【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.6
【遇到的问题:问题现象及影响】
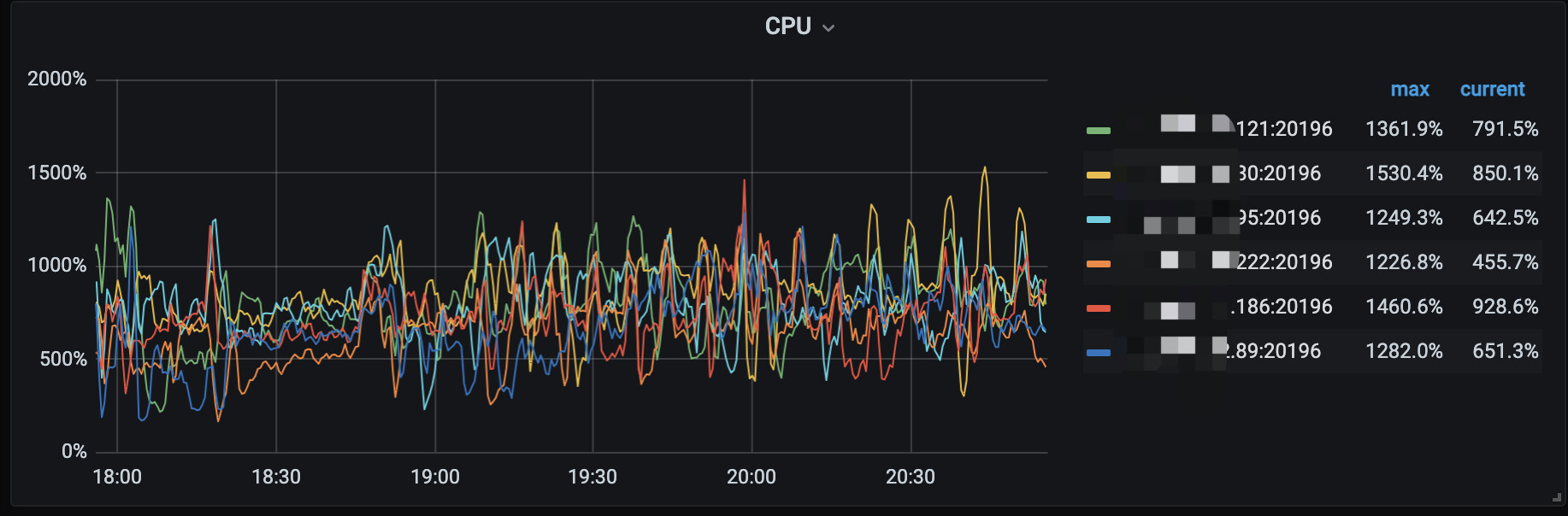
