谓的write_node的local数据也真的仅仅是一个cache,数据量非常非常少,仅仅是充当一个写缓存,写S3成功之后就会在本地被删除掉。
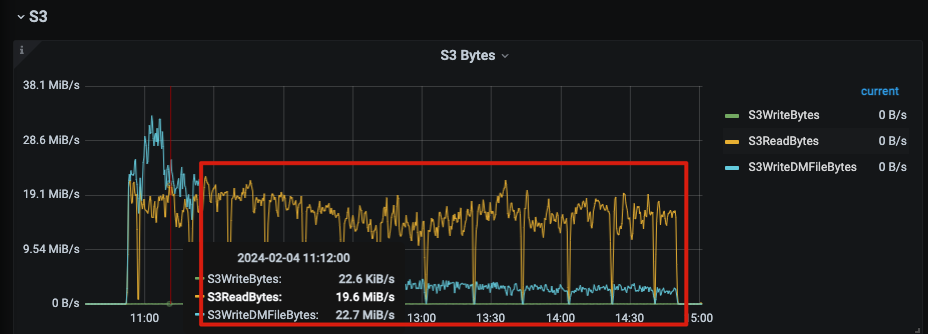
通过分析那段时间的监控也可以发现,即便是在迁移期间write_node的本地数据也一直只有4 MB多。在S3上的内容在初始上传后有96 GB,不过在经过一段时间稳定后只有55 GB,TiFlash也就不会再对S3产生GET操作。(我这套集群是个测试集群,上面没有读写请求,都是静态数据)
通过这里,也就可以发现TiFlash on S3架构现阶段时将S3当成普通的磁盘来使用的,有多少个write_node节点,在S3上就有多少个子目录,每个目录对应一个write_node节点。
日常的Merge/Split/GC/compact等操作,都需要直接读写S3中的数据。
学习了 ![]()
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。