【 TiDB 使用环境】生产环境
【 TiDB 版本】
tikv 6.5.0
【复现路径】做过哪些操作出现的问题
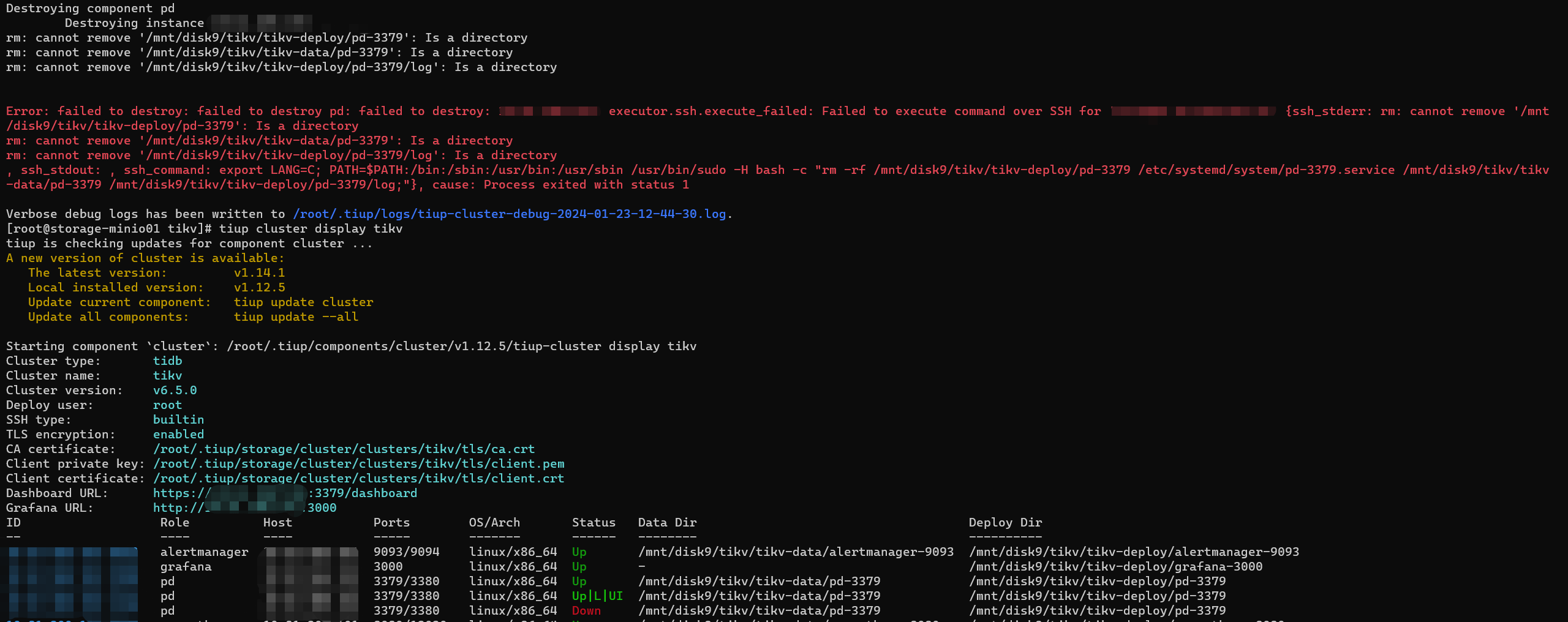
发现硬盘故障导致 一个pd和tikv 服务处于Down的状态
尝试通过scale out + scale in 的方式上线一个新pd节点,并剔除原有故障pd
【遇到的问题:问题现象及影响】
启动新 pd 节点失败
[2024/01/23 11:27:42.636 +08:00] [FATAL] [main.go:91] [“join meet error”] [error=“etcdserver: unhealthy cluster”] [stack=“main.main\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/pd/cmd/pd-server/main.go:91\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250”]
[2024/01/23 11:28:58.547 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=endpoint://client-01788ffb-4391-4d54-9a41-e121785ca621/10.81.200.101:3379] [attempt=0] [error=“rpc error: code = Unavailable desc = etcdserver: unhealthy cluster”]
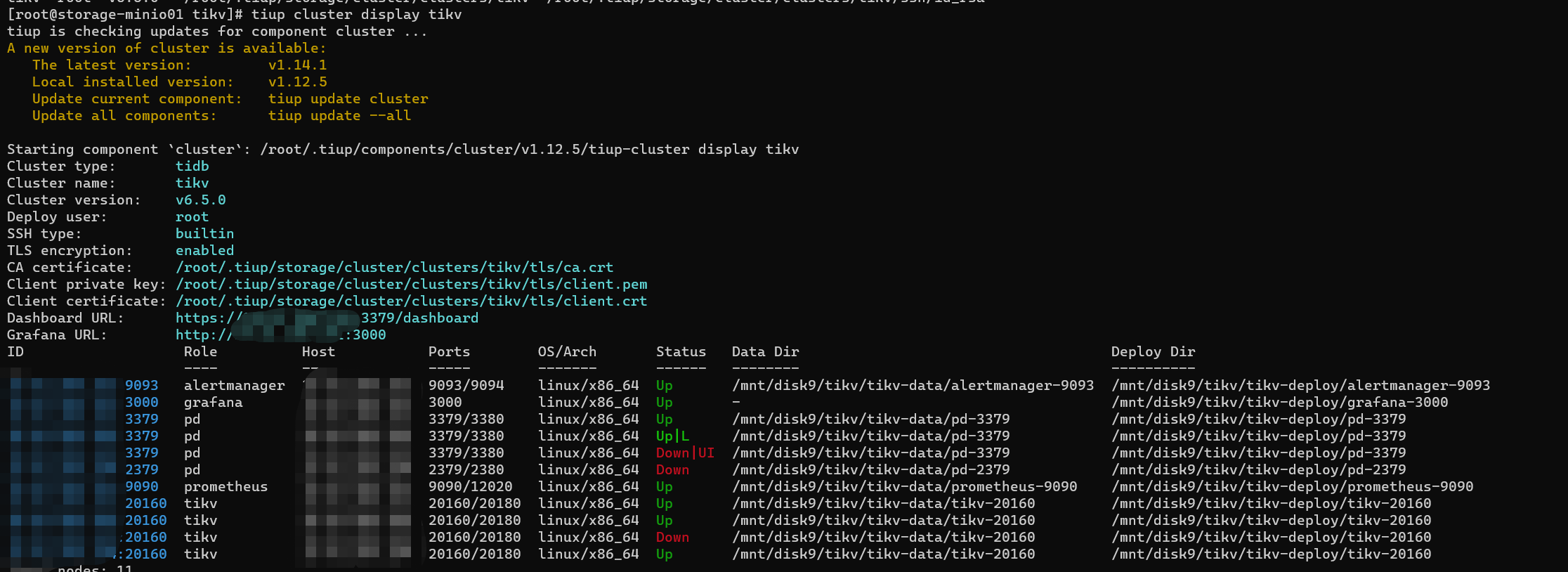
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面

【附件:截图/日志/监控】