对TiDB的表结构设计一直有个疑问,就是有关主键的设置,什么场景该设置随机主键,什么场景该使用业务主键,什么场景该使用自增主键;
比如
(1)设置了随机主键之后,在大数据量导入数据时比较友好,但是在基于主键拆批删除或者更新时发现因为设置随机主键的原因还是很容易扫全表而导致OOM;
(2)设置了自增主键之后,则在大数据量导入的时候很容易出现热点问题;
(3)设置了业务主键,有些时候业务主键也会因为一些业务主键本身存在连续性、_tidb_rowid本身就是连续性的而导致存在热点问题;
当然也有人说对于有热点问题的主键设计,进行打散和预设Region等操作,但是进行打散和预设Region之后,发现在一些查询的压测测试中发现查询效率有比较明显的下降。
使用 AUTO_RANDOM 处理自增主键热点表,适用于代替自增主键,解决自增主键带来的写入热点。使用该功能后,将由 TiDB 生成随机分布且空间耗尽前不重复的主键,达到离散写入、打散写入热点的目。
TiDB 热点问题处理 | PingCAP 文档中心
根据我的测试,写入性能聚簇表比非聚簇表快不少,主键是不是数字都可以,每增加一个二级索引写入性能会大幅下降。
聚簇表region可以用 Split Region方式打散,参考
Split Region 使用文档 | PingCAP 文档中心
301视频上有详细讲这个
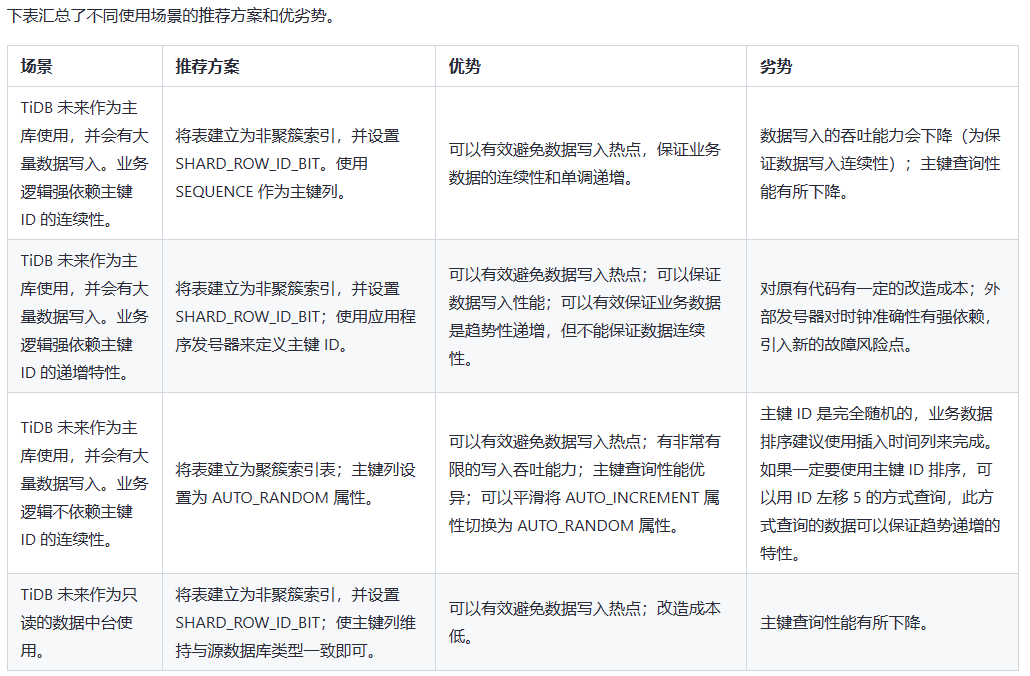
最好的情况下时都用随机主键或者非聚簇表+shard_row_id_bit,对于热点问题解决非常明显,不管是业务主键或者是自增主键,一般都会导致热点问题。
随机主键有助于打散热点是确定的,但是如果设置了随机主键,如果该表需要进行拆批删除,如果是基于随机主键拆批,很容易全表扫描。
聚簇表访问性能也比非聚簇表快,因为可以减少一次回表;增加二级索引意味着写入的数据多了,所以写入会更慢。
哪一节
随机主键如果需要拆批删除,很容易引起全表扫描,该如何避免呢?
主键本身不具备任何业务含义,仅实现唯一不重复即可,如果有业务多加个字段。你的第三个问题就不要考虑,可以考虑随机数,删除的时候可以rownum。
你说的是很老版本了吧,6.5以后聚簇表写入比非聚簇表快不少,sequence性能很差,自增用cahe=1现在优化了快很多
批量删除一般都建议先将key记录下之后按key删除,你key越分散,删的应该越快啊。
分布式数据库不推荐使用自增主键,需要使用自增主键的场景还不如用Mysql。
业务主键我个人觉得不适合取
基本上避免热点就是:
聚簇索引表的情况就用 AUTO_RANDOM来避免热点;
因为 AUTO_RANDOM不支持非聚簇索引表,所以非聚簇索引表情况下就用 'SHARD_ROW_ID_BITS’来避免热点;
其他细节问题需要具体分析了。
按随机主键拆批删除的时候,有些就是因为太过于分散,反而导致扫描的region比较多而最终导致全表扫描。
但是你随机主键的key不就是table_id加主键吗?点查或者范围查比你其他方式的索引回表要更快吧。。。他也不会返回所有的region。。。
个人感觉还是为了解决热点问题