舞动梦灵
(Ti D Ber Nckmz Hmh)
1
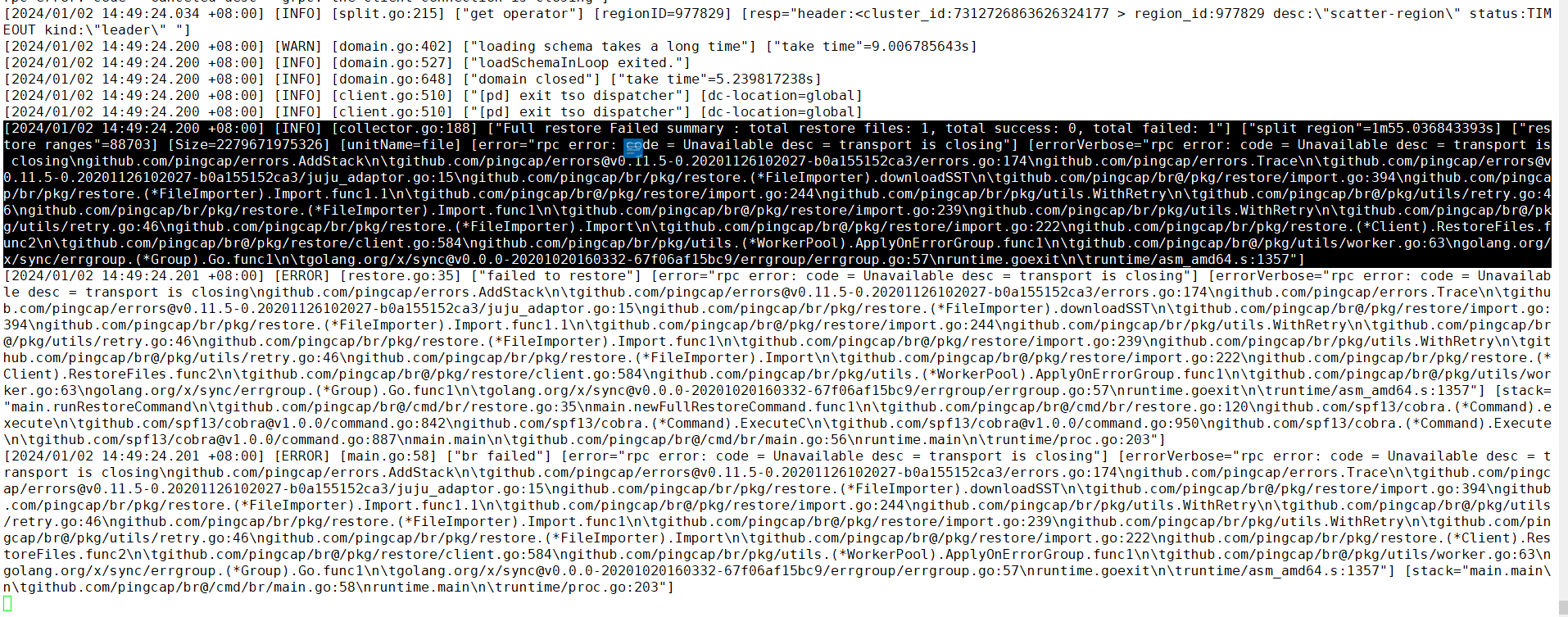
BR4.0.9备份,恢复到5.0.0版本,200G的测试库恢复没有任何问题,恢复这个2T的,一直报错
使用br第一次恢复。失败1个,然后吧数据库全删了,重新恢复,报的这个错误官方文档写是因为资源不够,降低并发和速度,我一直调低这两个参数,感觉没用,调的越低,报错时间越快
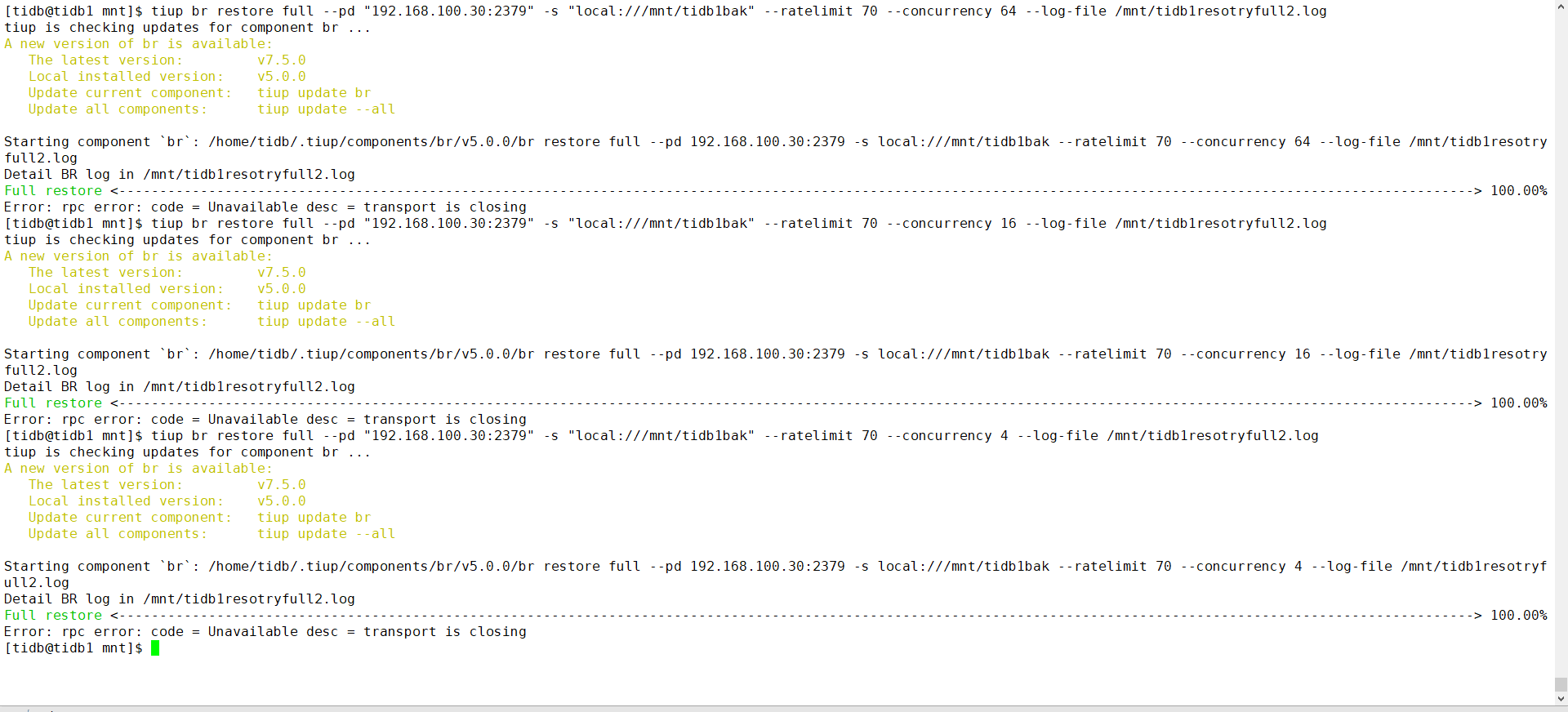
使用的恢复命令:tiup br restore full --pd “192.168.100.30:2379” -s “local:///mnt/tidb1bak” --ratelimit 70 --concurrency 4 --log-file /mnt/tidb1resotryfull2.log
已经恢复了3次了。并发降低到和cpu核数一样还是不行
舞动梦灵
(Ti D Ber Nckmz Hmh)
3
哪里启动事务??我是在screen里面执行的恢复命令。你说的是哪个?
舞动梦灵
(Ti D Ber Nckmz Hmh)
4
有人吗??这个回复报错怎么解决有知道的吗?
