【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
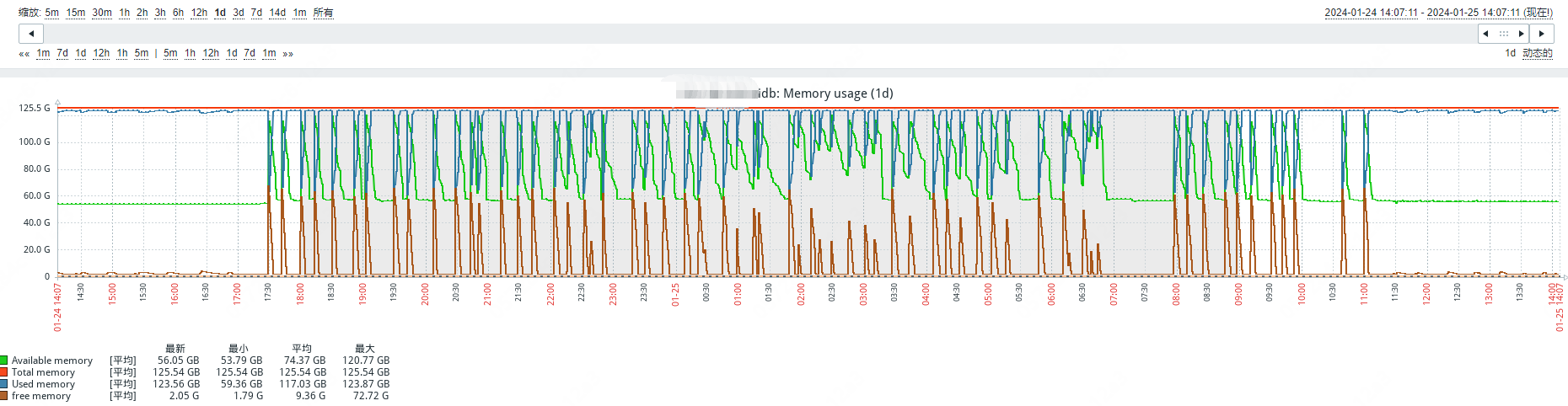
开发反馈业务查询时有超时和延时的情况,通过dashboard的流量可视化看,有延迟的sql,从流量可视化查看,没有特别明显的读热点问题。后来看了zabbix,发现内存频繁波动。然后又查了tikv节点的系统日志和grafana。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
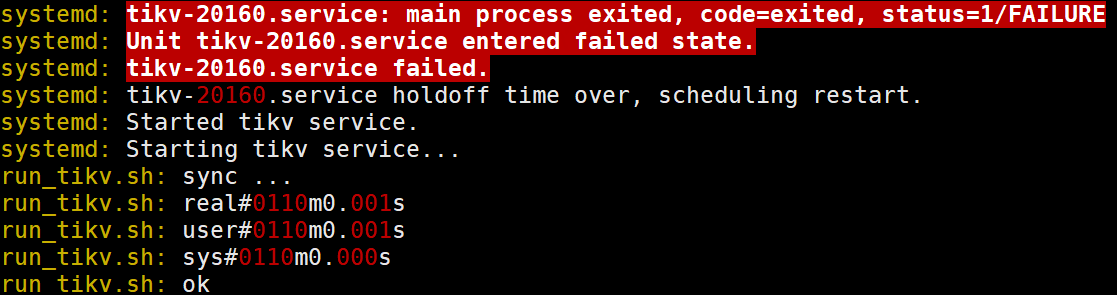
三个节点的tikv系统日志都显示自动重启过
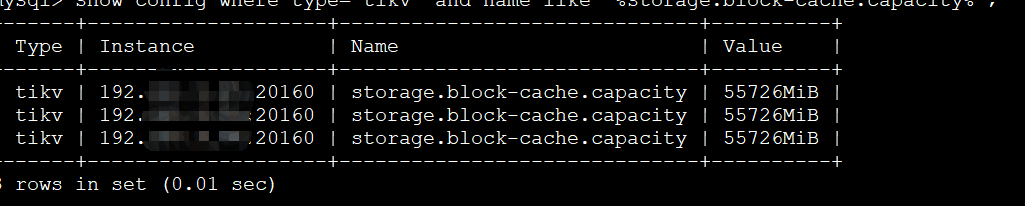
三台tikv每个节点内存都是128G,storage.block-cache.capacity设置为54G。
啦啦啦啦啦
2
grep "Out of memory" /var/log/messages看看日志是不是OOM了,tikv节点上有没有混部其他组件
系统日志没有发现out of memory ,tikv节点也没有和其它组件混用。
啦啦啦啦啦
4
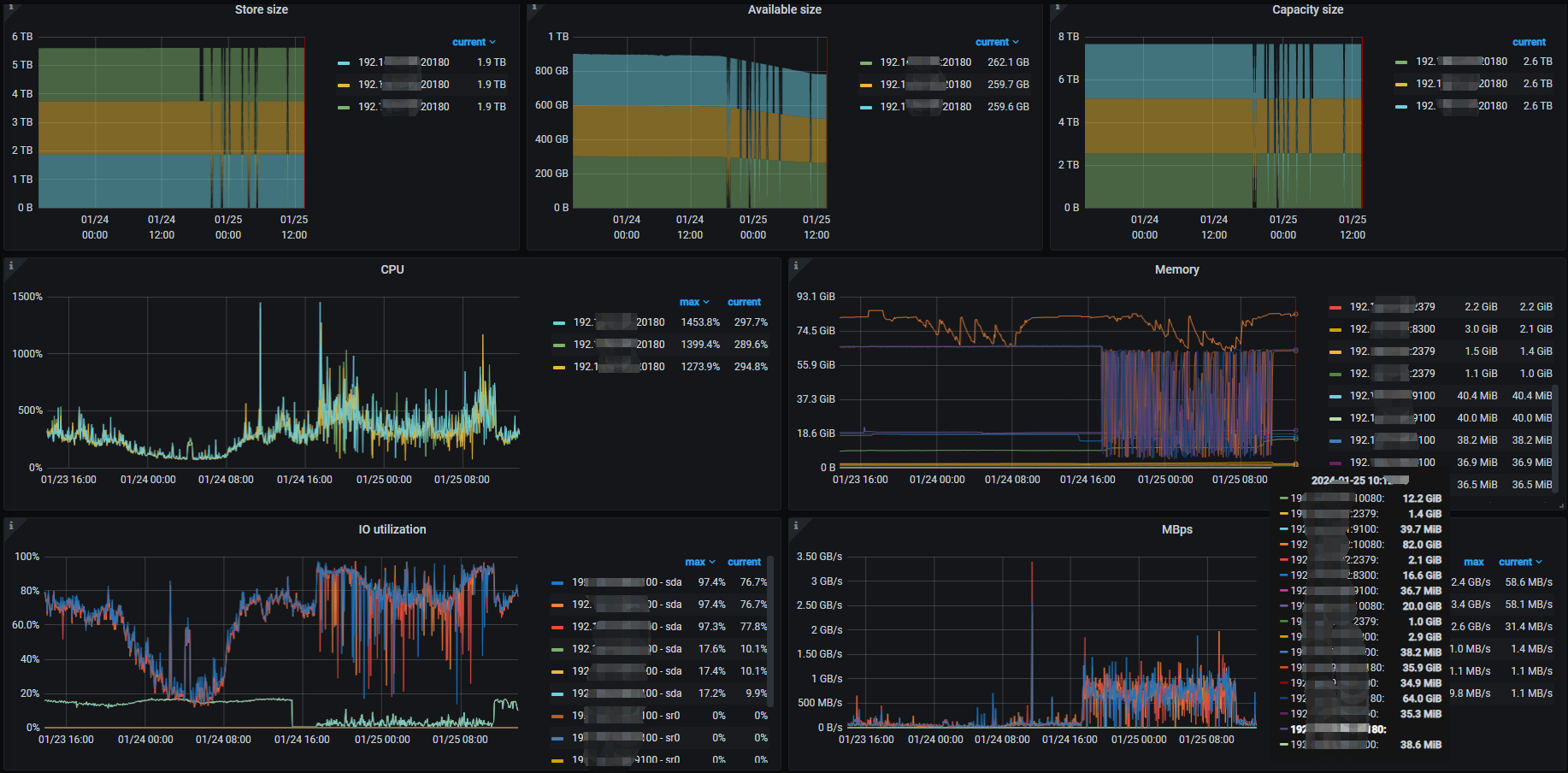
看监控tikv内存一直接近100%,可以考虑把block-cache-size配置小点
晚上可以试一下,白天搞怕影响其它的业务。这个参数需要重启tikv节点生效吗
小龙虾爱大龙虾
(Minghao Ren)
7
给个建议,IP地址脱敏可以盖住前几位,方便区分不同实例,你光漏个前边都是192也没啥意义 
啦啦啦啦啦
9
得重启,业务低峰期tiup edit-config改吧
