mikey
(Bbhy135258)
1
2024-01-18 20:10:00 对TiDB其中几个表进行了归档操作,归档期间cdc产生延迟,直到停止归档后cdc链路延迟消费完成后恢复
【 TiDB 版本】 V6.1.5
【 Bug 的影响】
每日0点会对通过cdc同步到kafka的前一天的数据进行处理,如果0点的时候延迟会影响到当天的报表数据。
cdc的延迟导致0点过后消费时未完全消费完当天数据
【期望看到的行为】
归档时cdc性能能够承载删除产生的数据量
【其他背景信息或者截图】
归档日志截图:
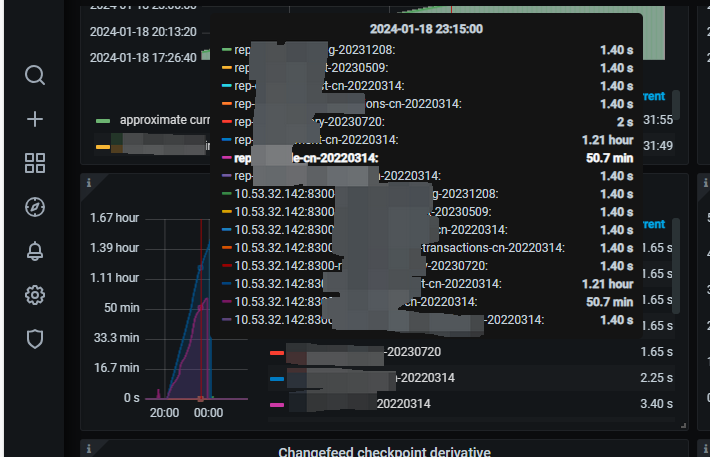
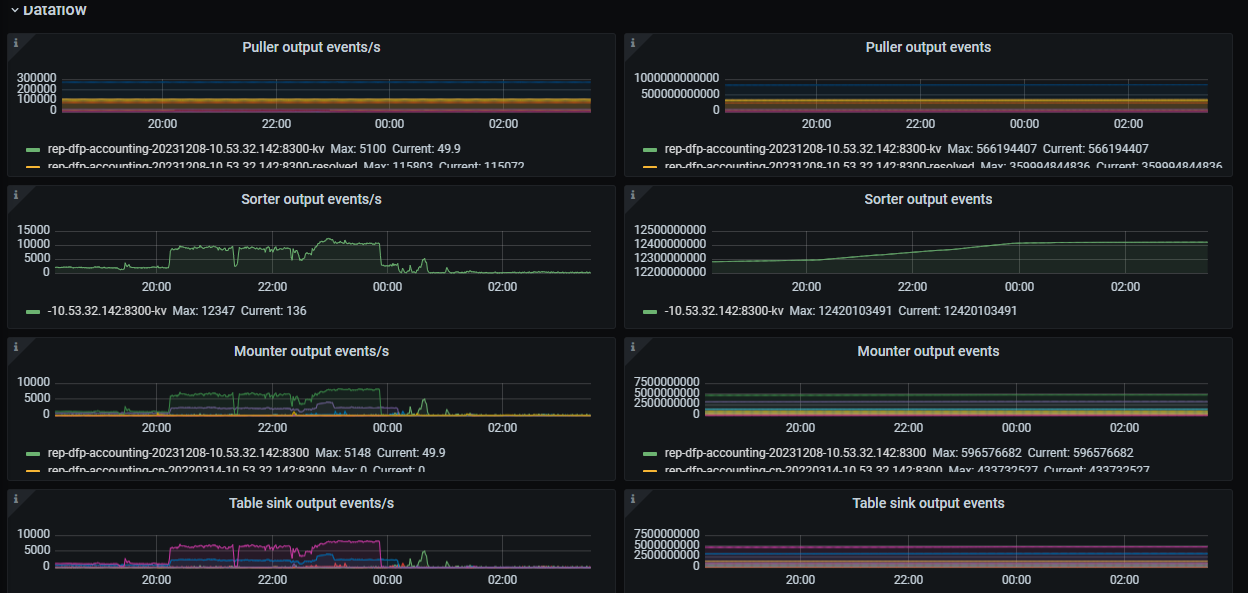
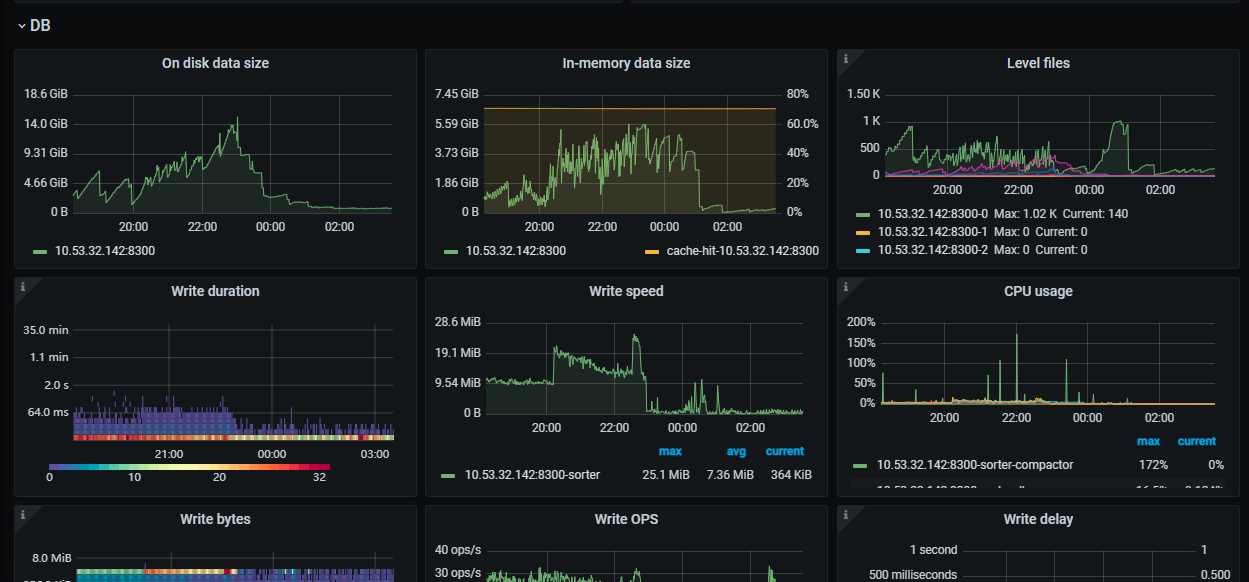
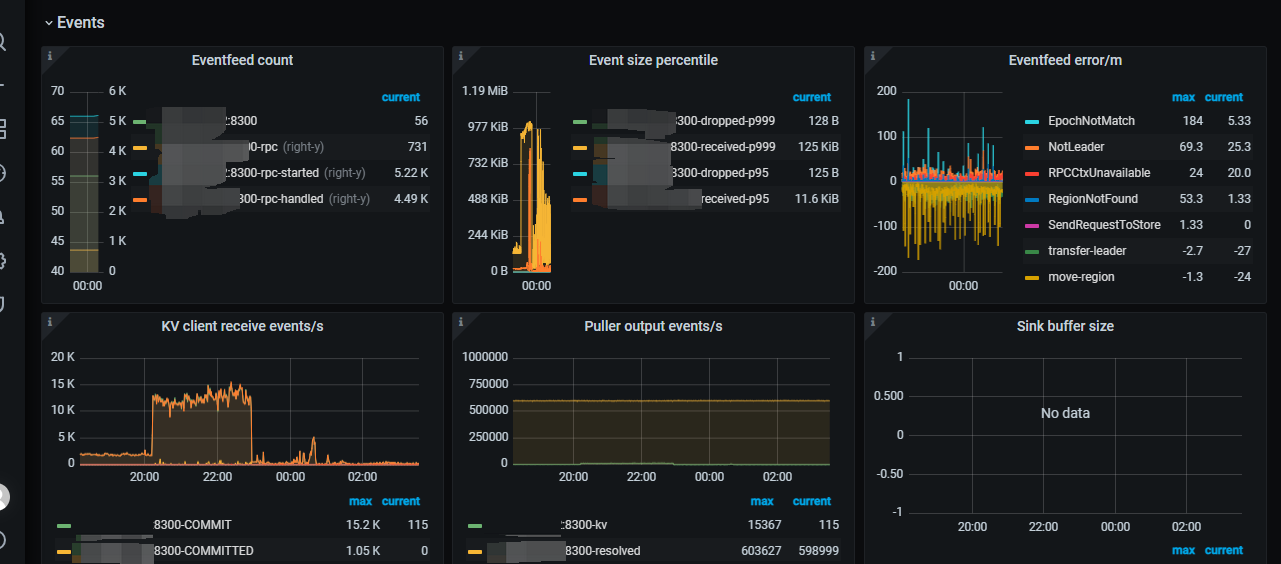
cdc延迟grafana截图1:
cdc延迟grafana截图2:
cdc延迟grafana截图3:
cdc延迟grafana截图4:
zhanggame1
(Ti D Ber G I13ecx U)
2
归档是删除原来表部分数据,插入到历史表里面吗,都是一个数据库内完成的?
路在何chu
(Ti D Ber Ass Gn Qs R)
3
你直接建一个归档库,归档的数据就不同步了,就不存在延时了,加入你设置了cdc过滤机制
https://docs.pingcap.com/zh/tidb/stable/ticdc-filter
在 6.2 有 事件过滤器…指定某张表的 delete 不要同步到下游,看看是不是可以满足你们的需求,应该升级到 6.5.x 就可以体验到这个功能。
你的这个cdc性能瓶颈在 sorter 阶段,puller阶段正常,sorter比较慢,影响了后续的同步QPS。
进行针对性调优即可。
可以参考一下我之前的优化cdc经验,如果你的 TiCDC 同步性能一直无法提升,也暂时找不到好的处理方法,试试调大 per-table-memory-quota 参数吧,很可能会有意外的惊喜。
system
(system)
关闭
9
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。