
leader size看着比较均衡,试试把剩余空间较多的store的region weight 调高一点点 比如1.1 过段时间看看能均衡衡不,具体命令 pd-ctl store weight 看下帮助
调整这个权重对集群的影响大吗?这个是个生产集群,等得业务不繁忙的时候操作
会有region调度,会影响些读写,这只是其中一个解决方法,问题原因还是没找到,感觉是有些大region
这怎么看的。。。。。
region 不是到了一定程度自己会分裂吗?好像是144M ?
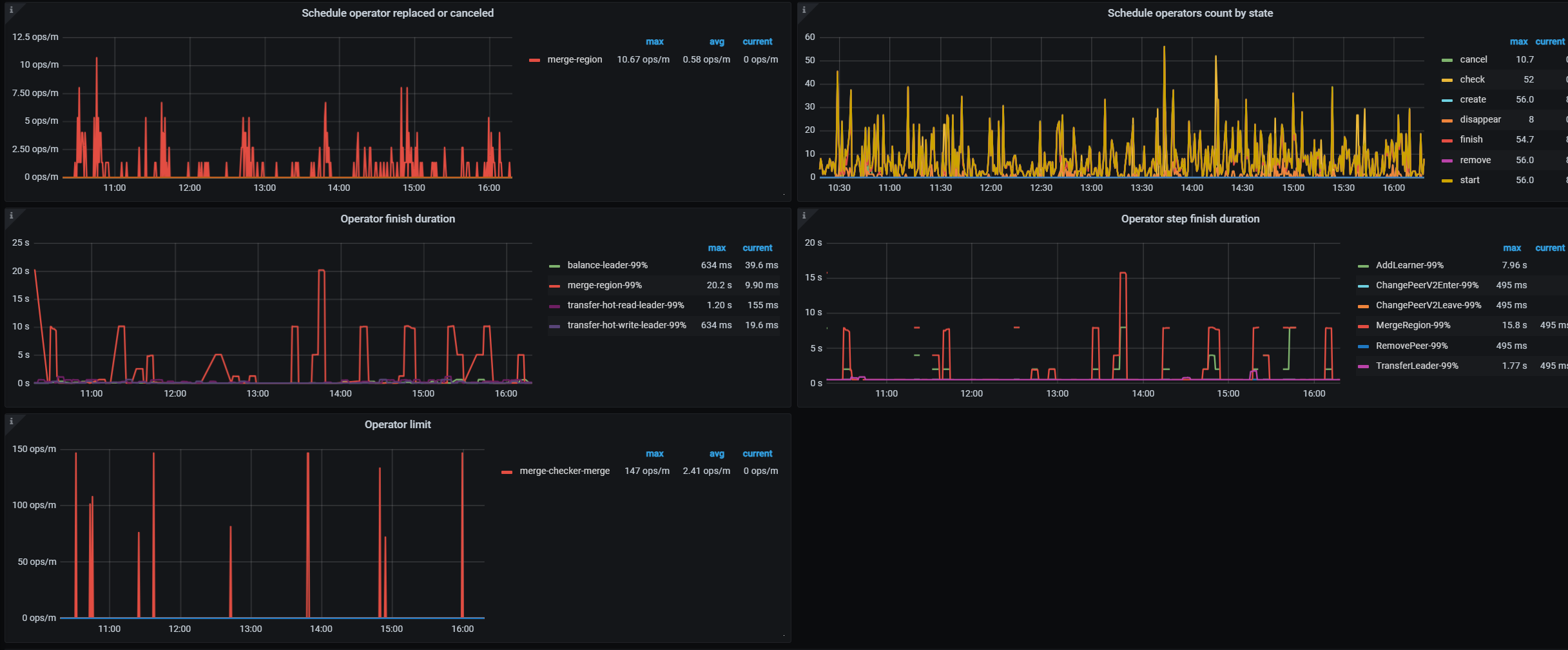
再发下PD=》operator和PD=》Scheduler=》Filter source/Filter target这俩监控


用pd-ctl调整下PD的这个参数,默认值应该是"max-snapshot-count": 64

存储容量不足,节点故障或不可用,调度策略配置都看看。
max-snapshot-count 256
max-pending-peer-count 256
replica-schedule-limit 64
修改的这三个参数,region 开始调度,磁盘使用率趋于平衡,官方介绍的这3个参数的含义不是很明白,清指点下
max-snapshot-count 控制单个 store 最多同时接收或发送的 snapshot 数量,调度受制于这个配置来防止抢占正常业务的资源。当需要加快补副本或 balance 速度时可以调大这个值。
max-pending-peer-count 控制单个 store 的 pending peer 上限,调度受制于这个配置来防止在部分节点产生大量日志落后的 Region。需要加快补副本或 balance 速度可以适当调大这个值,设置为 0 则表示不限制。
通过调整 replica-schedule-limit 可以控制同时进行 replica 调度的任务个数。这个值主要影响节点挂掉或者下线的时候进行调度的速度,值越大调度得越快,设置为 0 则关闭调度。Replica 调度的开销较大,所以这个值不宜调得太大。注意:该参数通常保持为默认值。如需调整,需要根据实际情况反复尝试设置该值大小。
如果没有调度问题,不建议调整默认值