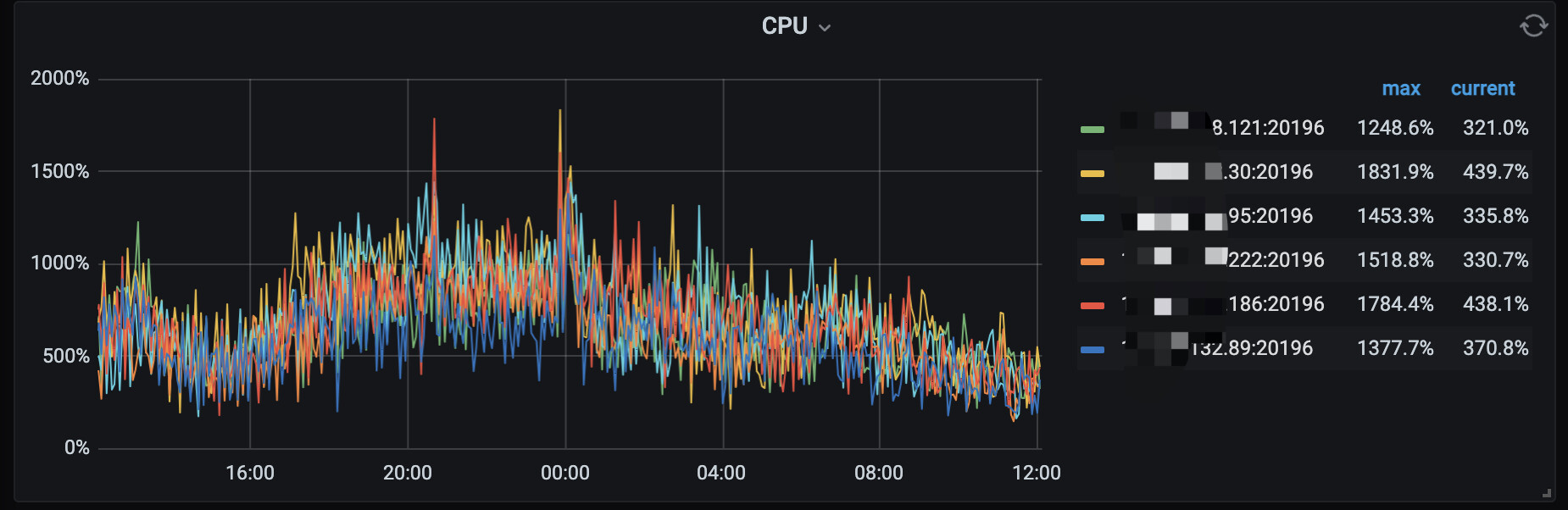
集群在日常运行时,tikv cpu 压力异常偏高

io util 的显示由于机器内核的问题显示的是不准的。io 实际无瓶颈

