请教一下,tidb查询表数量比例是多少,走全表,不走索引,因为超过改比例,走全表代价比走索引低,走索引还要回表
比如,我一张表2千万行,查询条件数据量是500万行,默认是走索引,还是走全表扫描。
我记得oracle是30%的比例
不是要根据具体的查询条件看LOOKUP回表量看走全表还是索引么?
这是和优化器有关呀
这个应该没有固定比例吧,坐等源码大佬解释~
哪有30,10%以上就是走全表更合理了。。。
这个也要分大表小表,要不要回表之类的问题把
坐等源码大佬解释~+1
通常是不超过40%
1 个赞
这个要看优化器的算法,好像没有固定的值
多大比例,多大数据量一半是大家总结出来的估算值吧。优化器不会这么死板的定个常量值吧
还是看执行计划来得准确
坐等源码大佬解释~+1
坐等源码大佬解释~+1
Oracle是2%左右,不是10%和30%;具体由一组cost参数控制。
TiDB如果也有一组控制 FTS和Index scan的成本参数的话,会影响这个比例值。
这应该和硬件也有一定关系,磁盘性能越好同时CPU性能越差,优化器越倾向选择全表扫描
你自己拿一个大表测试一下。
2 个赞
宽表更容易走索引,窄表更容易走全表,Oracle下3%-30%都有可能的
70%以上走全表,但这个不是固定
本来看代码有点找不到了,经过 @h5n1 提醒:
explain format=‘cost_trace’ 这个看执行计划有cost计算公式
这个问题有了一些进展,权当抛砖引玉好了。
我找了一张大表,大致有3.5亿数据,analyze之后,根据时间片查询的结果如下:
index scan:
table scan:

具体的公式格式化结果后,index scan:
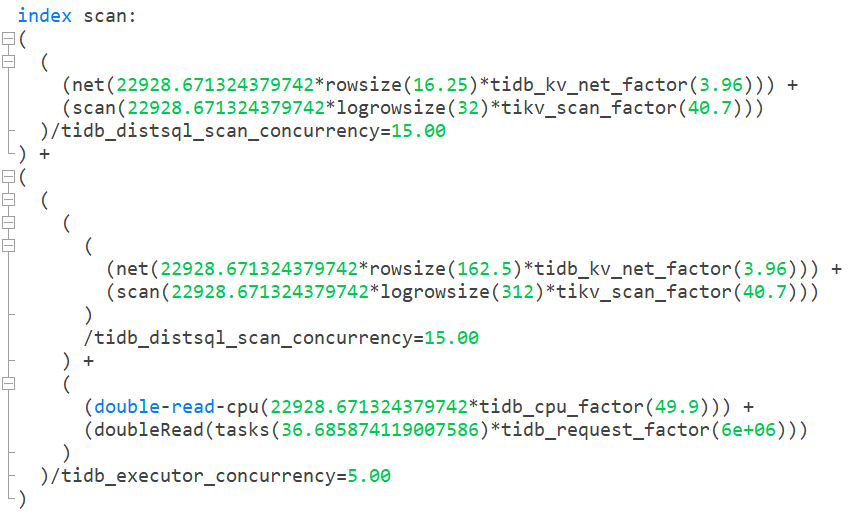
table scan:

这个看着还是有点乱。让我们把重点突出一下。
在index scan的这个公式里面,起决定性作用的是:
(doubleRead(tasks(36.685874119007586)*tidb_request_factor(6e+06)))
)/tidb_executor_concurrency=5.00
因为tidb_request_factor的代价设置非常高,一次就是6000000.
https://github.com/pingcap/tidb/blob/master/pkg/planner/core/plan_cost_ver2.go#L940
所以当index scan发生的时候,其cost基本可以简化为上面这个式子,其他的影响权重非常小。
task的数量的公式为
https://github.com/pingcap/tidb/blob/master/pkg/planner/core/plan_cost_ver2.go#L275
batchSize := float64(p.SCtx().GetSessionVars().IndexLookupSize)
taskPerBatch := 32.0 // TODO: remove this magic number
doubleReadTasks := doubleReadRows / batchSize * taskPerBatch
IndexLookupSize 可以通过show variables like 'tidb_index_lookup_size'查看,我这边设置为20000。
所以tasks=预估读取行数(22928)/tidb_index_lookup_size(20000)*taskPerBatch(32)=36.68左右。
因此,现在如果我们希望index scan的代价变低,比较有效的做法有两个,提高tidb_index_lookup_size和tidb_executor_concurrency的值。
同理,我们看看table scan的代价计算方式,主要的部分是:
(
(cpu(3.5718153e+07(总记录数)*filters(1)*tikv_cpu_factor(49.9))) +
(scan(3.5718153e+07(总记录数)*logrowsize(312)*tikv_scan_factor(40.7)))
)/(tidb_distsql_scan_concurrency)15.00
net的部分cost影响权重很小,可以直接忽略,cost值主要的影响因素在于全表记录大小和tidb_distsql_scan_concurrency的值的大小。
全表记录大小是没有办法调整的,为了降低table scan 的cost,那就只剩下调大tidb_distsql_scan_concurrency的值,这一个办法。
回到标题的问题。这个比例是不太好算的,但可以大致推算,当
(index scan的预估记录数/tidb_index_lookup_size*32*tidb_request_factor)/tidb_executor_concurrency小于
表的总记录数* logrowsize*tikv_scan_factor/tidb_distsql_scan_concurrency
大体就会选择index scan而非table scan。同时如果为了让优化器尽可能的选择index scan还可以通过2种参数设置来做到:
1,提高tidb_index_lookup_size的值
2,提高tidb_executor_concurrency的值
8 个赞