为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】使用kyuubi + tidb模式下,如何使用 insert into 、insert overwrite
【应用框架及开发适配业务逻辑】
【背景】
采用kyuubi + tispark + tidb 做数据处理
【现象】
这两种情况下会有主键问题报错,


这种insert到无主键表是正常的。
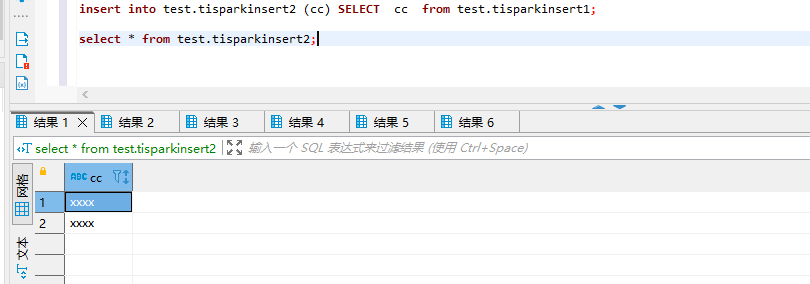
搜索资料下,batchmode开启,在submit模式下可以使用如下方式
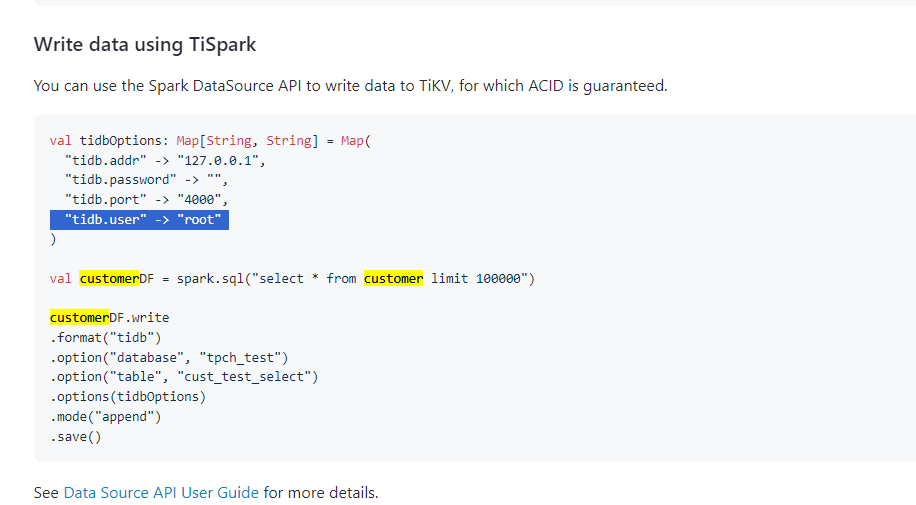
如何通过kyuubi提交sql可以使用batchmode呢
【问题】 当前遇到的问题
如果在kyuubi下解决batch mode的insert方式
【业务影响】
【TiDB 版本】 6.5.6
【附件】 相关日志及监控
SQL 错误: org.apache.kyuubi.KyuubiSQLException: org.apache.kyuubi.KyuubiSQLException: Error operating ExecuteStatement: org.tikv.common.exception.TiBatchWriteException: currently user provided auto id value is only supported in update mode!
at com.pingcap.tispark.write.TiBatchWriteTable.preCalculate(TiBatchWriteTable.scala:179)
at com.pingcap.tispark.write.TiBatchWrite.$anonfun$doWrite$7(TiBatchWrite.scala:199)
at scala.collection.immutable.List.map(List.scala:293)
at com.pingcap.tispark.write.TiBatchWrite.doWrite(TiBatchWrite.scala:199)
at com.pingcap.tispark.write.TiBatchWrite.com$pingcap$tispark$write$TiBatchWrite$$write(TiBatchWrite.scala:94)
at com.pingcap.tispark.write.TiBatchWrite$.write(TiBatchWrite.scala:50)
at com.pingcap.tispark.write.TiDBWriter$.write(TiDBWriter.scala:41)
at com.pingcap.tispark.v2.TiDBTableProvider.createRelation(TiDBTableProvider.scala:94)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:47)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:75)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:73)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:84)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:98)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:109)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated