【 TiDB 使用环境】生产环境
【 TiDB 版本】7.2
【复现路径】在1000左右的并发下sql执行耗时大10s以上
【遇到的问题:问题现象及影响】
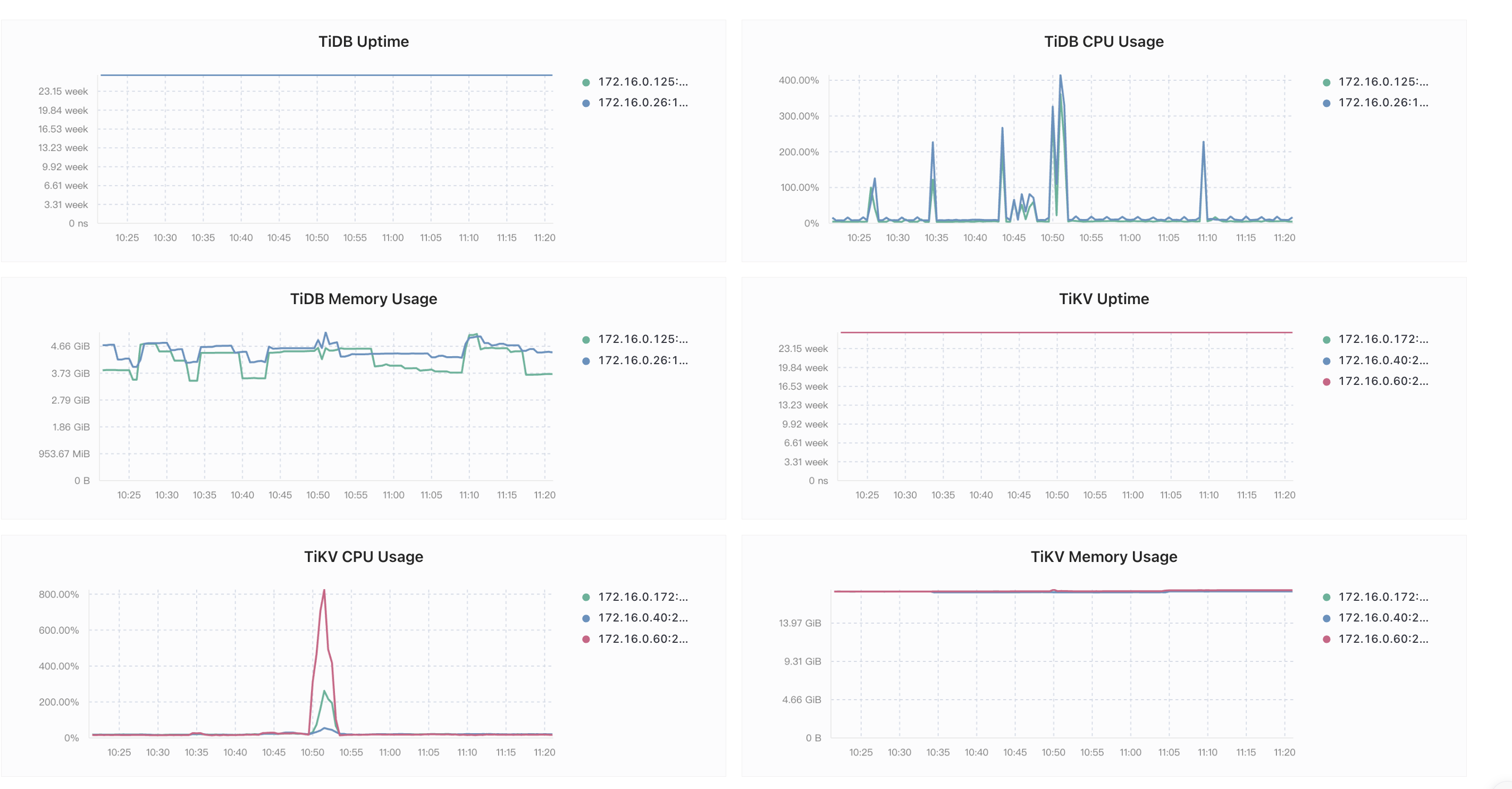