啦啦啦啦啦
10
查询量大概每天30万左右,但是晚上查询量倒不是很大,但从昨天下午持续到今天中午。
我的建议是直接把block-cache.capacity控制在40G,内存先降下来再说,然后观察几天内存最大能用到多少。。。
SET config tikv storage.block-cache.capacity=‘40960MiB’;
在线修改,立即生效。
zhanggame1
(Ti D Ber G I13ecx U)
17
内存那个进程用的,登录机器top人后ctrl+M排序看看
changpeng75
(Ti D Ber Aw K Xsgx O)
20
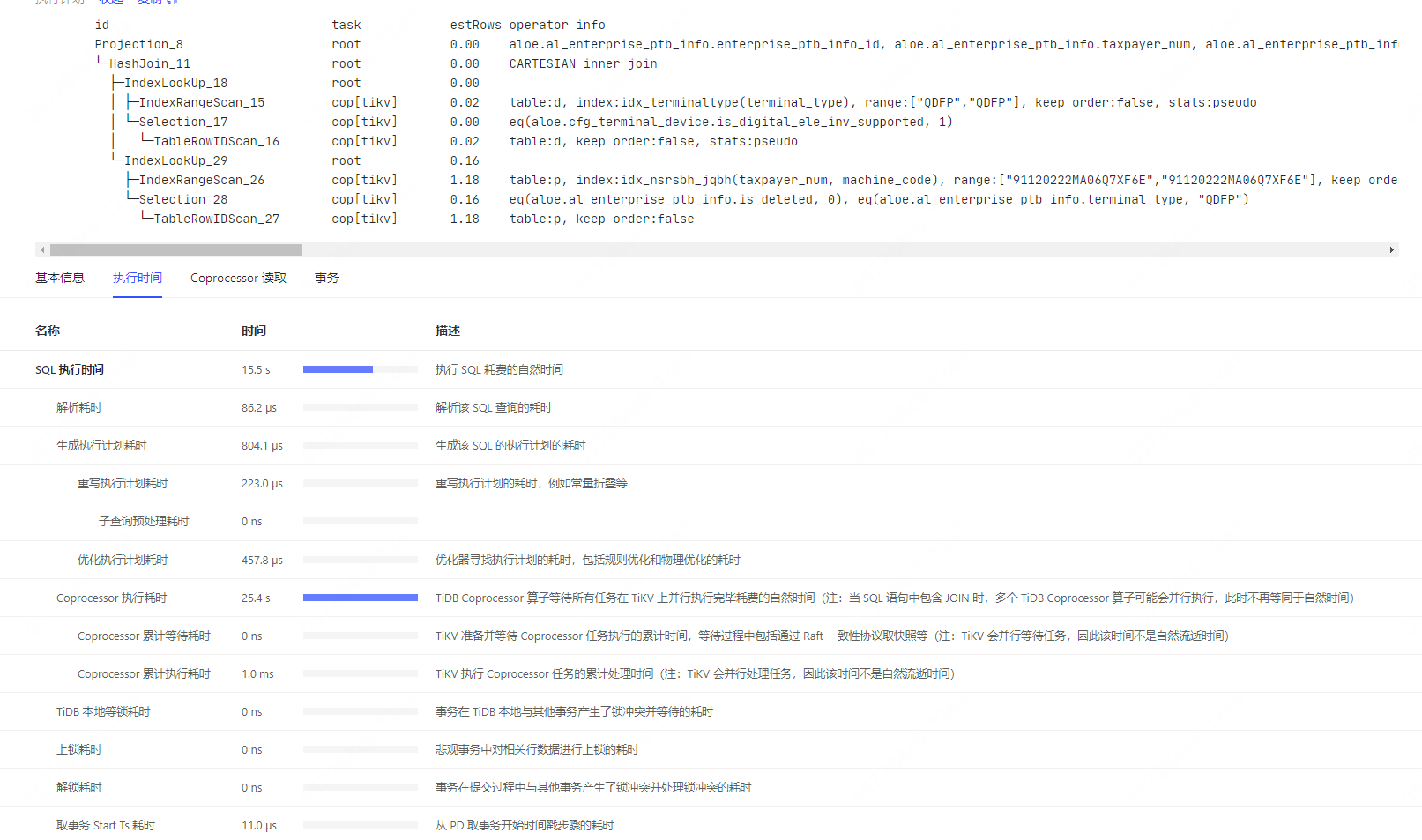
完整的SQL和执行计划贴上来看一下。
由于存在并行计算,下推算子的执行时间并不算太长。