Error: rpc error: code = Unavailable desc = transport is closing
舞动梦灵
(Ti D Ber Nckmz Hmh)
6
。。。。。
我备份测试库200G没问题恢复,这个2T的恢复有问题。那完蛋了,还有一个17T的备份正在传输呢,传完了也要恢复呢。
我的服务器配置是
|
|
内存 |
核数 |
/server |
| tidb1 |
|
16 |
4 |
100g |
| tikv1-3 |
|
12 |
4 |
2900g |
连连看db
7
要么设置concurrency 为1,要么去掉ratelimit,5.0以下的低版本BR存在ratelimit 的bug。
舞动梦灵
(Ti D Ber Nckmz Hmh)
8
去掉ratelimit是不是就是默认使用最大值?
那我试试两个?一个不加限速,一个加并发为1是吗
tiup br restore full --pd “192.168.100.30:2379” -s “local:///mnt/tidb1bak” --log-file /mnt/tidb1resotryfull2.log
tiup br restore full --pd “192.168.100.30:2379” -s “local:///mnt/tidb1bak” CONCURRENCY 1 --log-file /mnt/tidb1resotryfull2.log
舞动梦灵
(Ti D Ber Nckmz Hmh)
10
好的我试试,之前第一次ratelimit 128 恢复了感觉已经恢复成功了。2.1T备份恢复了节点2.4T数据了,最后报错。
舞动梦灵
(Ti D Ber Nckmz Hmh)
12
不同库备份恢复?啥意思?单独备份某一个库?按库恢复?
舞动梦灵
(Ti D Ber Nckmz Hmh)
14
我也想这么做。结果发现,十几个库。基本上95%的都在一个库里面。2.1T的那个一个库是2T其他十个100G,另外一个17T的一个库14T 其他10个库占3T。。 
路在何chu
(Ti D Ber Ass Gn Qs R)
15
你那个库肯定有很多大表,直接单独备份那一批大表,然后剩下库表一起备份
舞动梦灵
(Ti D Ber Nckmz Hmh)
17
貌似不行:
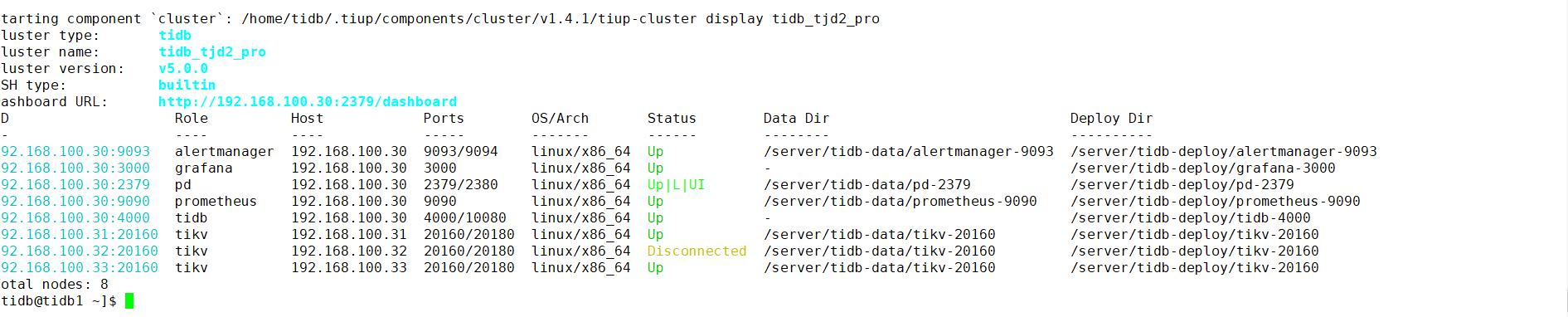
什么参数都不加,然后就会提示有tikv节点断开然后备份直接报错
舞动梦灵
(Ti D Ber Nckmz Hmh)
18
现在时间不够 这个项目计划1月底完成,传输速度只有4M每秒,全是小文件,速度提不上去,传输时间很慢,如果再去单独搞一个个的表,估计时间更长。除非最后迫不得已没办法了
舞动梦灵
(Ti D Ber Nckmz Hmh)
20
我也想呀,从阿里云上传输到本地机房,机房在办公室里面。 问了运维,他说没法快了。小文件太多