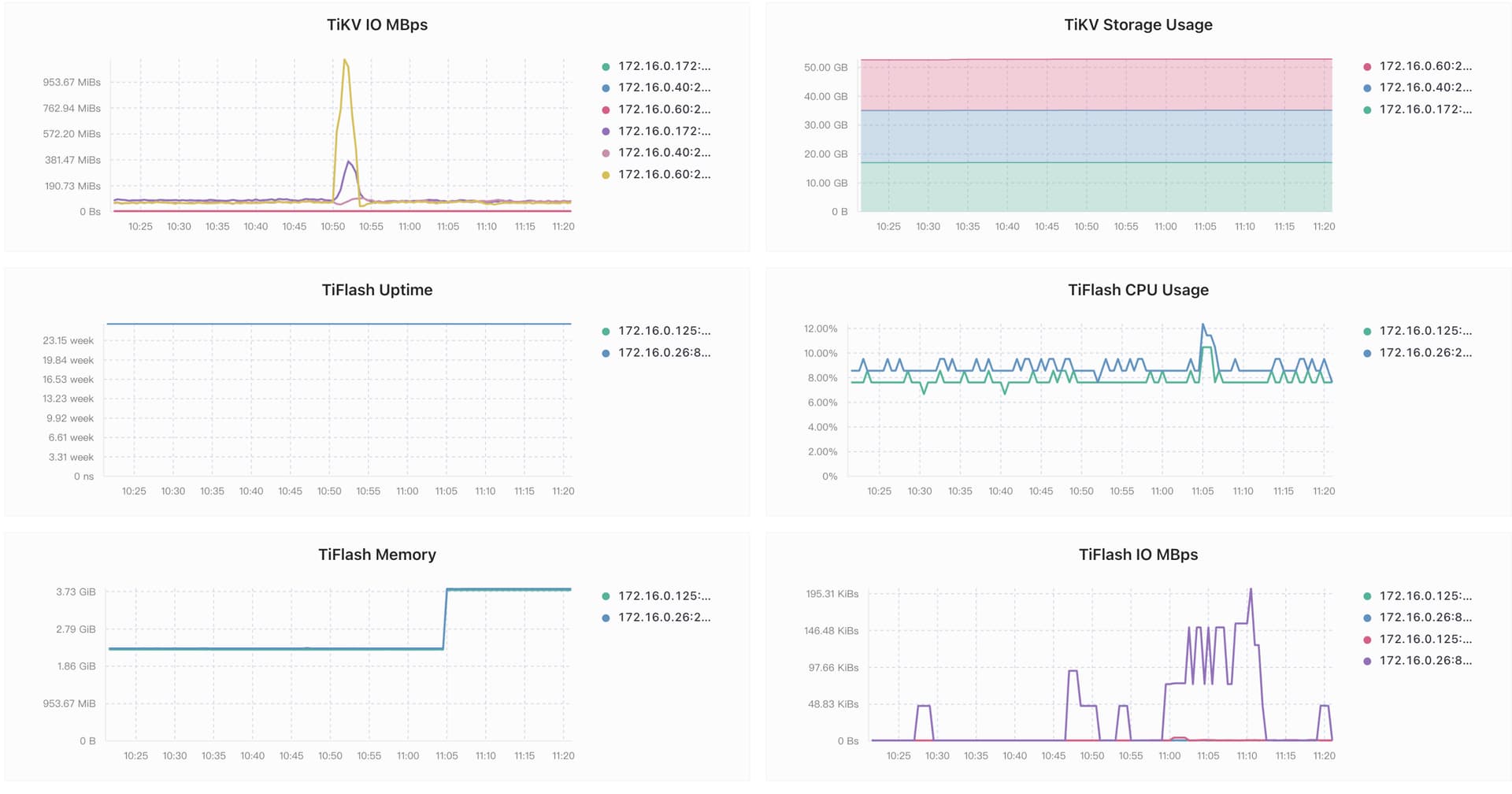
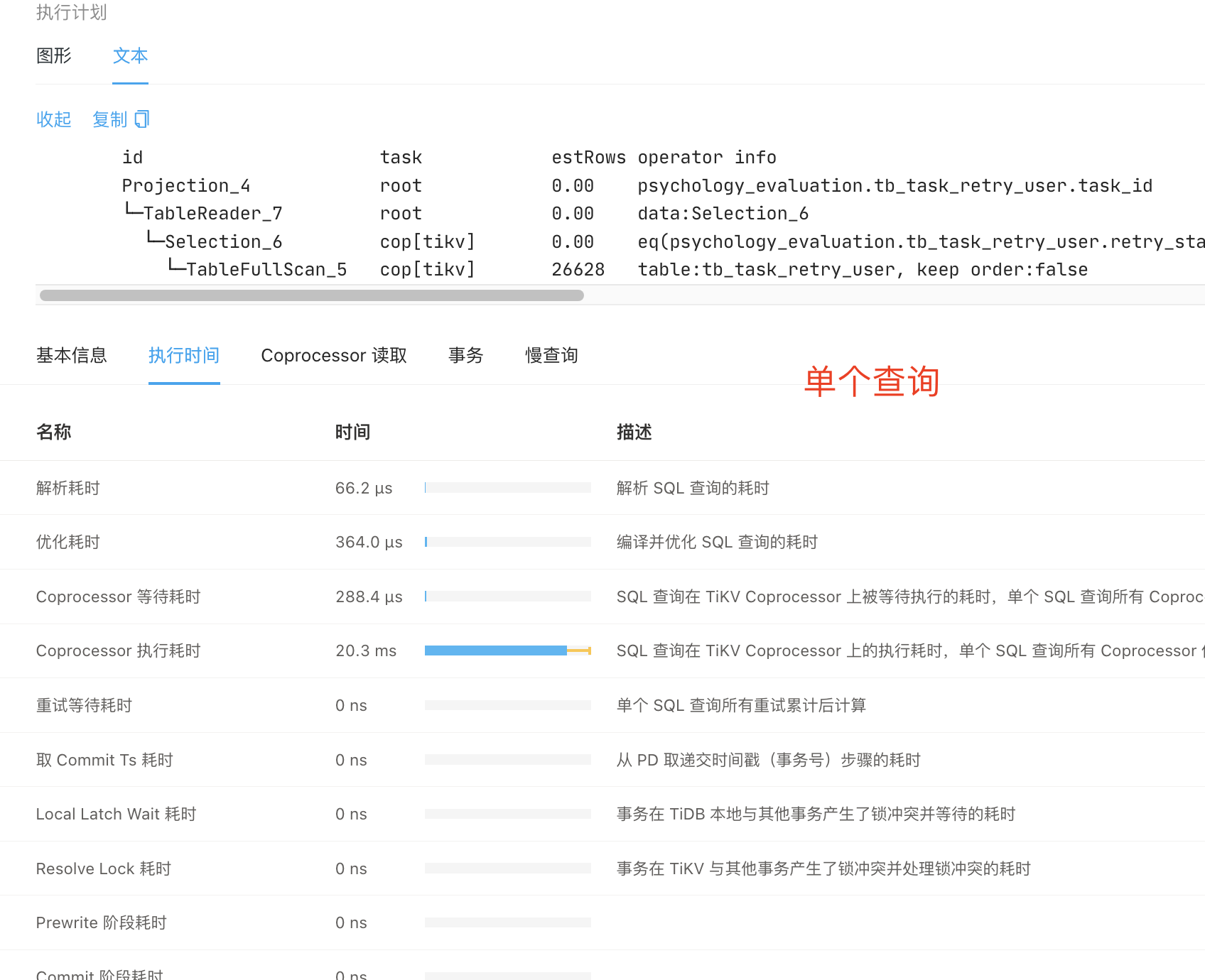
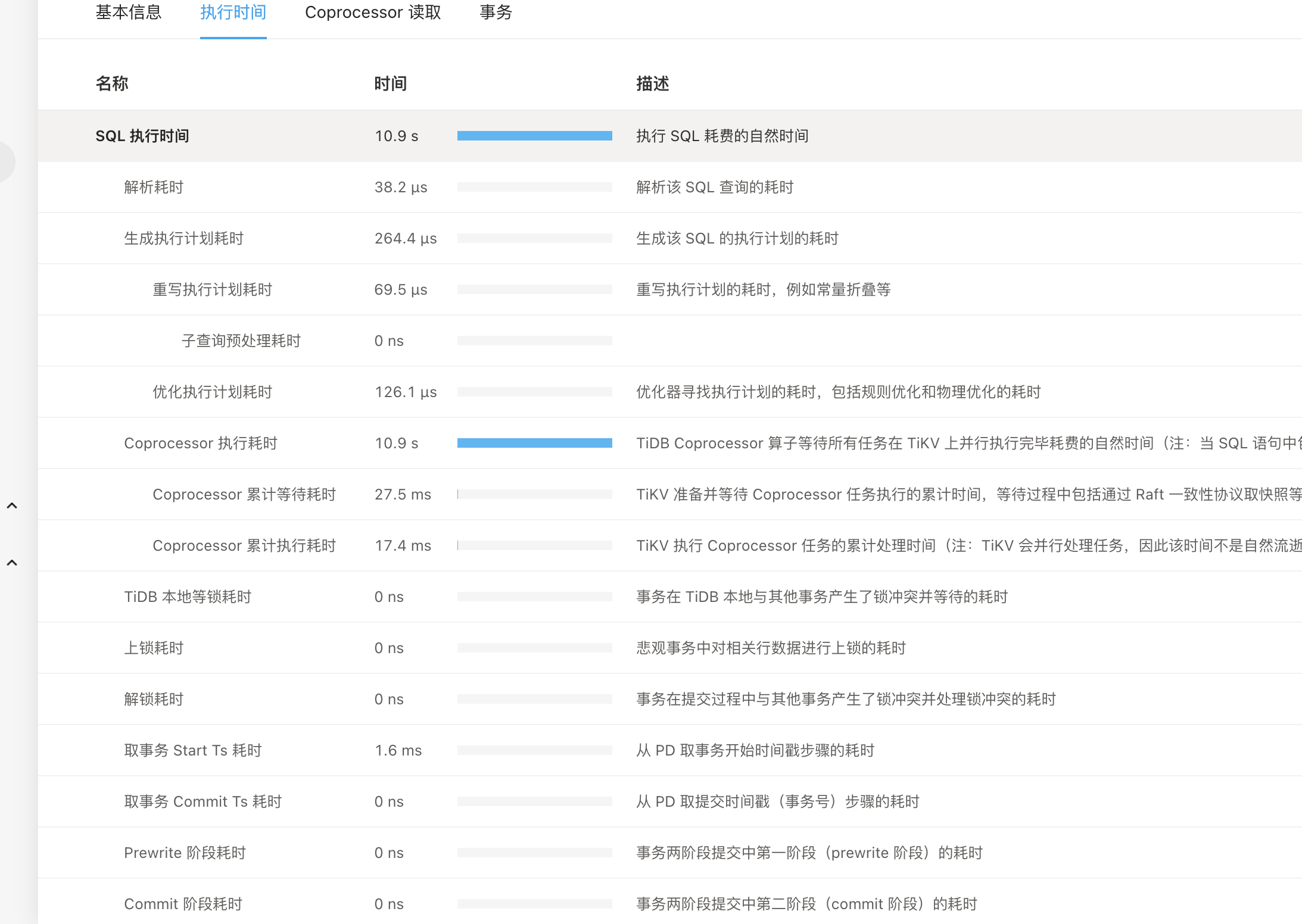
当前由于sql耗时时间较长导致并发量达不到预期值,所以请求大佬帮忙,信息如下图
【资源配置】
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】7.2
【复现路径】在1000左右的并发下sql执行耗时大10s以上
【遇到的问题:问题现象及影响】
当前由于sql耗时时间较长导致并发量达不到预期值,所以请求大佬帮忙,信息如下图
【资源配置】
【附件:截图/日志/监控】
1.不知道你并发高的时间点是什么时候,是监控图里的高峰段吗?
