引言
过去,TiDB 由于不支持存储过程、大事务的使用也存在一些限制,使得在 TiDB 上进行一些复杂的数据批量处理变得比较复杂。
TiDB 在面向这种超大规模数据的批处理场景,其能力也一直在演进,其复杂度也变得越来越低:
- 从 TiDB 5.0 开始,TiFlash 支持 MPP 并行计算能力,在大批量数据上进行聚合、关联的查询性能有了极大的提升
- 到了 TiDB 6.1 版本,引入了 BATCH DML 功能,该功能可以将一个大事务自动拆成多个批次去处理,在单表基础上进行大批量更新、删除、写入时能够大幅提升处理效率,同时避免了大事务所产生的一些影响。
- 而到了 7.1 LTS 版本,正式 GA 了 TiFlash 查询结果物化 的功能,使得 insert/replace into … select … 这种操作中的复杂 select 能够利用 TiFlash MPP 并行处理的能力,大幅提升了这种操作的处理性能。
- 前不久刚发布的 7.5 LTS,正式 GA 了一个 IMPORT INTO 的功能,该功能将原本 tidb-lightning 的物理导入能力集成到 TiDB 计算节点上,使用一条 SQL 语句就可以完成大批量数据的导入,大幅简化了超大规模数据写入时的复杂度。
TiDB 上之前有哪些批处理方案
1. INSERT INTO … SELECT 完成查询和写入
-
现状:适用于小批量数据处理,性能较高
-
挑战:大批量数据写入时,会产生大事务,消耗内存较高
-
说明:写入+单表查询场景可使用 BATCH DML 功能自动拆批
2. 针对 INSERT INTO/INSERT INTO … ON DUPLICATE …/REPLACE INTO 这些 SQL 使用批量接口执行,降低应用与数据库之间的交互次数,提升批量写入时的性能
-
现状:在合适的拆批方案、表结构设计上,处理性能非常高
-
挑战:编码不合理、表结构设计不合理时,可能会遇到热点问题,导致性能不佳
3. 通过 ETL 和调度平台提供的数据读取和写入能力实现大批量数据的处理
-
现状:主流的 ETL 平台,如 datax、spark、kettle 等,在合理表结构设计时,性能也比较高
-
挑战:难以多线程;多线程并行写入时,也有可能会遇到热点问题
4. 针对上游传过来的 csv 文件的数据,使用 LOAD DATA 来完成批量数据的写入,提升批量写入时的性能
-
现状:在对文件进行拆分+多线程并行后,处理性能非常高
-
挑战:当 LOAD DATA 一个大文件时此时是大事务,导致性能不佳;多线程处理时也有可能遇到热点问题,导致性能不佳
针对以上几种批处理方案,以及最新推出的 IMPORT INTO 功能,我们开展了一次测试,探索哪种批处理方案效率最高,消耗资源更低,以及使用更加简单。
TiDB 中不同批处理方案的测试
测试环境
-
TiDB 资源:3 台 16VC/64GB 虚拟机 + 500GB SSD 云盘(3500 IOPS + 250MB/S 读写带宽)
-
TiDB 版本:TiDB V7.5.0 LTS
-
TiDB 组件:**TiDB/PD/TiKV/TiFlash(混合部署)
-
-
