Quino
(Ti D Ber 36 T Ihh Zu)
21
这个是我的 operator的 yaml文件内容
clusterScoped: true
rbac:
create: true
timezone: UTC
operatorImage: 'pingcap/tidb-operator:v1.6.0-alpha.9'
imagePullPolicy: IfNotPresent
tidbBackupManagerImage: 'pingcap/tidb-backup-manager:v1.6.0-alpha.9'
features: []
appendReleaseSuffix: false
controllerManager:
create: true
serviceAccount: tidb-controller-manager
clusterPermissions:
nodes: true
persistentvolumes: true
storageclasses: true
logLevel: 2
replicas: 1
resources:
requests:
cpu: 80m
memory: 50Mi
autoFailover: true
pdFailoverPeriod: 5m
tikvFailoverPeriod: 5m
tidbFailoverPeriod: 5m
tiflashFailoverPeriod: 5m
dmMasterFailoverPeriod: 5m
dmWorkerFailoverPeriod: 5m
detectNodeFailure: false
affinity: {}
nodeSelector: {}
tolerations: []
selector: []
env: []
securityContext: {}
podAnnotations: {}
scheduler:
create: true
serviceAccount: tidb-scheduler
logLevel: 2
replicas: 1
schedulerName: tidb-scheduler
resources:
limits:
cpu: 250m
memory: 150Mi
requests:
cpu: 80m
memory: 50Mi
kubeSchedulerImageName: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler
affinity: {}
nodeSelector: {}
tolerations: []
securityContext: {}
podAnnotations: {}
configmapAnnotations: {}
advancedStatefulset:
create: false
image: 'pingcap/advanced-statefulset:v0.4.0'
imagePullPolicy: IfNotPresent
serviceAccount: advanced-statefulset-controller
logLevel: 4
replicas: 1
resources:
limits:
cpu: 500m
memory: 300Mi
requests:
cpu: 200m
memory: 50Mi
affinity: {}
nodeSelector: {}
tolerations: []
securityContext: {}
admissionWebhook:
create: false
replicas: 1
serviceAccount: tidb-admission-webhook
logLevel: 2
rbac:
create: true
validation:
statefulSets: false
pingcapResources: false
mutation:
pingcapResources: true
failurePolicy:
validation: Fail
mutation: Fail
apiservice:
insecureSkipTLSVerify: true
tlsSecret: ''
caBundle: ''
cabundle: ''
securityContext: {}
nodeSelector: {}
tolerations: []
Quino
(Ti D Ber 36 T Ihh Zu)
22
这个是 tidb-cluster 的 yaml 应用设置内容
rbac:
create: true
crossNamespace: false
extraLabels: {}
schedulerName: tidb-scheduler
timezone: UTC
pvReclaimPolicy: Retain
enablePVReclaim: false
services:
- name: pd
type: ClusterIP
discovery:
image: 'pingcap/tidb-operator:v1.6.0-alpha.8'
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 250m
memory: 150Mi
requests:
cpu: 80m
memory: 50Mi
affinity: {}
tolerations: []
enableConfigMapRollout: true
haTopologyKey: kubernetes.io/hostname
tlsCluster:
enabled: false
helper:
image: 'busybox:1.34.1'
pd:
config: |
[log]
level = "info"
[replication]
location-labels = ["region", "zone", "rack", "host"]
service: {}
replicas: 3
image: 'pingcap/pd:v6.5.0'
storageClassName: nfs-client
imagePullPolicy: IfNotPresent
resources:
limits: {}
requests:
storage: 1Gi
affinity: {}
nodeSelector: {}
tolerations: []
annotations: {}
hostNetwork: false
podSecurityContext: {}
priorityClassName: ''
tiproxy:
replicas: 0
storageClassName: nfs-client
baseImage: pingcap/tiproxy
version: v6.5.0
imagePullPolicy: IfNotPresent
resources:
limits: {}
requests:
storage: 1Gi
tikv:
config: |
log-level = "info"
replicas: 3
image: 'pingcap/tikv:v6.5.0'
storageClassName: nfs-client
imagePullPolicy: IfNotPresent
resources:
limits: {}
requests:
storage: 10Gi
affinity: {}
nodeSelector: {}
tolerations: []
annotations: {}
hostNetwork: false
podSecurityContext: {}
priorityClassName: ''
maxFailoverCount: 3
postArgScript: |
if [ ! -z "${STORE_LABELS:-}" ]; then
LABELS=" --labels ${STORE_LABELS} "
ARGS="${ARGS}${LABELS}"
fi
tidb:
config: |
[log]
level = "info"
replicas: 2
image: 'pingcap/tidb:v6.5.0'
imagePullPolicy: IfNotPresent
resources:
limits: {}
requests: {}
affinity: {}
nodeSelector: {}
tolerations: []
annotations: {}
hostNetwork: false
podSecurityContext: {}
priorityClassName: ''
maxFailoverCount: 3
service:
type: NodePort
exposeStatus: true
separateSlowLog: true
slowLogTailer:
image: 'busybox:1.33.0'
resources:
limits:
cpu: 100m
memory: 50Mi
requests:
cpu: 20m
memory: 5Mi
initializer:
resources: {}
plugin:
enable: false
directory: /plugins
list:
- allowlist-1
tlsClient:
enabled: false
mysqlClient:
image: tnir/mysqlclient
imagePullPolicy: IfNotPresent
busybox:
image: 'busybox:1.33.0'
imagePullPolicy: IfNotPresent
monitor:
create: true
persistent: false
storageClassName: nfs-client
storage: 10Gi
initializer:
image: 'pingcap/tidb-monitor-initializer:v6.5.0'
imagePullPolicy: IfNotPresent
config:
K8S_PROMETHEUS_URL: 'http://prometheus-k8s.monitoring.svc:9090'
resources: {}
reloader:
create: true
image: 'pingcap/tidb-monitor-reloader:v1.0.1'
imagePullPolicy: IfNotPresent
service:
type: NodePort
portName: tcp-reloader
resources: {}
grafana:
create: true
image: 'grafana/grafana:6.1.6'
imagePullPolicy: IfNotPresent
logLevel: info
resources:
limits: {}
requests: {}
username: admin
password: admin
config:
GF_AUTH_ANONYMOUS_ENABLED: 'true'
GF_AUTH_ANONYMOUS_ORG_NAME: Main Org.
