https://docs.pingcap.com/tidbcloud/v7.5.0-performance-benchmarking-with-sysbench
官方测的这个sysbench read write结果感觉差出边际去了,是数据搞错了吗?
发下硬件配置
机器配置和集群拓扑发出来
你不会和我一样,用三个烂机器混合部署带机械盘压的吧,那可能也只能这样了。。。。
你是不是来捣乱的,配置也不发。
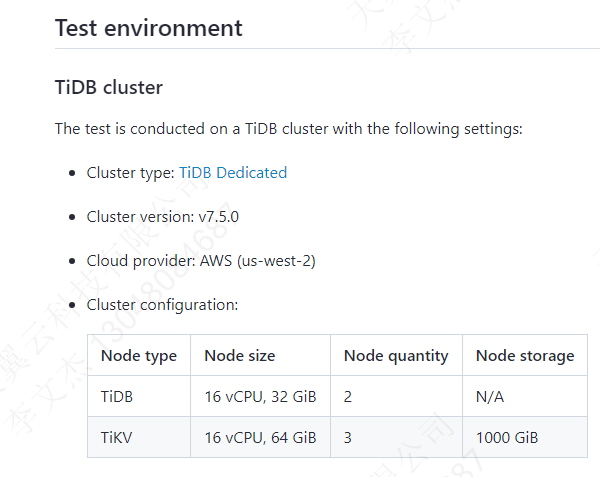
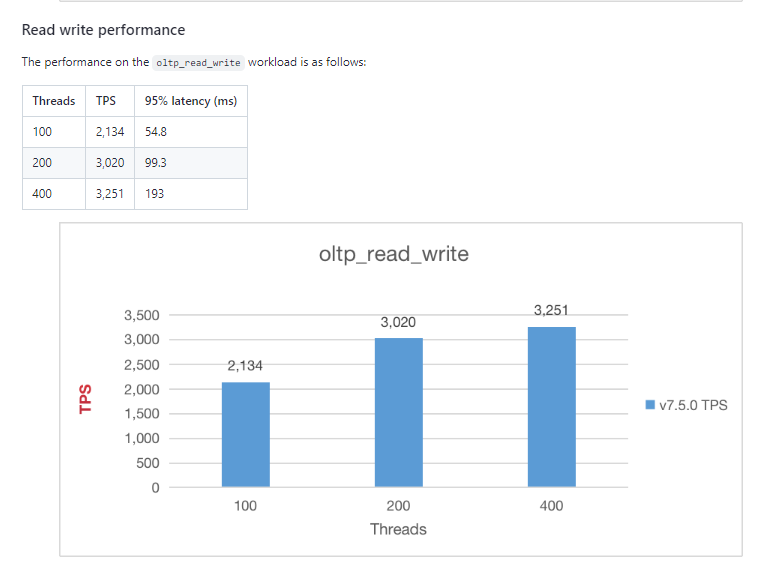
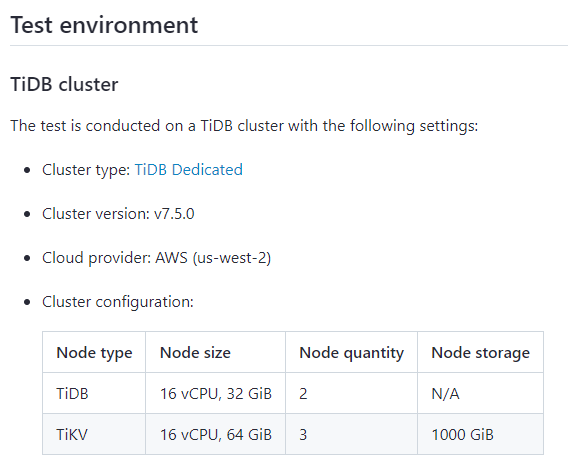
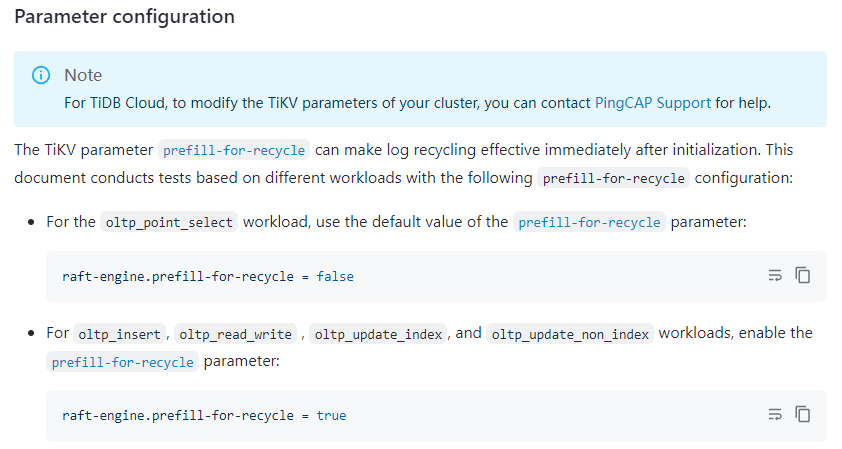
官方的这个测试结果,是基于这样的一个 cloud 配置测试的,是预期中的结果,注意,这个是混合了查询与写操作的 TPS,是每秒钟执行的事务数。
如果你只看point_select 在这个资源配置下,可以到十几二十万,纯写也会有大几万。
如果换做资源更高的配置来测试,各项数值也可以提升。
2 个赞
怎么看出来差的?
部署机器配置跟拓扑发出来看看的
不是应该很好的吗?
分布式对网络要求很高的
这标题有点大了,单机同配置可能比mysql查,标准配置大数据量肯定要好
大家应该是误会了。
楼主没有自己测试,只是认为oltp_read_write结果比oltp_point_select低很多?建议分析下不同测试模式对应lua脚本。
1 个赞
要看你的机器数量和对应的硬件配置,还有拓扑文件配置信息
大家确实有点误会了,这个测试报告是官方测的,不是我测的。
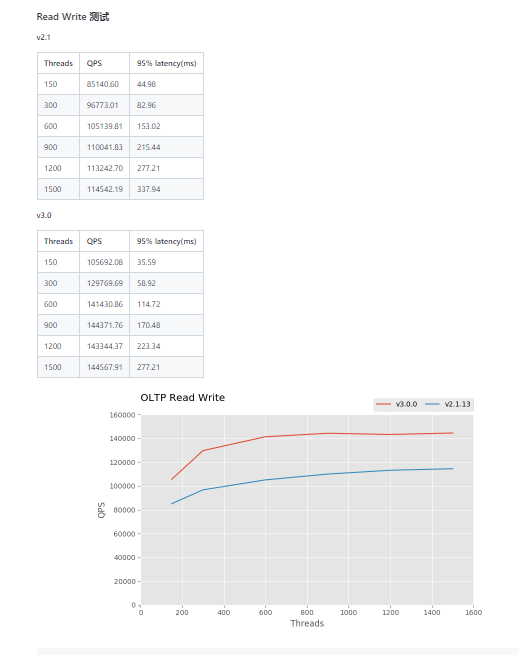
机器看起来是直接使用的tidb cloud。截图是直接官方报告里的内容。里面点查的性能还不错,但是oltp_read_write是异常的差呢,所以怀疑是不是官方的数据搞错了?
感觉找到答案了,oltp_read_write这项测试内容应该是比较复杂,一个事务掺杂了很多不同操作,会导致tps比qps低很多。
官方报告里结果记录的是tps,以前有的报告和一些别人家的报告都用的qps。
3.0的测试报告
oceanbase的测试报告

为了不误导其他人,我把标题改了一下。
这个应该跟配置有关吧
对的,所以看测试报告需要特别注意横坐标和纵坐标、数值单位等,不然容易出现楼主的情况
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。