zhanggame1
2024 年1 月 22 日 09:40
1
如果用了分区表,tidb会把每个分区作为一个独立的表进行analyze。问题是每个分区的analyze特别慢如图
上面的例子共有5个步骤:
最后这个非常非常慢,这个分区也就4万条数据。看看能不能优化下
1 个赞
讲实话,tidb对分区表支持的不是特别好,你试一下针对单个分区进行analyze看一下慢不慢
zhanggame1
2024 年1 月 23 日 01:55
3
非常非常慢,和自动分析一样,分区多了这么分析还不如直接analyze 全表
比如手工测试ANALYZE table z_qianyi.win_ticket PARTITION P359025;
这个分区总共16万条数据,全表扫描也就几秒的事。
有个疑问,tidb已经是分布式的了,还有必要做分区表吗?
zhanggame1
2024 年1 月 23 日 04:14
10
分区表参数tidb_auto_analyze_partition_batch_size我试试1调整到100
zhanggame1
2024 年1 月 23 日 09:17
13
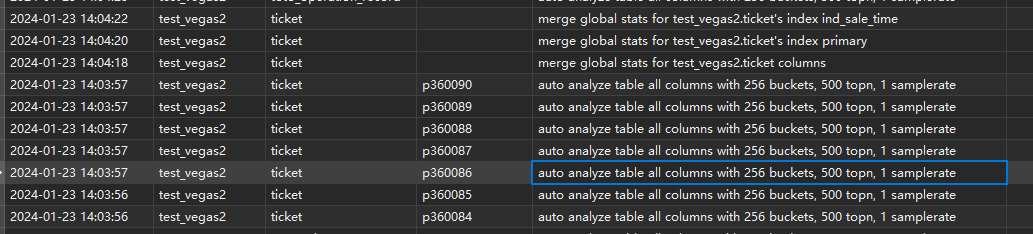
刚才测试了tidb_auto_analyze_partition_batch_size改大应该有明显效果,我直接1改成100了。
根据分析,分区表的分区analyze,对分区做统计是很快的,比如我们数据量小,几秒就完事了,慢在merge global stats for test_vegas2.ticket columns 这步骤上了,多个分区可以公用这个步骤,所以改大效果很好,前提是分区数据量小
1 个赞
有猫万事足
2024 年1 月 23 日 15:27
14
zhanggame1
2024 年1 月 23 日 23:41
15
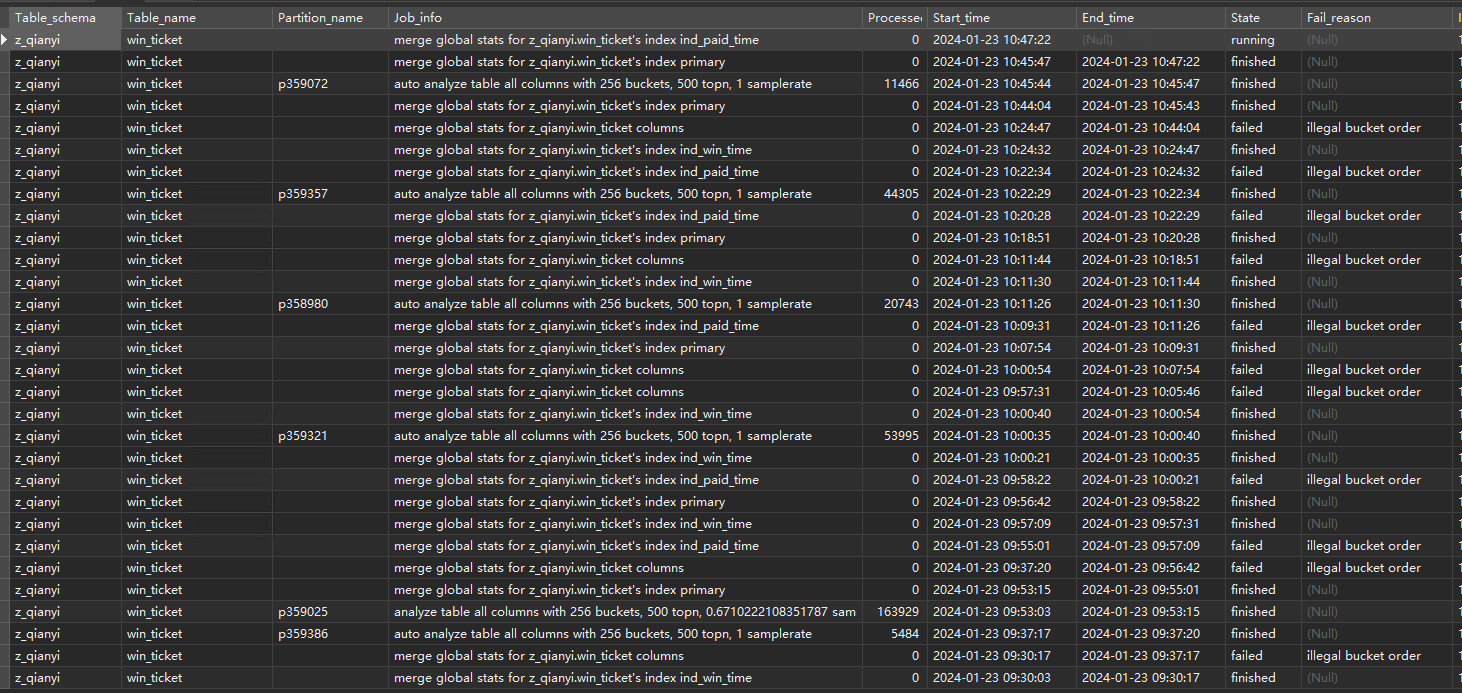
merge global stats 这个步骤执行慢不说,一般都是结果fail
zhanggame1
2024 年1 月 24 日 02:05
18
tidb_merge_partition_stats_concurrency我看有这个参数,可以增加merge并行度
1 个赞
zhanggame1
2024 年1 月 26 日 06:12
20
最后说下研究的结果:
慢的原因是7.5.0版本等有BUG,在merge global stats那一步不但慢,大概率还会failed报错"illegal bucket order"#48713 @hawkingrei
经过部署7.6.0版本测试,7.6.0版本merge global stats不会报错,而且速度快了十几倍
1 个赞