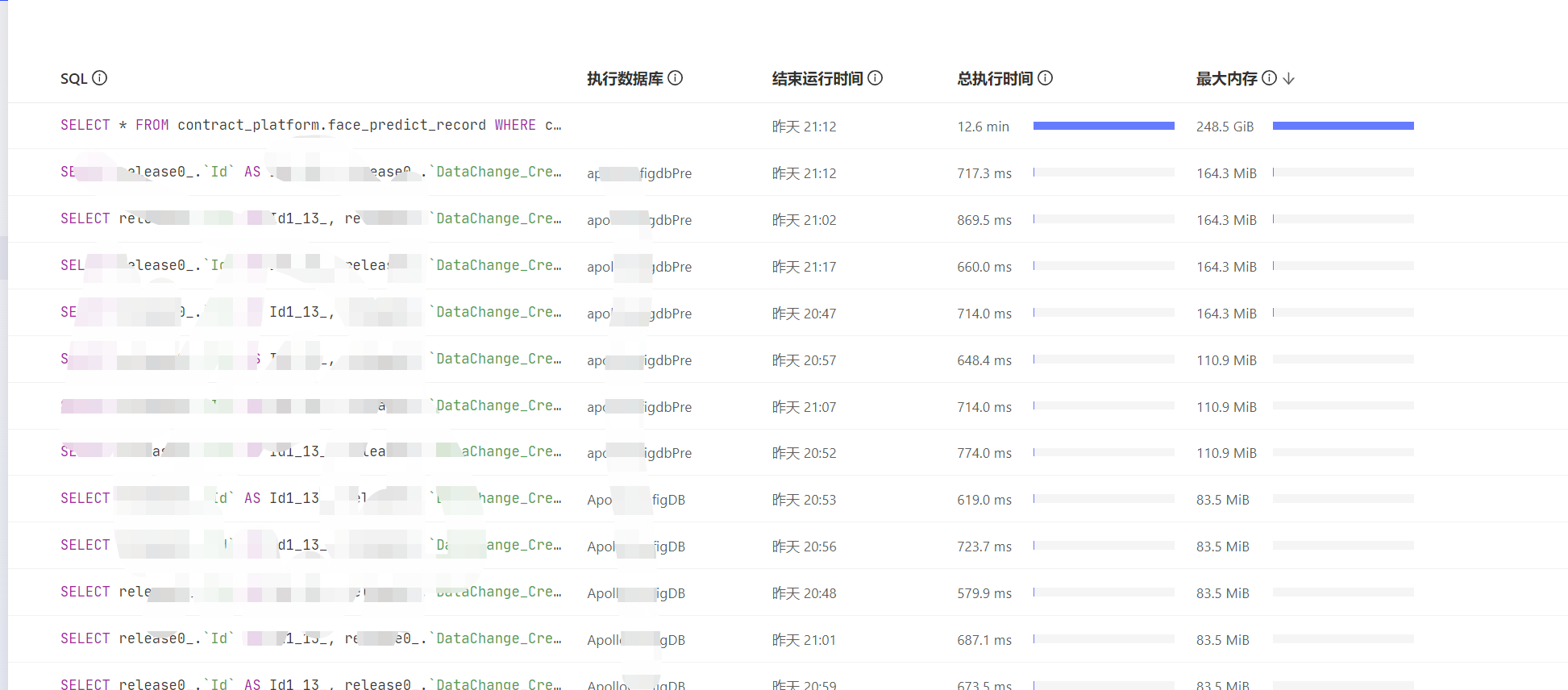
昨天晚上21:00点左右对一个全表1.2T 的数据进行分时间段备份,发现内存几乎消耗殆尽,但是看执行sql 最大使用内存是248G 左右,服务器内存512G,改服务器上只部署了一个tidb 节点,查看监控发现有个heaplnuse内存使用率也很大,想问下这部分指标是什么意思
堆内存。process 是进程内存。
前者可以简单认为是 tidb 实际需要内存。进程内存会包涵其他还有没有 gc 的内存。
不能分批备份吗?
