【 TiDB 使用环境】生产环境
【 TiDB 版本】7.1.1
内存我给24g,现在跑一点就报内存溢出:
各位有没有这方面经验的:
- tidb 一次查询支持多少返回数据呀
- 这个参数怎么调呀
https://docs.pingcap.com/zh/tidb/stable/configure-memory-usage#数据落盘
内存不够,不开落盘估计搞不定。慢点能接受的话,就落盘吧。
当包含 Sort、MergeJoin 或 HashJoin 的 SQL 语句引起内存 OOM 时,TiDB 默认会触发落盘。
能触发落盘的算子一通设置后也就这3个,所以你单表select -from的时候还要加个order by。使用一下sort算子,才能触发落盘。
不好用,因为Tidb别管是以流式获取数据还是以游标方式获取数据都会导致这个大SQL OOM
1.所以可行的解决方法还是拆批处理,分多个SQL把数据拿出来,根据业务逻辑拆批,批还比较大再加上窗口函数拆批
2.还有个思路就是从业务解决,为什么要一个SQL把2亿数据查出来,这本身就不合理.
流式和游标获取数据: https://docs.pingcap.com/zh/tidb/stable/dev-guide-connection-parameters#使用-streamingresult-流式获取执行结果
龙虾大佬的两个思路非常有针对性,楼主可以确认一下业务是否为合理需求,不合理的需求可以直接拒绝。
还有一个思路是通过flink 或者spark来读取数据,写入下游,不过这得依赖相关技术栈来实现
先明确一下需求,为什么要查询全部的2亿数据出来。如果是为了传输,可以采取其他方式。
可以扩大下tidb_mem_quota_query的参数,我们之前专门扩大一台tidb的内存,用于这种大查询语句,
2亿数据查询出来显示在哪?还是要导出2亿数据到excel之类的,需求不明确
内存不够tidb_mem_quota_query可以调大,你先看看这个表数据占用空间,要设置的比这个数更大
SELECT TABLE_NAME as tableName ,
concat((DATA_LENGTH/(102410241024)),“GB”)
FROM information_schema.TABLES
WHERE TABLE_SCHEMA=‘z_qianyi’
AND TABLE_NAME=‘ticket’
低级解决方案:分而治之 拆分为小批量 一点一点导出 时间换空间
高级解决办法:怼得业务脑瓜子嗡嗡的 此类需求无异于当年 通过前置摄像头捕捉用户眼睛反光来判断用户手机壳颜色 进而自动调整app主题 结果就是产品经理被暴打 再有这类需求直接开喷
