【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
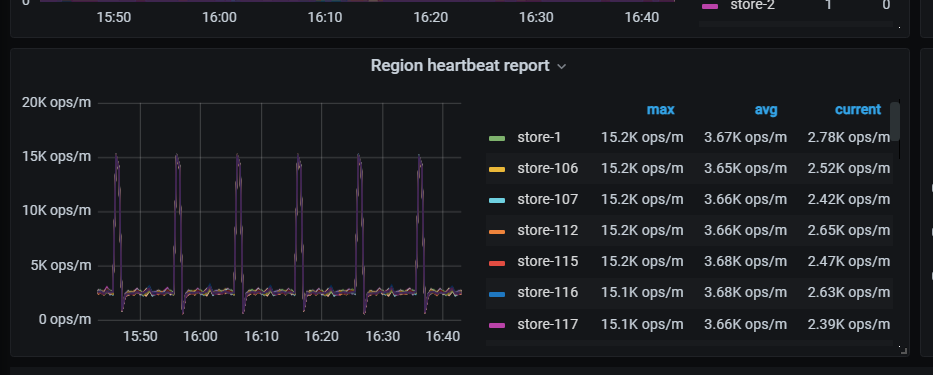
应该没问题吧。
假的:心跳,就是一跳一跳的 ![]()
真的:高版本默认开启了静默region,但是静默的region会被gc唤醒,GC interval间隔默认10分钟,可以通过对比gc相关监控面板佐证。
参考:
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#hibernate-regions
1 个赞
我去了解一下,谢谢
心跳发送的量和集群的数据规模紧密相关,请问集群的总数据量和region, region leader的值大概是多少?
心跳就是这样的,要不怎么叫心跳
说的很有道理,我赞同这个观点 ![]()

这心跳10分钟一次非常规律啊挺好的,哪天变直线了才会有问题。
忽高忽低,这正常?
关键是2.7跳到15k+这正常?

这个最大值和每个kv上的region leader数能匹配上。
集群没问题我觉的问题就不大
间隔10分钟,是GC默认的时间,很规律,没啥问题啊
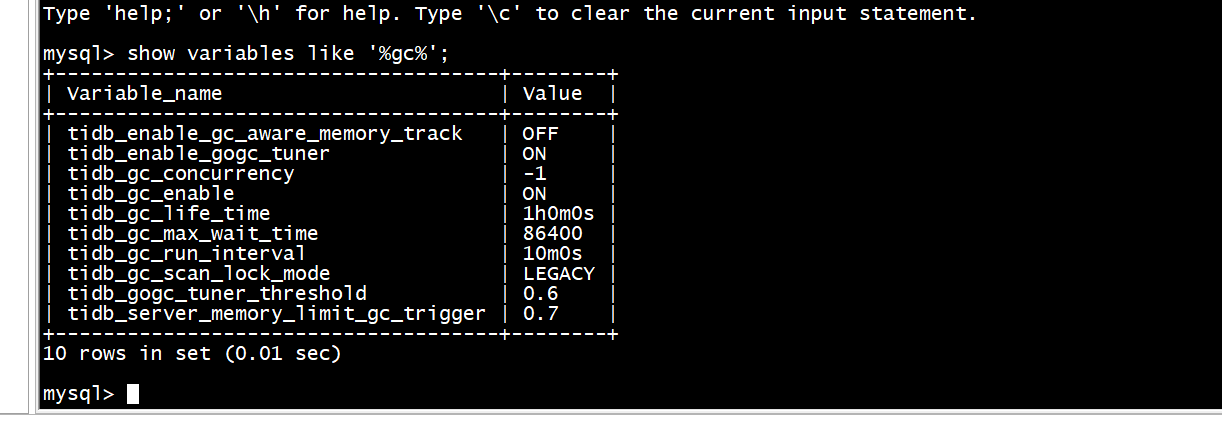

tidb_gc_run_interval:指定垃圾回收 (GC) 运行的时间间隔
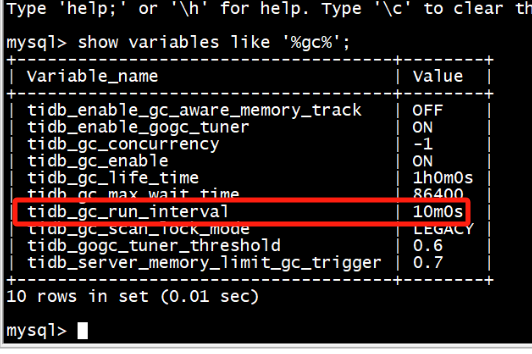
是不是GC导致region的数量变化导致心跳显示有异常?
1 个赞
https://docs.pingcap.com/zh/tidb/stable/massive-regions-best-practices
在 Region 数量较多的情况下,Raftstore 需要花费一些时间去处理大量 Region 的心跳,从而带来一些延迟,导致某些读写请求得不到及时处理。如果读写压力较大,Raftstore 线程的 CPU 使用率容易达到瓶颈,导致延迟进一步增加,进而影响性能表现。
在实际情况中,读写请求并不会均匀分布到每个 Region 上,而是集中在少数的 Region 上。那么可以尽量减少暂时空闲的 Region 的消息数量,这也就是 Hibernate Region 的功能。无必要时可不进行 raft-base-tick,即不驱动空闲 Region 的 Raft 状态机,那么就不会触发这些 Region 的 Raft 产生心跳信息,极大地减小了 Raftstore 的工作负担。
Hibernate Region 在 TiKV master 分支上默认开启。可根据实际情况和需求来配置此功能的开启和关闭 ,请参阅配置 Hibernate Region。
hibernate-regions
- 打开或关闭静默 Region。打开后,如果 Region 长时间处于非活跃状态,即被自动设置为静默状态。静默状态的 Region 可以降低 Leader 和 Follower 之间心跳信息的系统开销。可以通过
peer-stale-state-check-interval调整 Leader 和 Follower 之间的心跳间隔。 - 默认值:v5.0.2 及以后版本默认值为 true,v5.0.2 以前的版本默认值为 false
2 个赞