Trouble
2024 年1 月 30 日 12:01
1
我是tidb新手,关于二级索引有一些疑问,希望能得到解答。
1, “TiDB”, “SQL Layer”, 10
t10_r1 → [“TiDB”, “SQL Layer”, 10]
t10_i1_10_1 → null
此时假如我查询age=10,sql的执行流程是不是如下所述:
tidbserver解析sql
查询pd上关于age的索引内容,定位到t10_i1_10在某一个region上
将执行计划发送给该region,得到其对应的rowid是1. 将rowid=1返回给tidbserver层
tidbserver再次请求pd获取rowid=1所在的region
到该region查询rowid=1的数据
请大家帮我看下执行流程中的第3、4、5步理解是否正确?非常感谢!!!!
是的
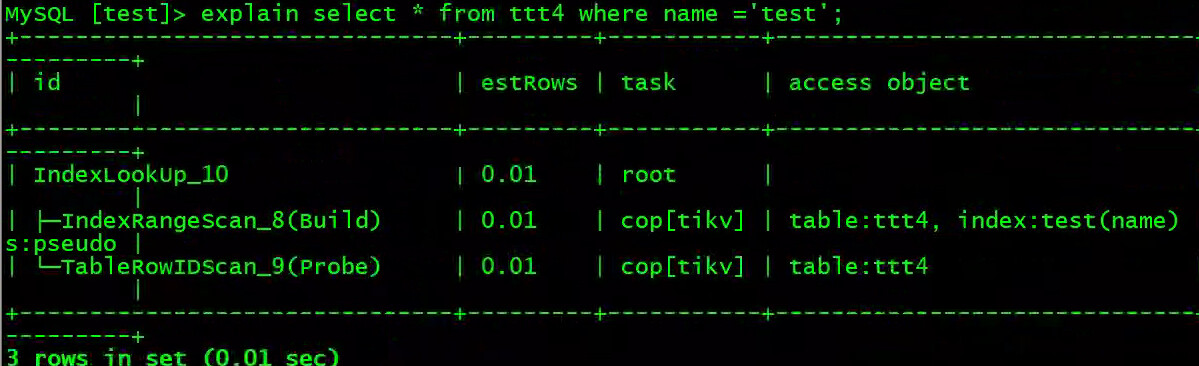
看执行计划,IndexLookUp_10的task是在tikv上,取到id后,IndexLookUp_10算子在root就是tidbserver上IndexLook下面TableRowIDScan_9获取结果数据
1 个赞
Trouble
2024 年1 月 30 日 12:40
3
针对当前的查询,tidbserver会查询两次pd:
changpeng75
2024 年1 月 30 日 12:56
4
第一次查询获得rowid后不需要返回给tidb,直接在tikv上查询数据了,因为数据是不可能在其他region上的。其实从执行计划上也能看出来,cop的过程是不需要跟tidb交互的。
zhanggame1
2024 年1 月 30 日 13:02
5
单表查询tikv通过二级索引查到rowid,然后tikv取数据返回tidb
要返回tidb的,而且tidb-server 中不是每次获取region的位置都需要去请求pd的,为了保证效率,会有一个 region 等元数据的缓存,tidb-server是先去自己的缓存里获取region位置,拿到位置后就直接去访问数据了,这是绝大部分的情况。少数情况,如果去tikv后发现位置不对(region被merge、split),再重新去pd要最新的位置并更新缓存。
访问一个普通索引,是会发生 indexLookUp 回表访问的。通过普通索引拿到行数据的 _tidb_row_id,再根据 _tidb_row_id 回表去查整行数据。这个过程和 MySQL 里先去搜索二级索引树,再去搜索聚簇索引树,访问叶子节点拿到数据的过程有异曲同工之妙。
2 个赞
Trouble
2024 年1 月 30 日 16:26
7
感谢对于pd访问及缓存知识的解答。是否需要先将结果返回到tidb server层 ,然后tidb server层再次根据rowid去tikv获取数据行。
有猫万事足
2024 年1 月 31 日 03:58
9
client->tidbserver->pd(cache)->tikv(index)->tidbserver->pd(cache)->tikv(table)
需要读两次。https://github.com/tikv/client-go
tidb通过这个组件访问tikv。你甚至可以单独使用这个组件直接把tikv当作一个kv存储而不是数据库使用。@Jellybean 说的。这个cache只会在初始化的时候从pd获取一次,后续只有发生访问不到region或者超过一定时间的时候,才会让对应region在cache失效,重新去pd获取一次region信息。
还有些其他的细节,可以看下面这个连接:https://github.com/tikv/pd/wiki/Metadata-Management
3 个赞
要的。是需要先将结果返回到tidb server层 ,然后tidb server层再次根据rowid去tikv获取数据行。
你看执行计划里task的那一列,在IndexLookUp时是在root,说明就是回到tidb-server层了。
1 个赞
tidb实例会缓存一些元数据在本地。如果结果数据缓存存在,就不需要去访问pd了?如果不存在,回去访问pd,且在tidb缓存最新的数据, 是这么理解!!??
有猫万事足
2024 年1 月 31 日 06:24
13
zhanggame1
2024 年1 月 31 日 06:36
14
tidb缓存region分区情况,sql执行解析成访问region,然后发到对应的tikv,如果tikv没找到,tidb才向pd查询
system
2024 年3 月 31 日 06:37
15
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。