这边看起来像是瓶颈在tikv–>tidb的链路上,能看下grafana上tikv-tidb的 网络状况吗
楼主把问题时段的Grafana监控面板都贴一下,包括tidb和tikv的资源使用情况
另外在Dashboard里也把对应慢SQL的执行耗时图也一起贴上来,目前初步的判断是集群在问题时段tikv层有压力所致
突然特别卡总感觉是网络丢包,看看网络监控
执行时间和查询条件强相关吗?
看看数据分布呢:
select folder_id,count(*) from dms_folder
group by folder_id order by 2 desc;
结合你提供的信息,白天很快,凌晨时候偶尔会慢,可以看下慢的时候是不是这个表正在进行analyze table么?还有就是当时TiKV的整体负载怎么样?
可以调整一下定时计划任务的时间看一下,慢sql的发生时间会不会跟着变。
关注下,慢的时间表有热点没呢
烂 sql 不防丢给 tiflash
主键字段啥类型啊,char还是number,是否发生隐试转换。
一是查一下那个时间系统负载情况,二是查询这个查询的TIKV是否正常
点查能慢成这样基本对应时间点你的集群都不能工作了吧,还是看对应时间点集群的监控,看看负载是不是到极限了






- 是每天3点都这样吗?
- 3点钟开始,有什么定时任务再跑吗?如果有,查查他在干什么,都执行了什么,基本能破案
我觉得应该看一下dashboard的慢查询
之前只看到了这一句,建议把查询范围扩大,排查一下。因为只有sql执行完成才会计入慢查询。另外,这个慢可能是结果,是别的sql导致的。
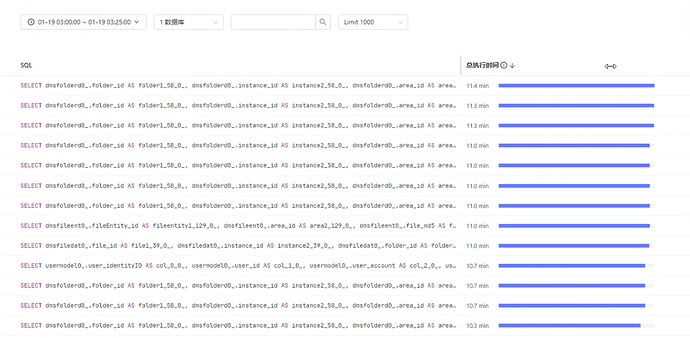
1 个赞
楼主上面说过,他有个定时作业 ![]() 感觉就是这个定时作业的问题。
感觉就是这个定时作业的问题。
1 个赞
这是什么问题,频发跟踪一下sql看看
这个我排查一下吧。我的analyze 定时任务是1点开始,内容只是查询健康度低于80的表,然后进行 analyze ,并且把过程结果输出到日志。这个任务在1点30左右就能完成,这个主要能说明3点左右时候,表的健康度都没有问题。 最主要还是项目上业务的计划任务,目前我们把业务的计划任务停掉之后,就没有类似的问题的。我先扩大慢查询范围看看,看看有没有可能是别的太慢的影响到了。
这个不能算烂sql,已经是最简单的sql了 看where后边的东西 前面都可以忽略
根据你的监控图,重点排查下3点-4点半的cpu,io,带宽,最最主要的是业务有啥操作(或者你不知道的定时任务),可以通过慢日志辅助追踪
首先执行计划 监控看到对应时间的点backoff 重试次数过多,另外你还有定时任务在跑,所以我觉得方向几个方向
1.调整定时任务时间,来确定是不是定时任务导致的
2.如果上面调整了还是和原来一样,那可以从backoff的角度去排查吗,为什么重试多次,查看对应的监控指标