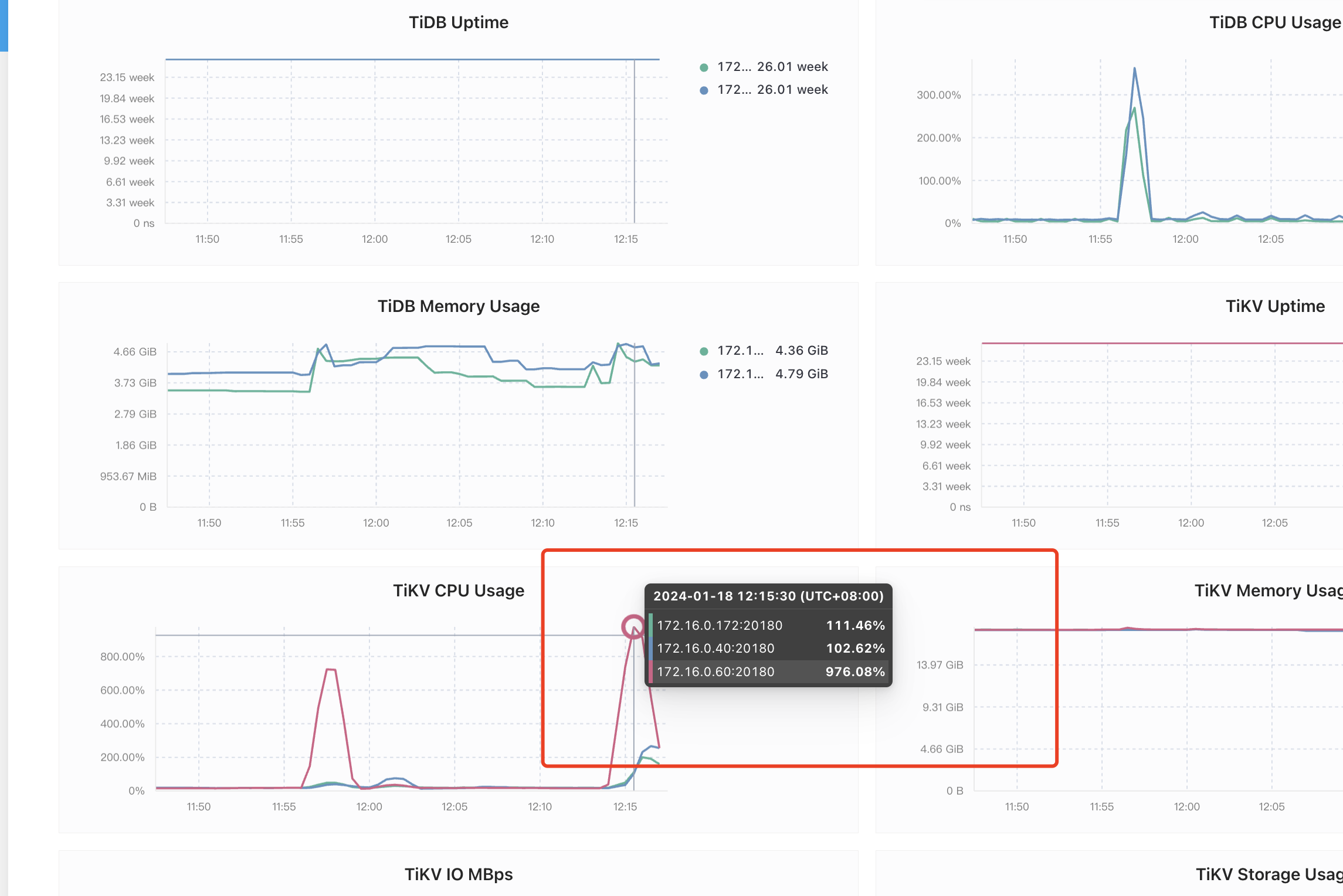
如果是的话,看你的tidb和tikv个别节点的cpu分别到了400%和800%,另外tikv的io也是有个别节点偏高,可以考虑数据热点的问题,同时注意并发高时间段cpu和磁盘io是否有瓶颈。
2. 高并发的操作是什么?读还是写,那个sql是高并发的语句吗?