GF_AUTH_ANONYMOUS_ORG_ROLE: Viewer
service:
type: NodePort
portName: http-grafana
prometheus:
image: 'prom/prometheus:v2.27.1'
imagePullPolicy: IfNotPresent
logLevel: info
resources:
limits: {}
requests: {}
service:
type: NodePort
portName: http-prometheus
reserveDays: 12
nodeSelector: {}
tolerations: []
binlog:
pump:
create: false
replicas: 1
image: 'pingcap/tidb-binlog:v6.5.0'
imagePullPolicy: IfNotPresent
logLevel: info
storageClassName: nfs-client
storage: 20Gi
affinity: {}
tolerations: []
syncLog: true
gc: 7
heartbeatInterval: 2
resources:
limits: {}
requests: {}
drainer:
create: false
image: 'pingcap/tidb-binlog:v6.5.0'
imagePullPolicy: IfNotPresent
logLevel: info
storageClassName: nfs-client
storage: 10Gi
affinity: {}
tolerations: []
workerCount: 16
detectInterval: 10
disableDetect: false
disableDispatch: false
ignoreSchemas: 'INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql,test'
initialCommitTs: 0
safeMode: false
txnBatch: 20
destDBType: file
mysql: {}
kafka: {}
resources:
limits: {}
requests: {}
scheduledBackup:
create: false
mydumperImage: 'pingcap/tidb-cloud-backup:20200229'
mydumperImagePullPolicy: IfNotPresent
storageClassName: nfs-client
storage: 100Gi
cleanupAfterUpload: false
schedule: 0 0 * * *
suspend: false
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
startingDeadlineSeconds: 3600
backoffLimit: 6
restartPolicy: OnFailure
options: '-t 16 -r 10000 --skip-tz-utc --verbose=3'
tikvGCLifeTime: 720h
secretName: backup-secret
gcp: {}
ceph: {}
s3: {}
resources:
limits: {}
requests: {}
affinity: {}
tolerations: []
importer:
create: false
image: 'pingcap/tidb-lightning:v6.5.0'
imagePullPolicy: IfNotPresent
storageClassName: nfs-client
storage: 200Gi
resources: {}
affinity: {}
tolerations: []
pushgatewayImage: 'prom/pushgateway:v0.3.1'
pushgatewayImagePullPolicy: IfNotPresent
config: |
log-level = "info"
[metric]
job = "tikv-importer"
interval = "15s"
address = "localhost:9091"
metaInstance: '{{ $labels.instance }}'
metaType: '{{ $labels.type }}'
metaValue: '{{ $value }}'
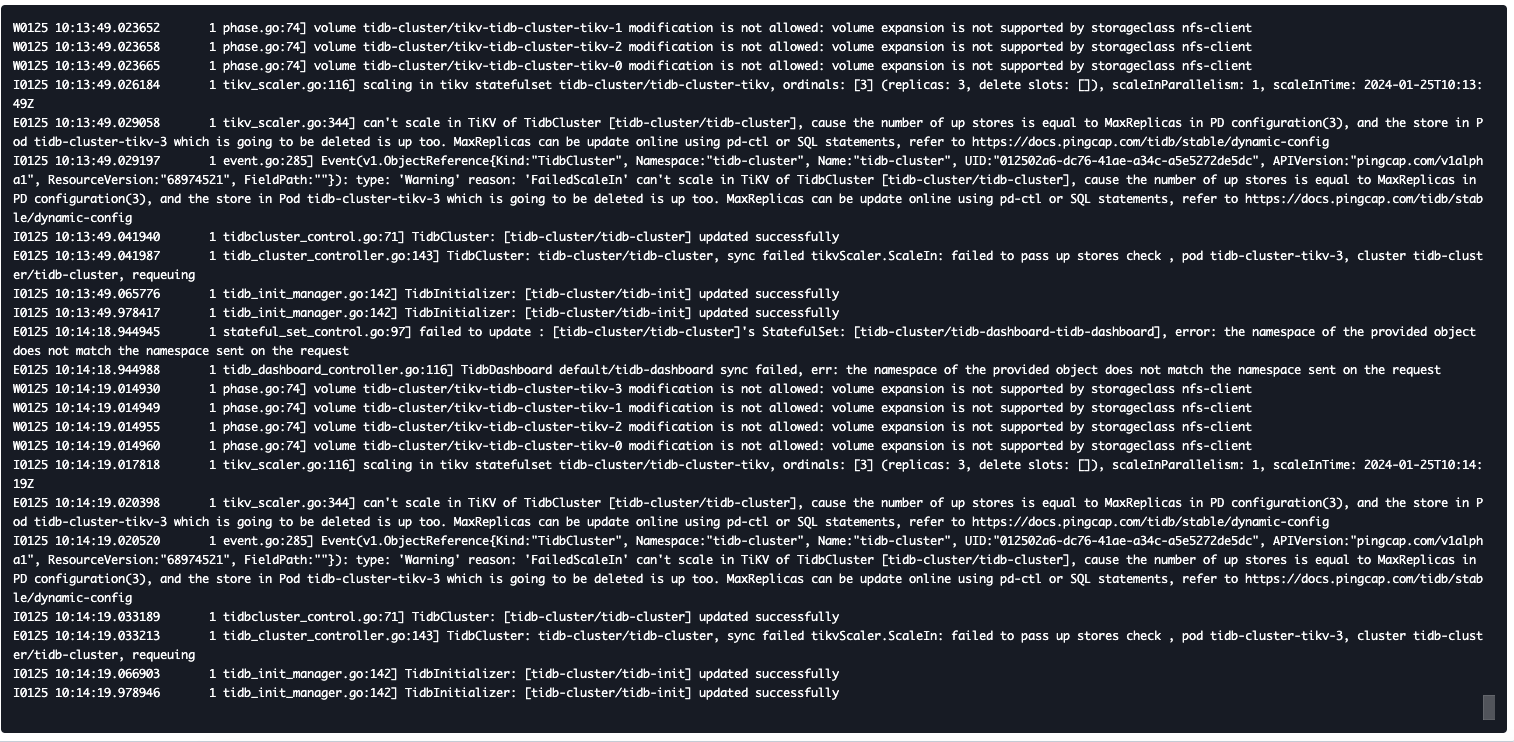
你的tc看起来正常,但是生成的sts不正常。
kubectl get pod -n xxx(operator 的ns)
kubectl logs xxx-contalmanager -n xxx --tail=100 -f |grep xxx
看看operator的日志,看看在干啥
日志没看出来有什么关于版本的信息。
实在不行operator换下版本,换成不带-alpha的版本。
比如说1.5.2
Quino
(Ti D Ber 36 T Ihh Zu)
27
感谢大佬回复
我可以在不停止 tidb-cluster的情况下 直接更换operator吗? 会对线上有什么影响吗?
如果更换了operator版本 tidb-cluster也需要跟着换一下吗?