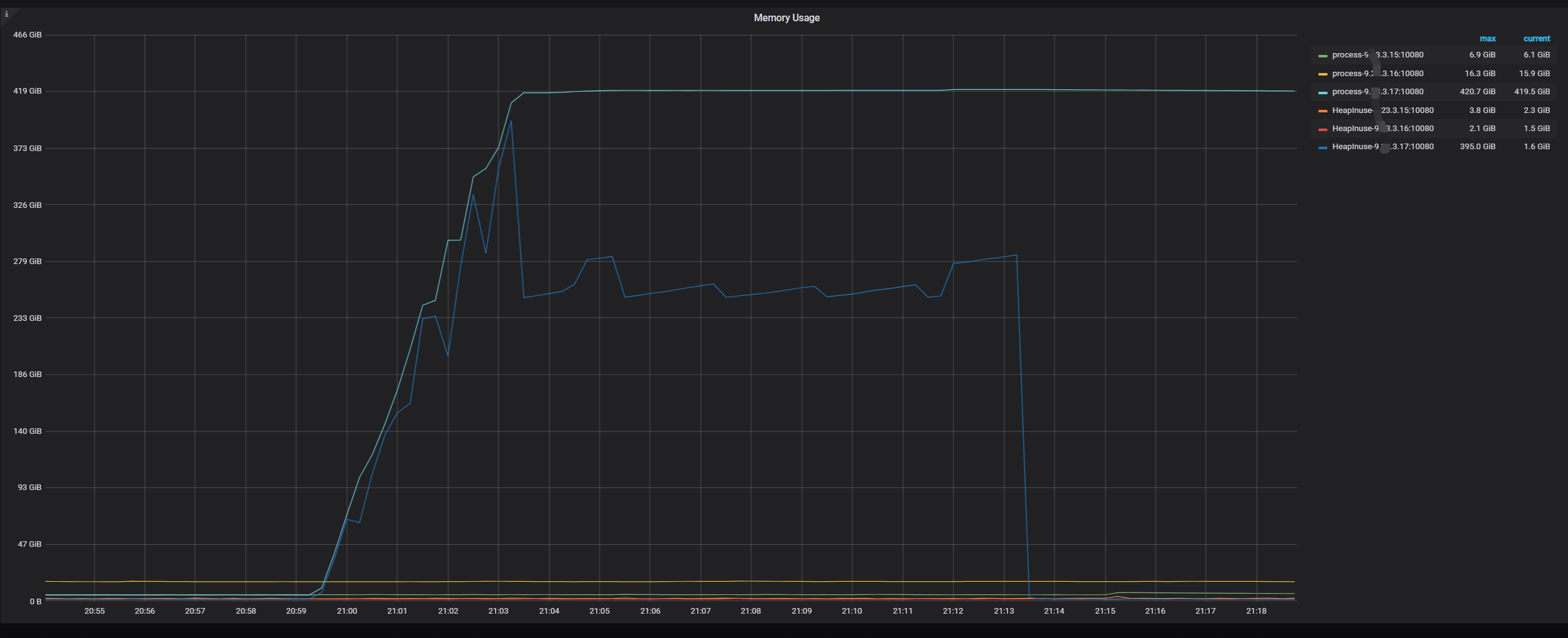
最大占用内存248.5GB竟然没有OOM ![]()
不要用 sql, 用 dumpling --where 指令试试。
服务器数据库内存总的使用了大约420G,单个SQL只使用了248G
这张表全表数据量1.2T ,这次备份大约有400G左右 就是按照时间进行备份的 --sql"select * from t where createdata<‘2024-01-01’ " 符合条件的数据是12.25–1.1号之间的数据
好的,那这条sql耗费的内存确实也太大,是不是和跨网络有关系,一个是北京的服务器一个是上海的服务器,客户端是北京网段的,数据库是上海网段的
想导出来csv 格式的,–where 只能导出sql模式的吧?
可以把where放到筛选sql里,不就可以用csv么
你们的tidb_mem_quota_query 配置的是多少,200多g的sql居然没有超过阈值
可以把这个大的任务拆分成几个小任务执行,反正都是生成csv文件最后合并就行,还有就是where条件的字段要有索引。
是的 where 条件 有索引,之前也导出过数据但是导出的是sql 模式的,没有这么大的内存使用率,

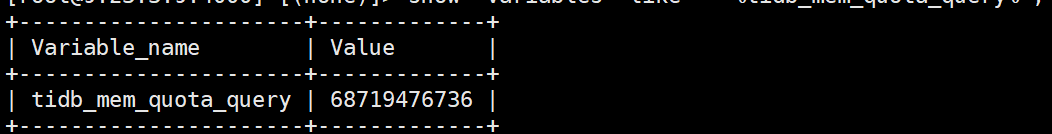
可以在本地导排除一下 ![]()

–params “tidb_enable_chunk_rpc=0” 加这个试试
不是吧 --where 应该也是可以导出 csv 的。
–where dumpling 会对 SQL 进行自动拆批
–SQL 的话是执行 SQL 流式处理数据,如果写的过慢会导致内存占用较大的,甚至 OOM。