从dashboard 的topsql 中看,主要是一个insert … set 语句耗时最高
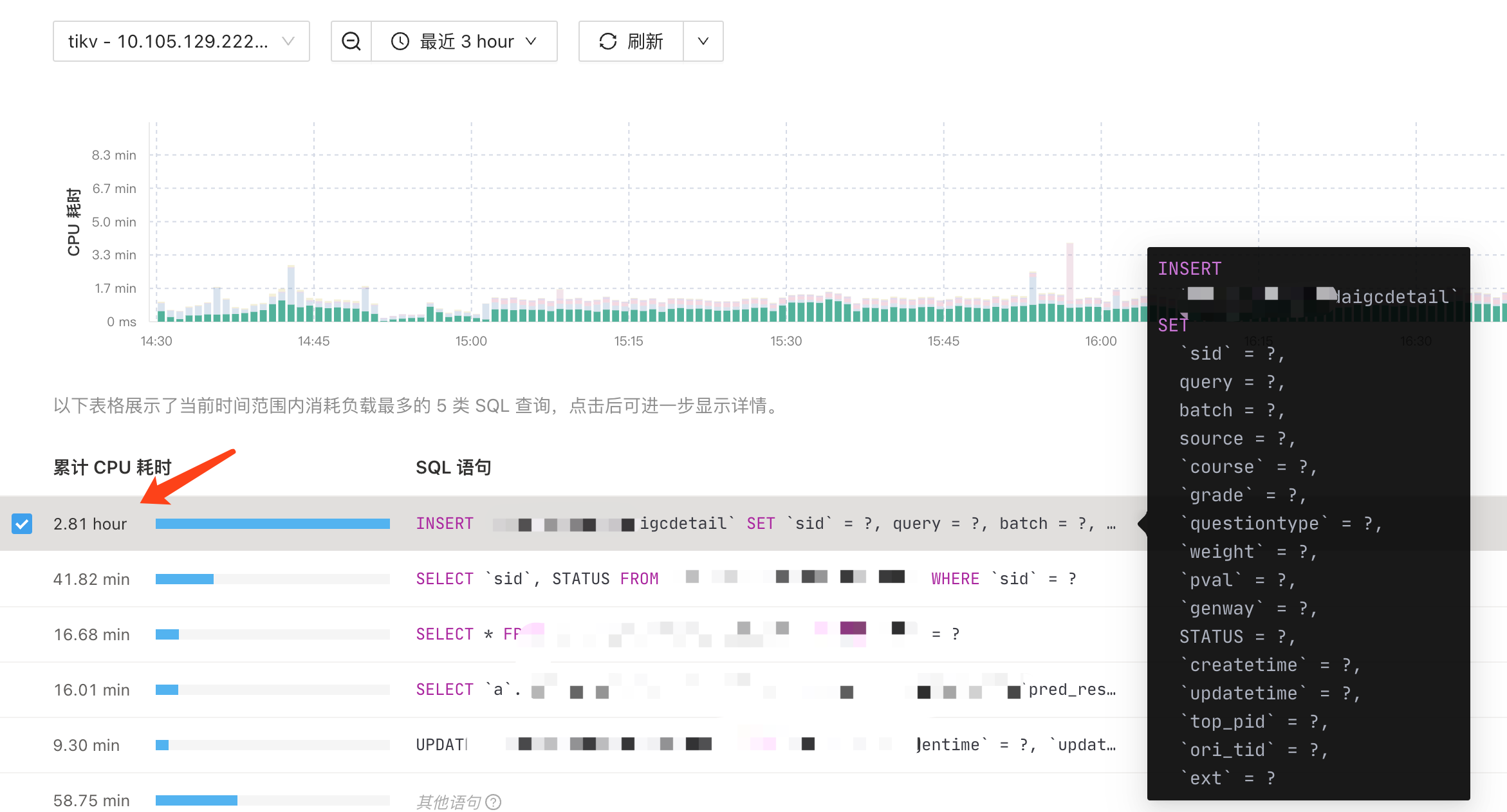
执行计划看着没啥问题,但是耗时确实100ms 不太符合预期,手动单独执行