存储资源:8C/64GB 虚拟机 + 500GB SSD 云盘(3500 IOPS + 250MB/S 读写带宽)
- 存储服务:NFS 服务、Minio 对象存储
-
测试资源:8C/64GB 虚拟机 + 500GB SSD 云盘(3500 IOPS + 250MB/S 读写带宽)
- datax + Dolphin调度/java 程序/dumpling、tidb-lightning 工具以及 MySQL 客户端

测试场景
将大批量查询结果快速写入到目标表,既考验查询性能,同时也考验批量写入的性能。
查询部分:多表关联+聚合
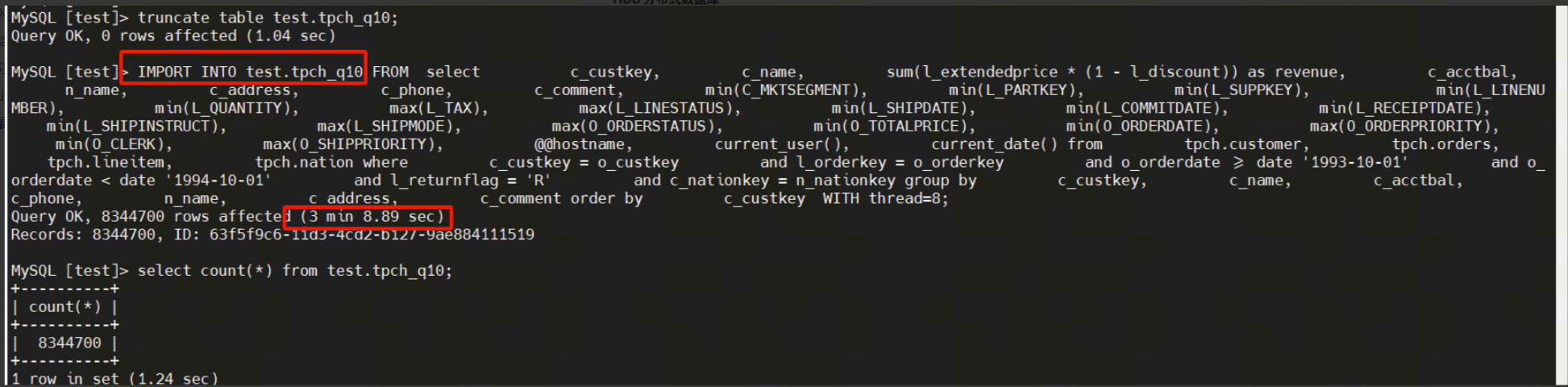
基于 TPCH 100GB 数据,扩展 Q10 查询中的字段和查询范围,返回 8344700 行数据。
select c_custkey,c_name,sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal,n_name,c_address,c_phone,c_comment,min(C_MKTSEGMENT),min(L_PARTKEY),
min(L_SUPPKEY,min(L_LINENUMBER),min(L_QUANTITY), max(L_TAX), max(L_LINESTATUS),
min(L_SHIPDATE), min(L_COMMITDATE), min(L_RECEIPTDATE), min(L_SHIPINSTRUCT),
max(L_SHIPMODE), max(O_ORDERSTATUS), min(O_TOTALPRICE), min(O_ORDERDATE),
max(O_ORDERPRIORITY), min(O_CLERK), max(O_SHIPPRIORITY),
@@hostname as etl_host,current_user() as etl_user,current_date() as etl_date
from
tpch.customer,tpch.orders,tpch.lineitem,tpch.nation
where
c_custkey = o_custkey and l_orderkey = o_orderkey
and o_orderdate >= date '1993-10-01' and o_orderdate < date '1994-10-01'
and l_returnflag = 'R' and c_nationkey = n_nationkey
group by
c_custkey,c_name,c_acctbal,c_phone,n_name,c_address,c_comment
order by c_custkey;
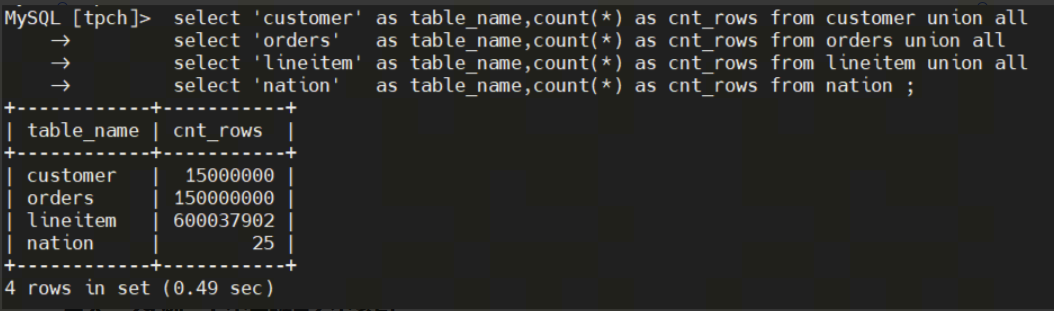
源表数据量
写入:29 列,1 个主键+2 个索引
CREATE TABLE `tpch_q10` (
`c_custkey` bigint(20) NOT NULL,
`c_name` varchar(25) DEFAULT NULL,
`revenue` decimal(15,4) DEFAULT NULL,
...