另外,7.2不是LTS, 建议使用LTS版本
1000并发?你TiDB配置咋样,SQL是什么类型SQL,集群资源使用率如何,现在tikv的读线程池是不是满了?
非常感谢大佬回答
版本问题我们近期会升级到7.5的
您说的读线程池在上面地方可以监控到呢或者在什么地方可以配置呢?
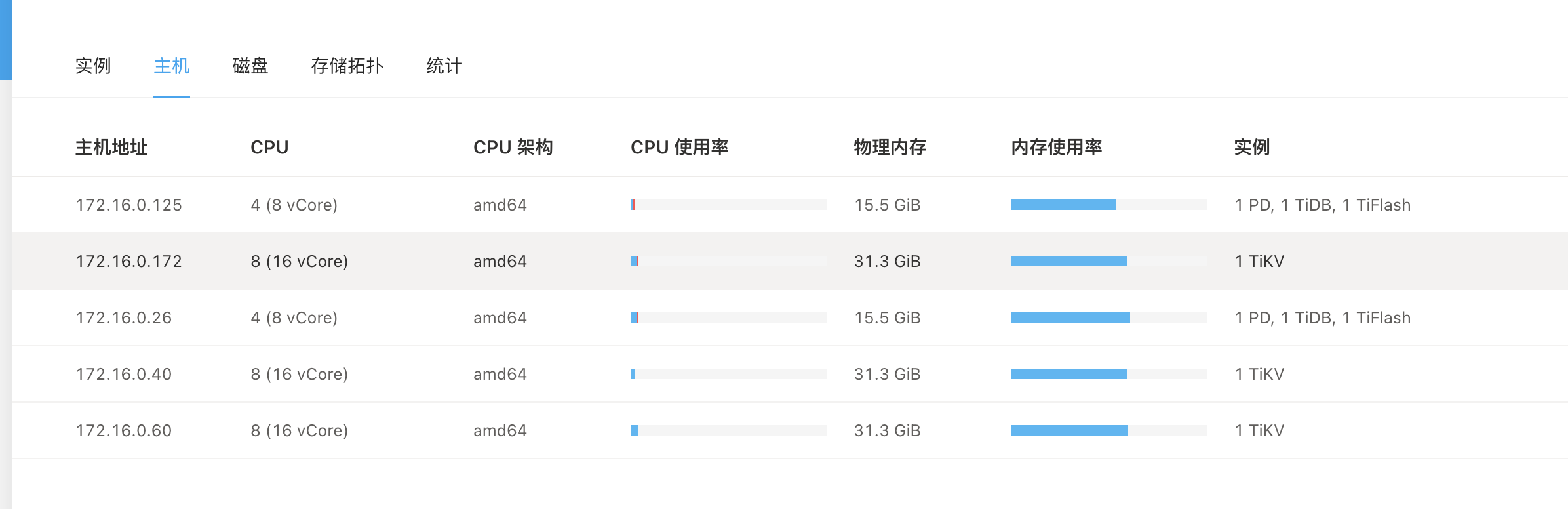
集群搭建有点奇怪,为啥要把TiDB和TiFlash节点放在同一台机行,而且这台机的内存更少,TiFlash本身就比较耗内存,这样不是更加容易导致TiDB内存不够,更容易OOM吗?
可以查下该SQL的执行计划是否改变,高并发和并发低的时候执行计划是否一致
哦哦,是的,第一次使用tidb好多地方都没有整明白,正在学习中,后面我们根据测试报告再进行重新分配
1、看着Coprocessor的执行时间前后差不多,只是Coprocessor的等待时间有明显增加,对比下两者执行计划中的execution info中的各种时间指标,看看那个指标的时间有明显不一致;
2、此外看下Grafana中的TiKV面板,看看主要是什么导致CPU使用率明显升高。
具体情况具体好样的。
并发执行时时间占用长很正常,要检查并发是否存在冲突,SQL是否使用了合适的索引,是否存在不合理的大事务等
建议检查索引
看看sql执行计划,是否走索引,可以将并发设置为500看看效果。
看下tikv的读线程配置情况
还是资源不够,PD和TIDBserver和tiflash分开要好一些。