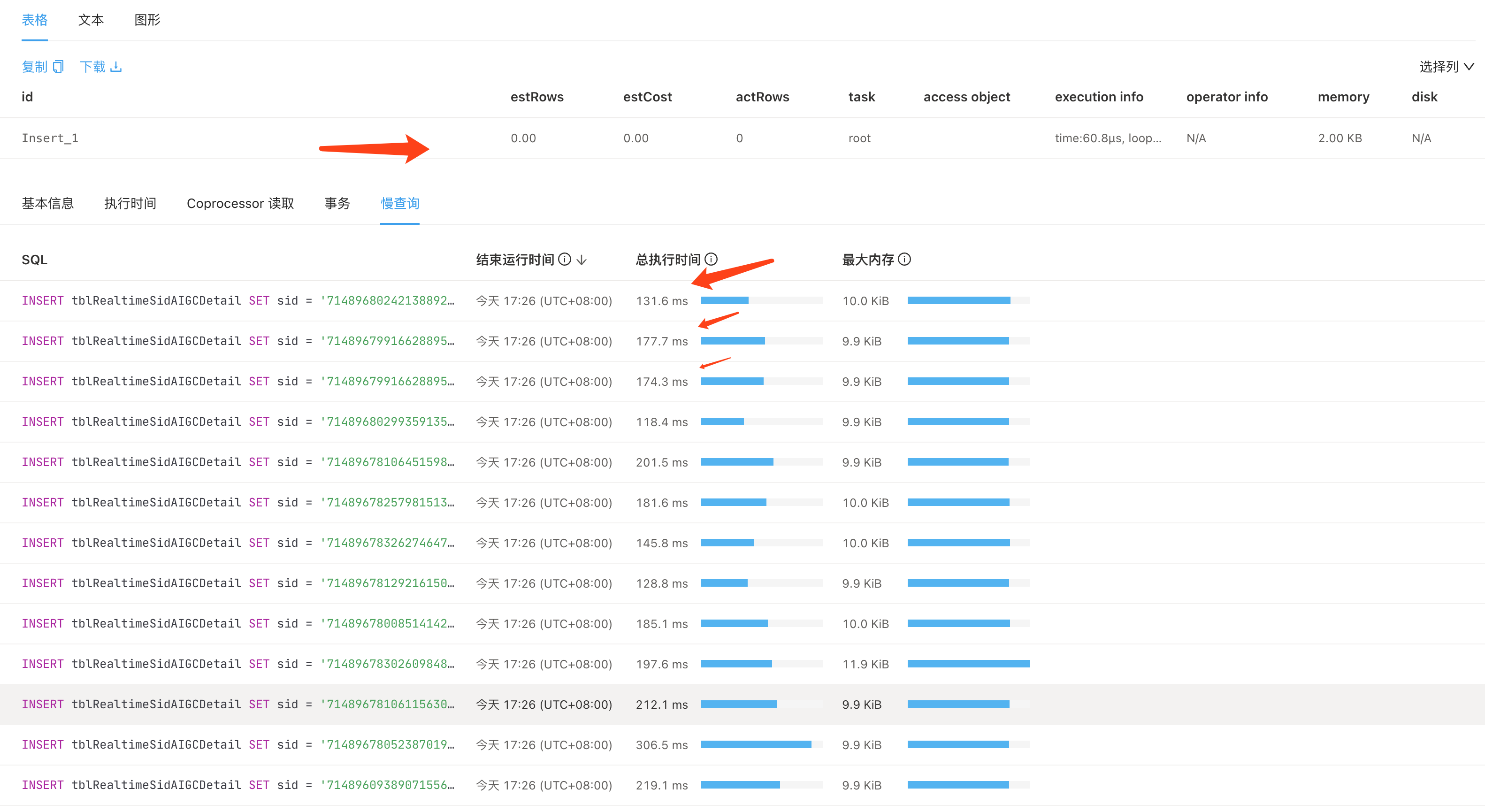
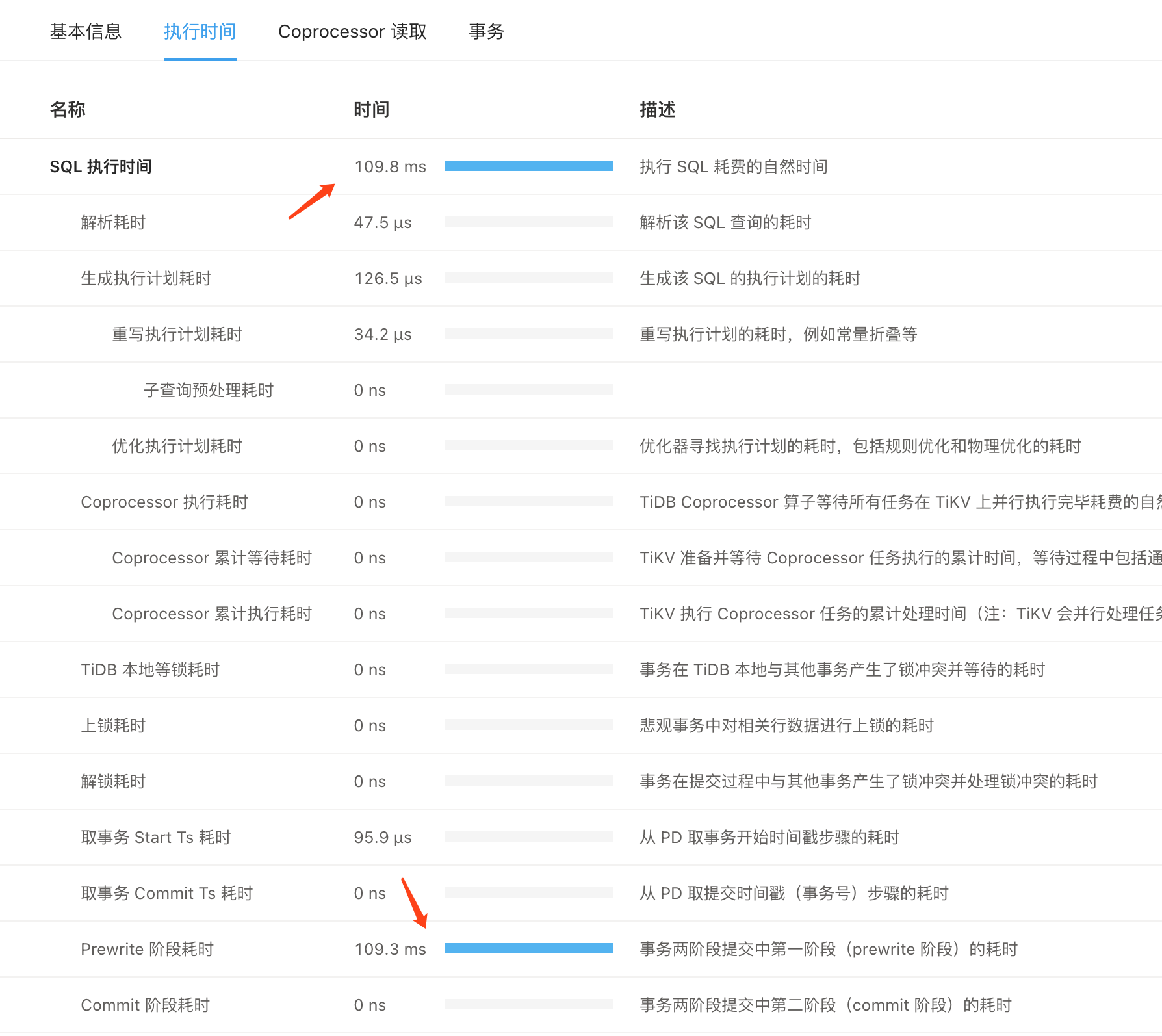
从慢查询信息中看出主要耗时在prewrite 阶段。
请问如何优化何种情况?