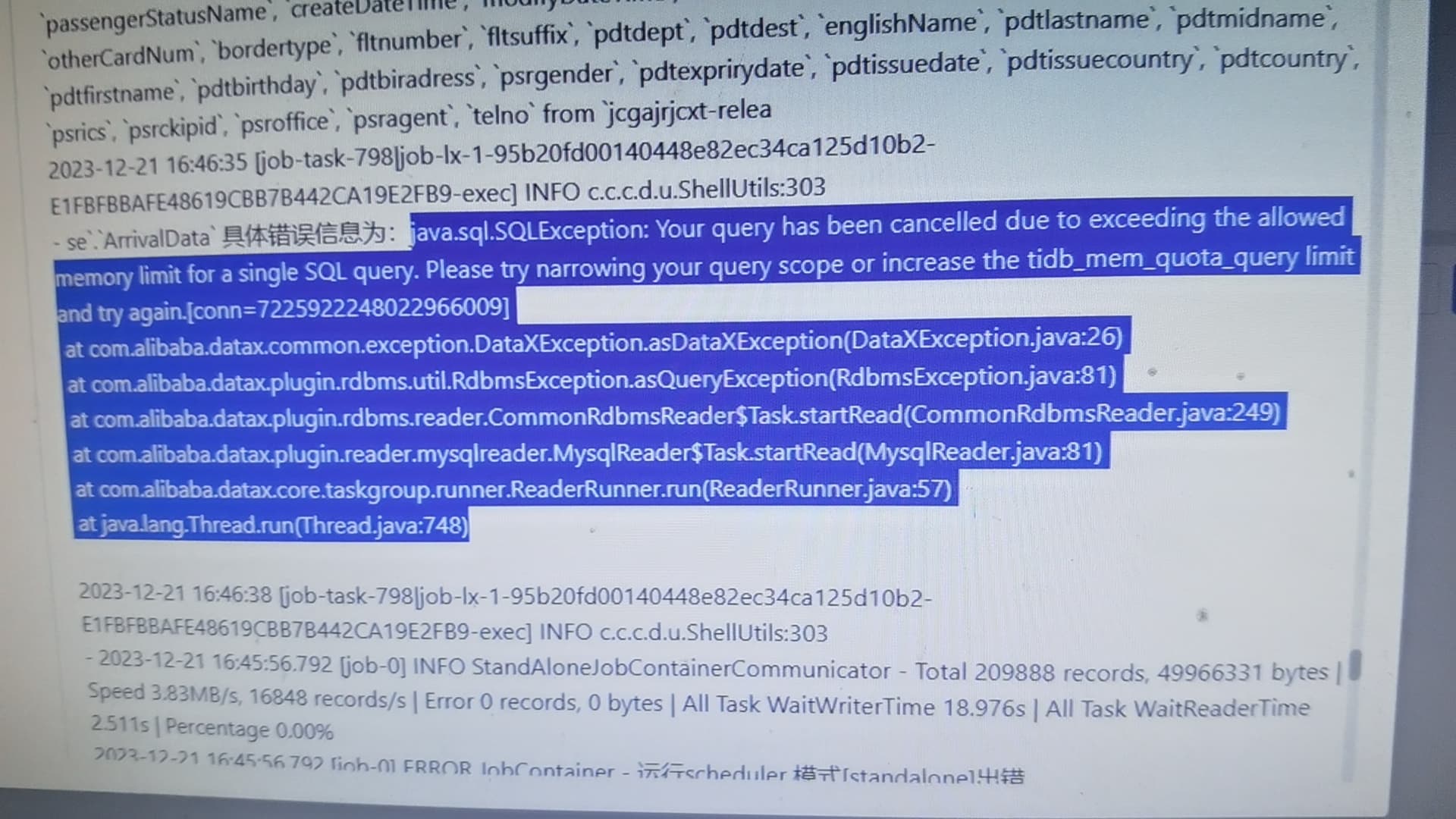
仔细看题目。是题主使用datax时,控制台日志的错误信息吧。源数据,你使用了select * from table;数据缓存在本地。想想这么大的数据库肯定报错。这么用法本就存在问题,不合理。如果想试下,可以调大datax有关配置的,java内存参数。
当然tidb也需要进行查询内存参数的配置,就怕拉垮其他服务实例。
![]() 太细节了,都没注意到
太细节了,都没注意到 alibaba.datax ,那这就是数据传输要分批分段同步吧。
插个眼,这个问题很大概率都会遇到,实在没办法就只能分段了,但是复杂性会增加很多
这如果不分页,估计直接就OOM了吧。
我有一个方案给你参考:
java jdbc 中有个参数称为 游标滚动,只允许向前滚动,不允许往回滚动,通常是作为 pipe line 的流式处理使用,但是核心问题:这么多数据,最后通过 pipe line处理之后,你放哪儿?(当然,这是你需要操心的)
jdbc查询mysql时,默认会一次性将sql查询的数据全部从服务器加载到内存中,当数据过多时,导致内存溢出,最佳的办法:按页分次滚动获取数据即可
Statement statement = connection.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
// 设置从数据库取得多行的行数大小
statement.setFetchSize(batchSize);
// 将此 Statement 对象生成的所有 ResultSet 对象可以包含的最大行数限制设置为给定数
statement.setMaxRows(maxRows);
根据你的服务实际的内存大小,设置每次获取的行数和最大限定,避免过载
请参考
通过datax抽2亿条数据啊,我想知道你的目标端是哪
先查看表大小,内存至少是表大小的2到3倍
什么场景这样的需求,如果是业务的话明显感觉没必要啊,一次性这么多数据怎么查看?如果是数据处理,可以通过专业的etl工具实现,多批次批量执行,每个批次处理符合一定条件范围的数据
为什么要这么做。什么样的业务场景需要如此操作。感觉需求不合理。
批量处理也不是这个处理办法,建议说明真实的业务需求场景,感觉是个伪需求
直接select一次性查询 出现oom正常,最简单写个简单的代码分批查询,在本地都可以运行
主要还是看你的使用场景,如果是为了给下游供数,可以通过dumpling导出成文件给下游