更换operator版本不更换crd的话,没什么影响。如果删了crd的话,集群就删了。
Quino
(Ti D Ber 36 T Ihh Zu)
30
scheduler 这个不重要,这个就是为了调度用的,尽可能打散tikv的分布。主要干活的是operator,sts是operator根据tidbcluster生成的,你的tidbcluster里写的对,结果sts生成了个latest,这个应该是operator的锅。
Quino
(Ti D Ber 36 T Ihh Zu)
32
感谢大佬 我今晚重新部署一下operator试试看 
Quino
(Ti D Ber 36 T Ihh Zu)
33
大佬 我有一个问题 我可以直接删除带-alpha版本的 operator 部署新的operator 会影响 tidb-cluster集群吗? 这个需要错峰或是晚上更换 还是直接更换就可以呢
tidb 7.5.0版本比较稳定吗 我看到7.1.3是在7.5.0后面出来的
你不用删除operator,直接修改下operator的镜像版本应该就可以。
tidb 7.1.3 是7.1 版本的bug修复。
7.5.0 是是7.5版本。
TiDB 版本的命名方式为 X.Y.Z。X.Y 代表一个版本系列。
Quino
(Ti D Ber 36 T Ihh Zu)
38
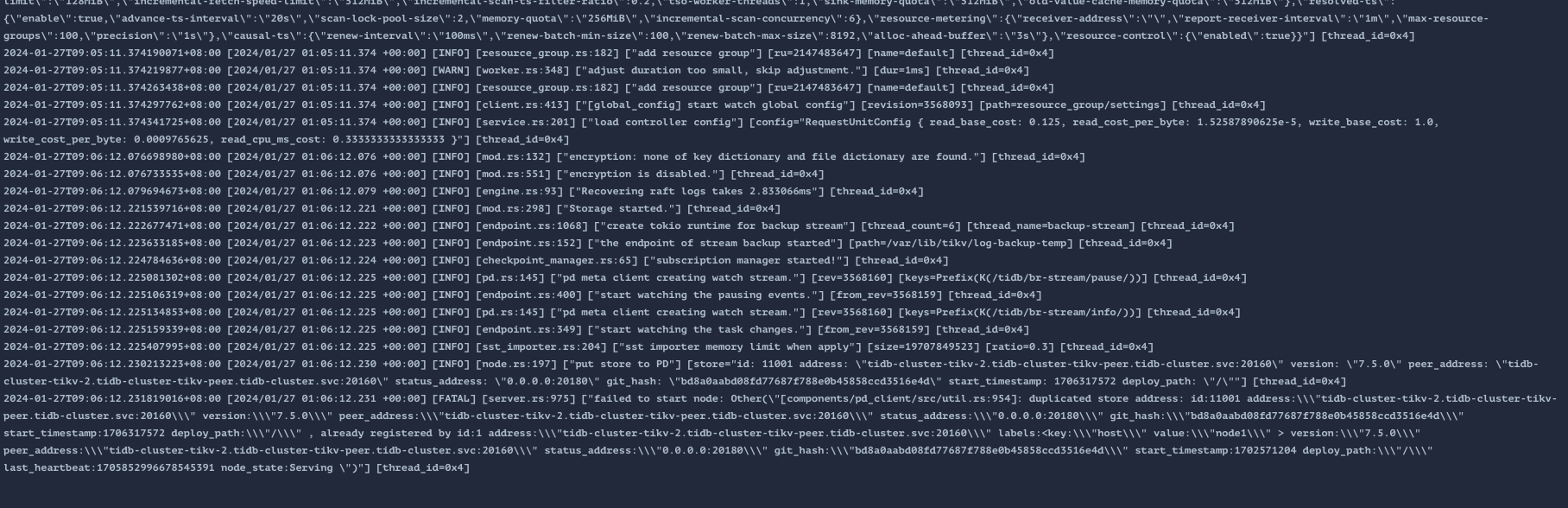
昨晚我重新更换了 operator版本为1.5.2 tikv镜像版本也指定为 v7.5.0 没有那个版本不一致的问题啦 单又出现了新的问题 
[FATAL] [server.rs:975] [“failed to start node: Other("[components/pd_client/src/util.rs:954]: duplicated store address: id:11001 address:\"tidb-cluster-tikv-2.tidb-cluster-tikv-peer.tidb-cluster.svc:20160\" version:\"7.5.0\" peer_address:\"tidb-cluster-tikv-2.tidb-cluster-tikv-peer.tidb-cluster.svc:20160\" status_address:\"0.0.0.0:20180\" git_hash:\"bd8a0aabd08fd77687f788e0b45858ccd3516e4d\" start_timestamp:1706317572 deploy_path:\"/\" , already registered by id:1 address:\"tidb-cluster-tikv-2.tidb-cluster-tikv-peer.tidb-cluster.svc:20160\" labels:<key:\"host\" value:\"node1\" > version:\"7.5.0\" peer_address:\"tidb-cluster-tikv-2.tidb-cluster-tikv-peer.tidb-cluster.svc:20160\" status_address:\"0.0.0.0:20180\" git_hash:\"bd8a0aabd08fd77687f788e0b45858ccd3516e4d\" start_timestamp:1702571204 deploy_path:\"/\" last_heartbeat:1705852996678545391 node_state:Serving ")”] [thread_id=0x4]
这个问题该怎么解决呀 没有头绪
store delete,删掉老的tikv。你这个报错看起来应该是store delete 1