舞动梦灵
(Ti D Ber Nckmz Hmh)
1
有个情况,前端支付成功,会有一个更新状态的sql执行。每天都有十几条更新状态的sql提示写冲突,
更新sql是更新主键的,而且tidb内部的更新操作其实就是isnert一条新数据。
开发也调查了这条sql当时执行的时候这个更新的主键id 没有其他任何操作。这个问题应该从哪里排查
sql:
update table_pay
MERCHANTID = #{merchantid,jdbcType=VARCHAR},
PM_PARK_ID = #{pmParkId,jdbcType=VARCHAR},
········十几个if判断
CREATED_TIME = #{createdTime,jdbcType=TIMESTAMP},
where ID = #{id,jdbcType=CHAR}
报错信息:
运行时异常[Exception],异常信息:Could not commit JDBC transaction; nested exception is java.sql.SQLException: Write conflict, txnStartTS=446916360684437510, conflictStartTS=446916359989755947, conflictCommitTS=446916360684437536, key={tableID=134, handle=916307} primary={tableID=134, handle=916307} [try again later]
舞动梦灵
(Ti D Ber Nckmz Hmh)
3
但是开发说当时那一个时间,这个主键只有一个更新操作没有其他操作
首先出现这个报错,一定是因为写事务冲突导致的,即多个事务都对同一行数据进行修改时遇到的写冲突报错。这种情况几乎都是业务侧重复写入导致的问题。
可以确认下集群是不是使用乐观锁,在集群内部事务重试的时候,业务是否也有重复插入。
另外,确认一下更新主键的sql是不是被包含在一个更大的事务里。
1 个赞
舞动梦灵
(Ti D Ber Nckmz Hmh)
6
他们已经确认,这是update更新操作出现的写冲突。是不是一个更大事务我去确认一下。数据库默认不是悲观锁吗。这是4.0.9版本。我看官网是从3.x版本开始默认悲观锁
他的业务逻辑是,这是停车场出场的时候udpate更新支付状态。支付成功之后。更新支付状态。然后停车场抬杆,结果写冲突。更新支付状态这个sql写冲突了。然后就是支付成功了。因为没有更新支付状态所有没有抬杆,
随缘天空
(Ti D Ber Ivw R7o Pj)
7
程序层面最好加一个锁机制吧,数据库估计使用了乐观锁
1.关于使用悲观锁的情况。
自 v3.0.8 开始,新创建的 TiDB 集群默认使用悲观事务模型。但如果从 v3.0.7 版本及之前创建的集群升级到 >= v3.0.8 的版本,则不会改变默认的事务模型,即只有新创建的集群才会默认使用悲观事务模型 。
2.建议提供一下脱敏的、完整业务事务SQL,或者程序处理逻辑,并发情况。
3. 锁冲突发生的时候,你要先确认集群的事务是乐观还是悲观的。查看集群健康和系统表等信息:
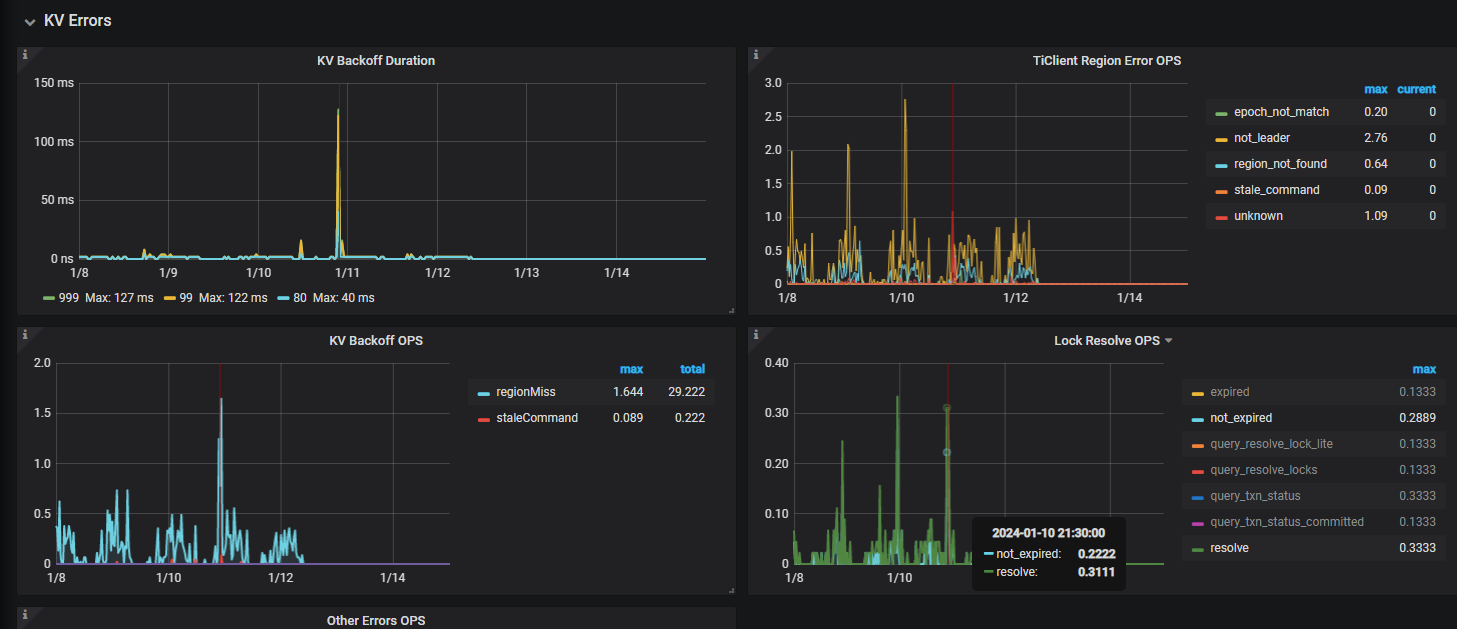
1)通过 TiDB Grafana 监控分析观察 KV Errors 下 Lock Resolve OPS 面板中的 not_expired/resolve 监控项以及 KV Backoff OPS 面板中的 txnLockFast 监控项,如果有较为明显的上升趋势,那么可能是当前的环境中出现了大量的事务冲突。其中,not_expired 是指对应的锁还没有超时,resolve 是指尝试清锁的操作,txnLockFast 代表出现了读写冲突。