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.6
io util 的显示由于机器内核的问题显示的是不准的。io 实际无瓶颈
从dashboard 的topsql 中看,主要是一个insert … set 语句耗时最高
执行计划看着没啥问题,但是耗时确实100ms 不太符合预期,手动单独执行
从慢查询信息中看出主要耗时在prewrite 阶段。
请问如何优化何种情况?
show create table 表结构
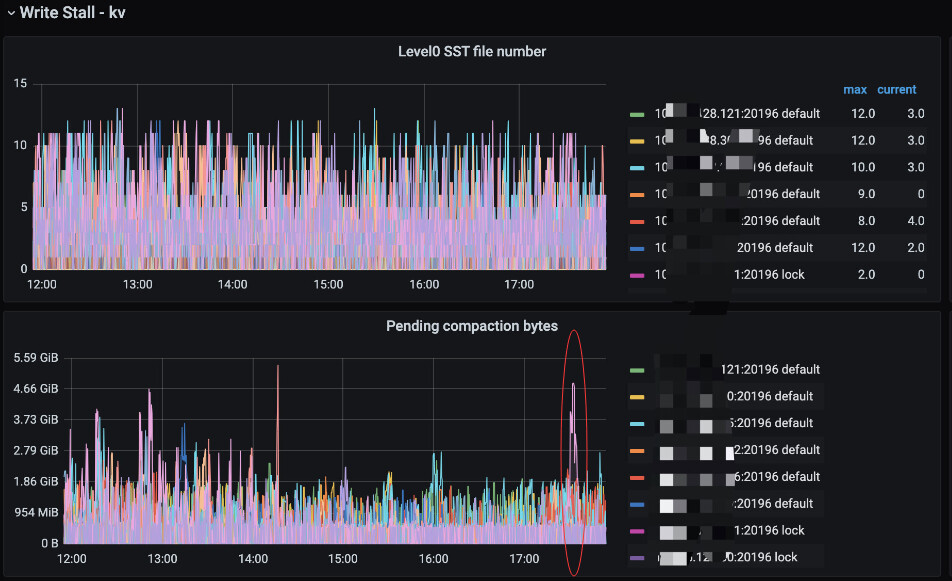
grafana->TiKV-Trouble-Shooting->Write Stall - kv
找对应时间段的图,截一个看看。
看看是不是compaction导致的。
Create Table: CREATE TABLE `xxxxxxx` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键自增',
`sid` varchar(100) NOT NULL DEFAULT '0' COMMENT '检索id',
`query` text DEFAULT NULL COMMENT '题目文本',
`subquestioninfo` text DEFAULT NULL COMMENT '拆小题信息',
`batch` bigint(40) NOT NULL DEFAULT '0' COMMENT '生产批次',
`qid` varchar(40) NOT NULL DEFAULT '0' COMMENT '投放产生的id,无则为0',
`source` varchar(20) NOT NULL DEFAULT '0' COMMENT '来源:1-单题拍,2-整页拍',
`course` bigint(10) NOT NULL DEFAULT '0' COMMENT '学科',
`grade` bigint(10) NOT NULL DEFAULT '0' COMMENT '年级 1,20,30:小初高',
`questiontype` bigint(10) NOT NULL DEFAULT '0' COMMENT '题型',
`weight` bigint(10) NOT NULL DEFAULT '0' COMMENT '热度值',
`pval` decimal(10,2) NOT NULL DEFAULT '0' COMMENT '满意度',
`gentime` bigint(40) NOT NULL DEFAULT '0' COMMENT '投放时间',
`genway` bigint(10) NOT NULL DEFAULT '0' COMMENT '产生方式 1-实时,2-小时,2-天',
`status` bigint(10) NOT NULL DEFAULT '0' COMMENT '所处状态',
`createtime` bigint(40) NOT NULL DEFAULT '0' COMMENT '入库时间',
`updatetime` bigint(40) NOT NULL DEFAULT '0' COMMENT '状态更新时间',
`top_pid` varchar(100) NOT NULL COMMENT 'sid图片pid',
`tid` varchar(20) NOT NULL DEFAULT '0' COMMENT '上线后tid',
`ori_tid` varchar(20) NOT NULL DEFAULT '0' COMMENT '拍搜现场首位tid',