`etl_host` varchar(64) DEFAULT NULL,
`etl_user` varchar(64) DEFAULT NULL,
`etl_date` date DEFAULT NULL,
PRIMARY KEY (`c_custkey`) /*T![clustered_index] CLUSTERED */,
KEY `idx_orderdate` (`o_orderdate`),
KEY `idx_phone` (`c_phone`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
测试结果
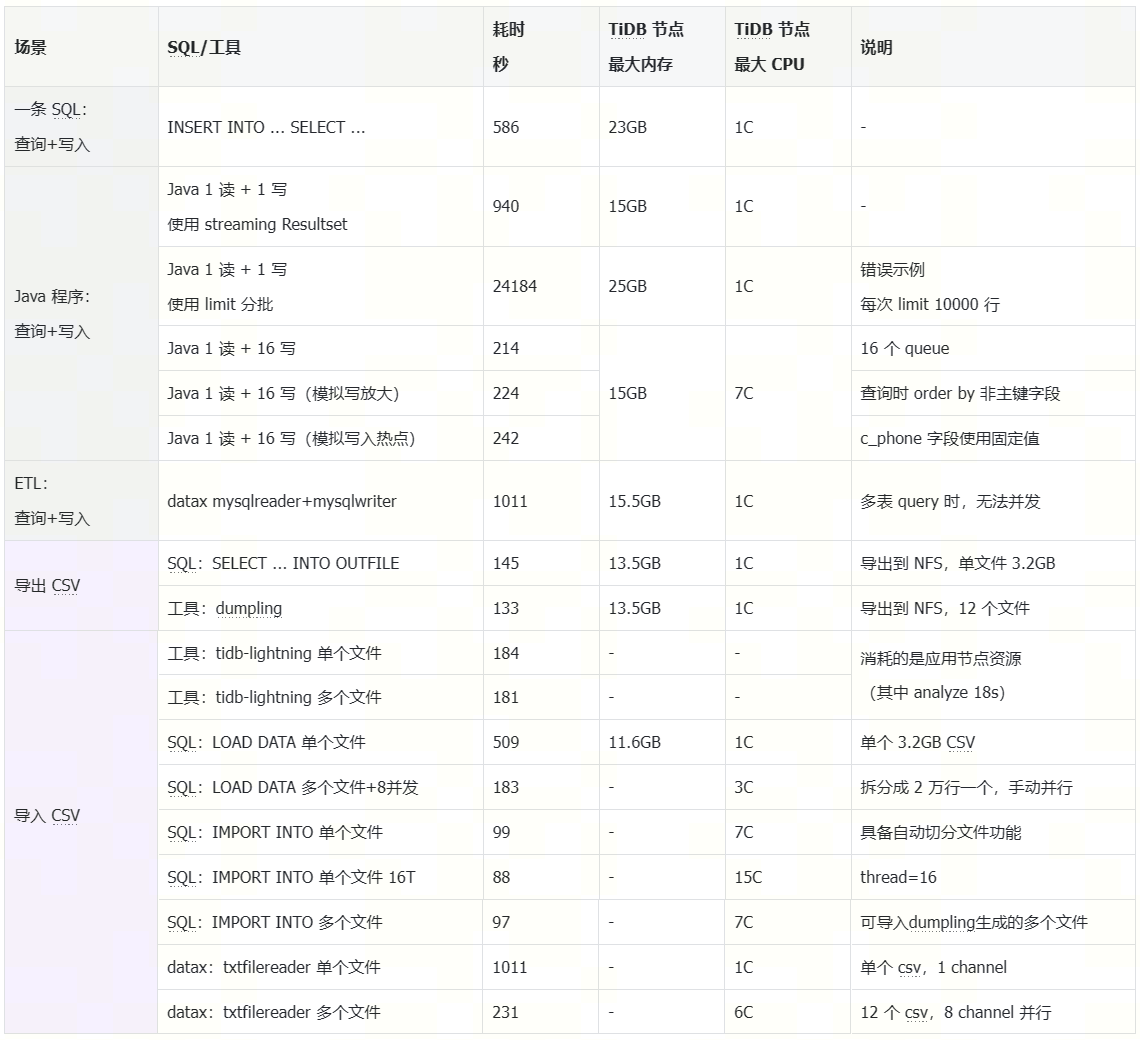
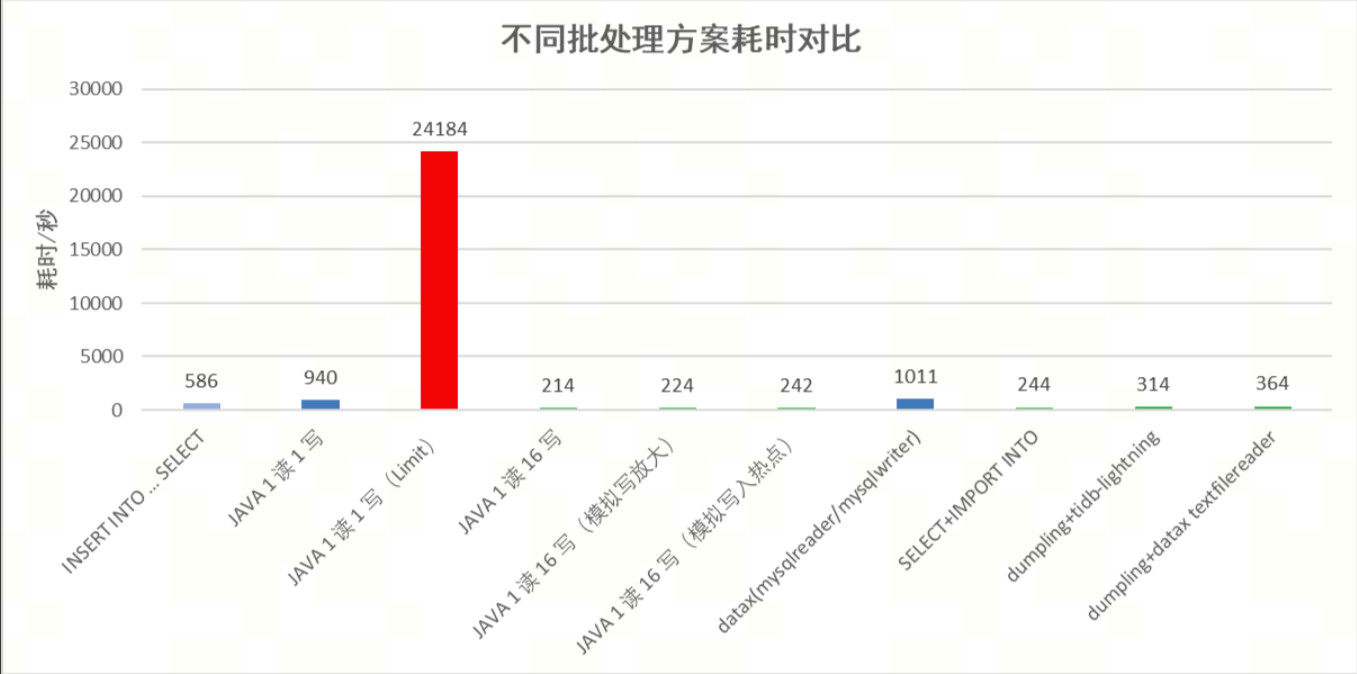
测试分析
-
JAVA 程序使用 SQL 进行批处理
-
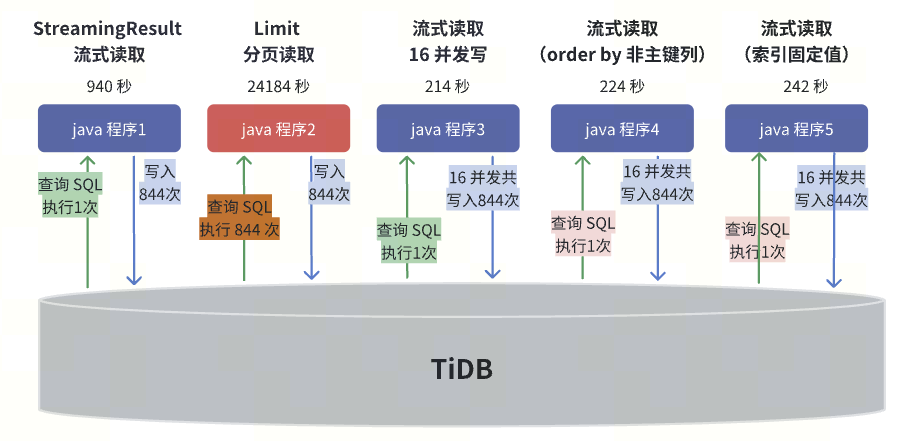
使用 JAVA 处理时,StreamingResult 流式读取+多并发写入能够获得非常好的性能。强烈不建议使用 limit 分页这种形式拆批,这种逻辑数据库将执行 844 条查询 SQL,效率极低,消耗的资源极高。同时 StreamingResult 这种流式读取还可以使用于数据导出的场景,对比使用 limit 分页处理,效率也更高。