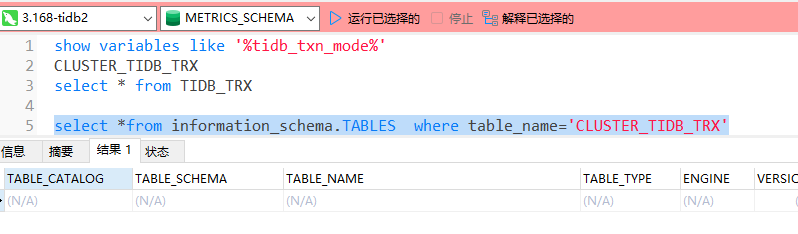
2)系统表TIDB_TRX 与 CLUSTER_TIDB_TRX 提供当前 TiDB 节点上或整个集群上所有运行中的事务的信息,包括事务是否处于等锁状态、等锁时间和事务曾经执行过的语句的 Digest 等信息。
1 个赞
舞动梦灵
(Ti D Ber Nckmz Hmh)
11
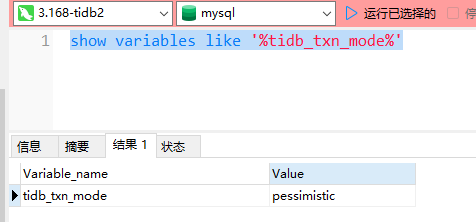
1.不是升级的直接4.0.9安装的。是默认悲观锁
2.开发发给我的完整更新sql,完整事务还没确认,开发昨晚加班上线,下午才能到
update ipsp_union_pay
MERCHANTID = #{merchantid,jdbcType=VARCHAR},
PM_PARK_ID = #{pmParkId,jdbcType=VARCHAR},
CAR_NUMBER = #{carNumber,jdbcType=VARCHAR},
AMOUNT = #{amount,jdbcType=INTEGER},
PAY_ORDER_ID = #{payOrderId,jdbcType=VARCHAR},
PARK_ORDER_ID = #{parkOrderId,jdbcType=VARCHAR},
UNION_ORDER_ID = #{unionOrderId,jdbcType=VARCHAR},
SEND_TIME = #{sendTime,jdbcType=TIMESTAMP},
RECV_TIME = #{recvTime,jdbcType=TIMESTAMP},
PAY_STATE = #{payState,jdbcType=CHAR},
FAIL_DESC = #{failDesc,jdbcType=VARCHAR},
SUCCESS_TIME = #{successTime,jdbcType=TIMESTAMP},
RESERVED = #{reserved,jdbcType=VARCHAR},
QUERY_TIMES = #{queryTimes,jdbcType=INTEGER},
LAST_QUERY_TIME = #{lastQueryTime,jdbcType=TIMESTAMP},
CALL_BACK_STATE = #{callBackState,jdbcType=CHAR},
CALL_BACK_COUNT = #{callBackCount,jdbcType=INTEGER},
CALL_BACK_LAST_TIME = #{callBackLastTime,jdbcType=TIMESTAMP},
CONFIG_VERSION = #{configVersion,jdbcType=VARCHAR},
CREATED_TIME = #{createdTime,jdbcType=TIMESTAMP},
where ID = #{id,jdbcType=CHAR}
3.
3.1 监控里面看有对应时间起伏明显的趋势,但是数据感觉不是很大
3.2你说的这两个表是大版本才有的吗
开发的话一个标点符号都不能信,这么明显的锁冲突开发都不认的么
1 个赞
舞动梦灵
(Ti D Ber Nckmz Hmh)
13
对,肯定是他们的问题,我查了社区另外一个文档,三种可能性,我觉得还是他们逻辑有问题,
1, 乐观锁与悲观锁 混合使用
2 。 查看数据库代理层介入,是否存在链接复用,链接窜用,看对应时间点是否有错误日志
3 数据库本身bug
system
(system)
关闭
16
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。