`version` varchar(100) NOT NULL DEFAULT '0' COMMENT '模型版本',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '1:软删',
`ext` text DEFAULT NULL COMMENT '保留扩展字段',
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
UNIQUE KEY `sid` (`sid`),
KEY `tid` (`tid`),
KEY `questiontype` (`questiontype`),
KEY `pull` (`batch`,`course`,`status`),
KEY `idx_createtime_status` (`createtime`,`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=18798046568 COMMENT='AIGC自动解题热表'
时间对的上,是compaction导致的。
show config where type=‘tikv’ and name like ‘%level0-file-num-compaction-trigger%’
运行上面的sql,我看看参数设置的是多少。
你这个表不停的在删除吧 导致
默认配置,感觉你的写入是比较高的。
现在有个2个问题:
1,重写的情况下,你的表肯定会有热点。
idbigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘主键自增’,
PRIMARY KEY (id) /*T![clustered_index] CLUSTERED */,
是个聚簇表+自增id的组合。
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#tidb-热点问题处理
要么使用聚簇表+ AUTO_RANDOM,要么使用非聚簇表+ SHARD_ROW_ID_BITS。
如果你的业务已经上线的话,这恐怕还挺难改的。
2,上面那个查询出来的配置的意思是defaultcf和writecf l0有4个,就该compaction了。
可是你看你的监控里面最高值是12,超过4比较多了。
这个时候l0文件就是12个和下层做全排,写入就会放大。pending compaction bytes就会变高。
这就是延迟成批到100ms的原因,就是瞬时写入的数据量有4.6g了,能保证延迟100ms。你的磁盘还是不错的。
可以考虑下调defaultcf和writecf 上的level0-file-num-compaction-trigger 的数量,让这两个cf尽早的开始compaction,少量多批的做compaction,看看能否降低pending compaction bytes的值,进而减少写入延迟。
大意就是变一次成批的100ms,变2批70ms这样。
需要注意的是,如果你的写入真的很大,这个下调可能没啥用。
我的磁盘不行,按默认配置default.level0-file-num-compaction-trigger=4。pending compaction bytes>2g会出现成批的近秒级延迟,我调到default.level0-file-num-compaction-trigger=1的时候,日常使用碰上compaction导致的写入延迟的概率就很低了。
不过一旦遇到大数据导入,还是能看到l0文件>10个。
所以你的写入量稳定是这么多的话,我不太确定下调这个参数是否有用。
https://docs.pingcap.com/zh/tidb/stable/dynamic-config#在线修改集群配置
你可以参考上面的文档,运行时修改一下level0-file-num-compaction-trigger的值,观察一下是否会导致对应的tikv的pending compaction bytes下降。
确认有用了,再考虑通过tiup cluster edit-config修改整个集群的配置。
好的多谢。
其实我们另外一个集群也有这种使用场景,每天写入量挺大,每天也在一直删除。但是没有出现这个情况。我先调整下这个参数试试。
一样的道理,你可以直奔pending compaction bytes这个图,看看峰值是多少,以及l0文件的个数。
这种成批的延迟升高,不发生在30分钟内,是不太容易注意到的。而且,老实说,我觉得100ms其实还好。对大部分人来说感觉不到卡的。
tikv cpu 持续保持在700% 左右,高峰期能达到1500%,这个看着还是有点担忧所以来深究下具体原因。
感谢支持 ![]()
老哥请看猫老师的回复。我调整完有效果过来反馈
写入量很大,推荐用批量写,我们有个业务写入量每天1亿多,开始性能跟不上,后面改造成批量写
这个集群写入才两三千qps ,现在的性能我觉得是不符合预期的,这点并发量就让业务改代码不合适。
我们另外一个集群每天单表(宽表)写入十几亿,qps 在3w 左右。
开始是批量写,tikv cpu 达到接近2000% 。后来改成单条写,qps 高峰期 4w 左右。tikv cpu 稍微降下来基本都是1500% 以下,但是tidb cpu 又干到2000% 多。下周我还得发个帖子研究下怎么优化 ![]()
写入才两三千qps,就上不去了得话。这就像是热点问题导致的。
起码你这个表结构看上去就是没有办法支持大批量写入的。
当有大量插入的时候,写入都会集中在一个region上。
你起码有6台tikv。要把写入分散一下。
如果一定要使用AUTO_INCREMENT 自增的话,就要使用非聚簇表+SHARD_ROW_ID_BITS.
像下面这样:
Create Table: CREATE TABLE
xxxxxxx(
idbigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘主键自增’,
sidvarchar(100) NOT NULL DEFAULT ‘0’ COMMENT ‘检索id’,
querytext DEFAULT NULL COMMENT ‘题目文本’,
subquestioninfotext DEFAULT NULL COMMENT ‘拆小题信息’,
batchbigint(40) NOT NULL DEFAULT ‘0’ COMMENT ‘生产批次’,
qidvarchar(40) NOT NULL DEFAULT ‘0’ COMMENT ‘投放产生的id,无则为0’,
sourcevarchar(20) NOT NULL DEFAULT ‘0’ COMMENT ‘来源:1-单题拍,2-整页拍’,
coursebigint(10) NOT NULL DEFAULT ‘0’ COMMENT ‘学科’,
gradebigint(10) NOT NULL DEFAULT ‘0’ COMMENT ‘年级 1,20,30:小初高’,
questiontypebigint(10) NOT NULL DEFAULT ‘0’ COMMENT ‘题型’,
weightbigint(10) NOT NULL DEFAULT ‘0’ COMMENT ‘热度值’,
pvaldecimal(10,2) NOT NULL DEFAULT ‘0’ COMMENT ‘满意度’,
gentimebigint(40) NOT NULL DEFAULT ‘0’ COMMENT ‘投放时间’,
genwaybigint(10) NOT NULL DEFAULT ‘0’ COMMENT ‘产生方式 1-实时,2-小时,2-天’,
statusbigint(10) NOT NULL DEFAULT ‘0’ COMMENT ‘所处状态’,
createtimebigint(40) NOT NULL DEFAULT ‘0’ COMMENT ‘入库时间’,
updatetimebigint(40) NOT NULL DEFAULT ‘0’ COMMENT ‘状态更新时间’,
top_pidvarchar(100) NOT NULL COMMENT ‘sid图片pid’,
tidvarchar(20) NOT NULL DEFAULT ‘0’ COMMENT ‘上线后tid’,
ori_tidvarchar(20) NOT NULL DEFAULT ‘0’ COMMENT ‘拍搜现场首位tid’,
versionvarchar(100) NOT NULL DEFAULT ‘0’ COMMENT ‘模型版本’,
deletedtinyint(4) NOT NULL DEFAULT ‘0’ COMMENT ‘1:软删’,
exttext DEFAULT NULL COMMENT ‘保留扩展字段’,
PRIMARY KEY (id) /*T![clustered_index] NONCLUSTERED */,
UNIQUE KEYsid(sid),
KEYtid(tid),
KEYquestiontype(questiontype),
KEYpull(batch,course,status),
KEYidx_createtime_status(createtime,status)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin shard_row_id_bits = 4 pre_split_regions=4 COMMENT=‘AIGC自动解题热表’
主要区别在
PRIMARY KEY (
id) /*T![clustered_index] NONCLUSTERED */,
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin shard_row_id_bits = 4 pre_split_regions=4 COMMENT=‘AIGC自动解题热表’
别的都不需要改动。
从集群的现象来看,不是热点写的问题。其实其他tidb业务好多表都是从mysql 直接迁移过来的,都是用的auto_increment, 实际上没有太明显的热点问题。
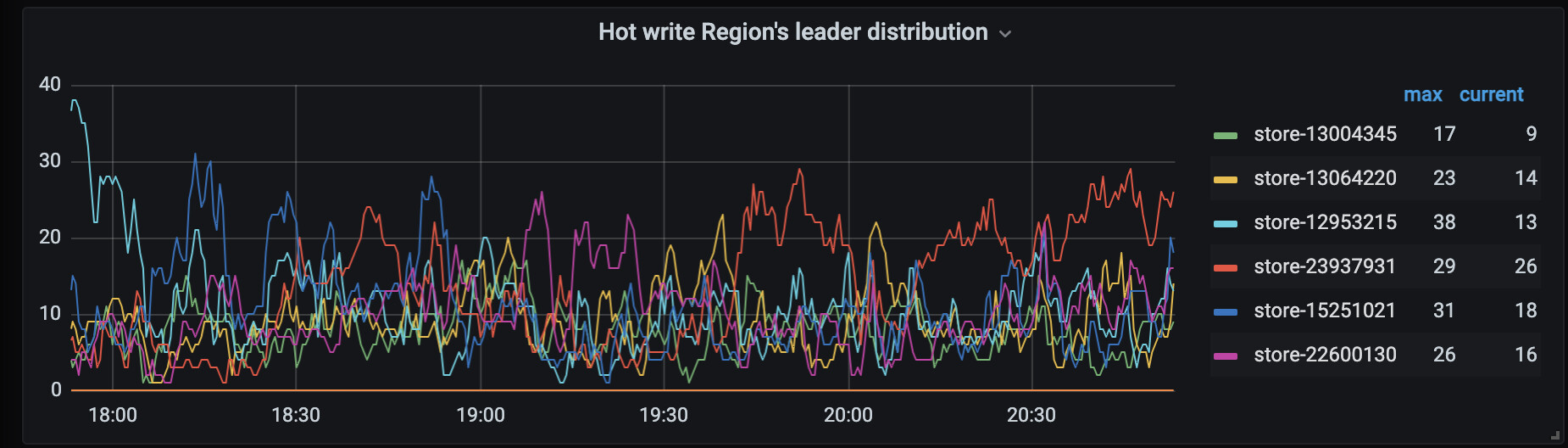
这个图是当前集群的热点状态,我觉得是毫无压力的。可能主要还是compaction 的问题
上面你提到的参数我也从4 改到8了,这个效果不是十分理想
这个热点分布的图,不一定能看出单热点的问题。
好比你这个表结构,写入都在一个region上,在整体来看可能也就是1/20。不会造成热点region数量的明显上升。
但在 TiDB Dashboard 中的流量可视化上面看,这个region可能已经很亮了。
我写的意思是下调,因为下调才会少量多批的compaction。上调的话,是多量少批的做compaction,应该是pending compaction bytes会变得更大。
可以慢慢从4改到3,然后3改2这样观察一下。set config支持对单tikv的参数修改,只要观察到单个tikv的pending compaction bytes在慢慢变小,就说明有用。如果改完了,l0的文件数量(这个图就是pending compaction bytes上面那个Level0 SST file number)还是常态化的大于你设置的这个值,那pending compaction bytes也不会降低。这就是确定没有作用了,在线把这台tikv的参数改回来,再想别的办法。
302视频好像有这个的讲解