-
在程序 4 中,将原本查询 SQL 里的 order by c_custkey 换成了 order by revenue desc 后,对性能也有一定影响,原因主要是多线程写入时 RPC 开销严重放大。
-
在程序 5 中,将原本查询 SQL 中的 c_phone 换成 ‘132-0399-0111’ as c_phone,模拟索引热点。
-
-
LOAD DATA 方式
-
如果使用 LOAD DATA 要获得比较高的性能,建议对单个文件进行拆分,同时 csv 中文件的顺序建议与目标表主键顺序一致,如一个 CSV 文件存储 20000 行,再通过多线程并行来写入,此时写入性能也比较高。
-
如果仅 LOAD DATA 导入单个大文件,那么性能较低,且消耗内存较高。
-
-
ETL+调度平台方式
-
作业类型:datax(mysqlreader + mysqlwriter),简单,效率一般
- 调度平台执行 datax 作业:使用 mysqlreader 方式读取时,默认就使用流式读取,但是对于多表查询的 query 时,写入时无法并发
-
作业类型:shell + datax(txtfileread + mysqlwriter),较复杂,效率较高
- 调度平台执行 shell:使用 dumpling 导出成多个 csv 文件
- 再调度 datax 作业:使用 txtfilereader + mysqlwriter,此时可以多线程并发写入,效率较高
-
作业类型: SQL ,简单高效
- 调度平台执行 SQL:select … into outfile
- 调度平台执行 SQL:import into
-
SELECT … INTO OUTFILE 导出查询结果(当前仅支持导出到文件系统)
该功能大家平时可能使用比较少,但该功能非常有价值,它可以高效的将数据一批导出、并且数据是完全一致的状态,可以用于:
-
批量数据处理:JAVA 程序可直接执行该 SQL 完成结果的导出
-
在简单的数据导出场景,使用导出 csv 替换原本 limit 处理逻辑,应用将查询结果导出到一个共享 NFS/S3 对象存储中,再读取 NFS/S3 对象存储中的 CSV,进行结果的处理,极大的降低了数据库的压力,同时性能将比之前使用 limit 分批处理更高。
-
-
IMPORT INTO 导入 CSV (当前支持 S3 协议对象存储以及文件系统)
该功能 7.5.0 引入,极大的简化了数据导入的难度,JAVA 程序可直接执行该 SQL 完成 CSV 数据的导入,在进行批处理时应用节点几乎不需要消耗 CPU/内存资源。以下是使用示例:
IMPORT INTO test.tpch_q10 FROM '/mnt/nfs/test.tpch_q10.csv' with FIELDS_TERMINATED_BY='\t',split_file,thread=8;需要注意的是:IMPORT INTO 导入过程中,不会产生日志,所以针对需要 CDC 同步或 Kafka 分发的场景,该方案不适用。
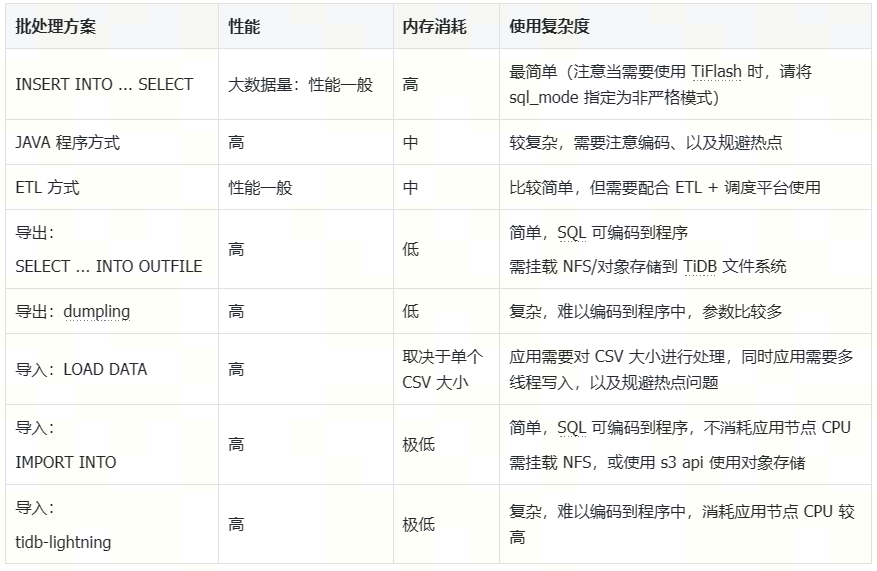
测试小结
部分测试代码示例: https://github.com/Bowen-Tang/batch-samples
总结与展望
TiDB 7.5.0 引入的 IMPORT INTO 功能,结合 SELECT … INTO OUTFILE、以及 NFS/对象存储,让 TiDB 上增加了一种更加简单且非常高效的批处理方案,JAVA 应用程序处理时更加简单,ETL 调度也更简单。
以下是 TiDB 使用 IMPORT INTO、SELECT … INTO OUTFILE 的架构示例:
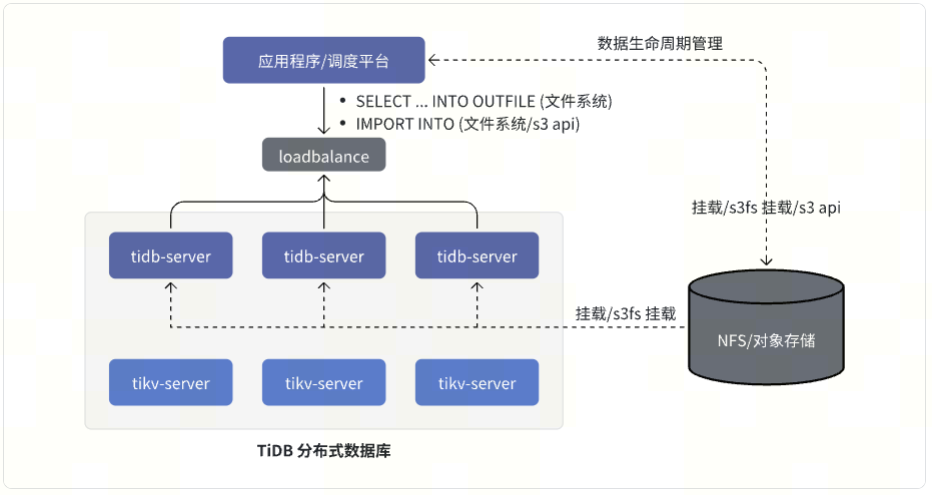
IMPORT INTO 功能当前仅支持 CSV 导入,未来 TiDB 8.x 版本中 IMPORT INTO 将直接集成 IMPORT INTO … SELECT … 功能,极致简化批处理操作,性能也更进一步提升 (187 秒),敬请大家期待: