普罗米修斯
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.2.4
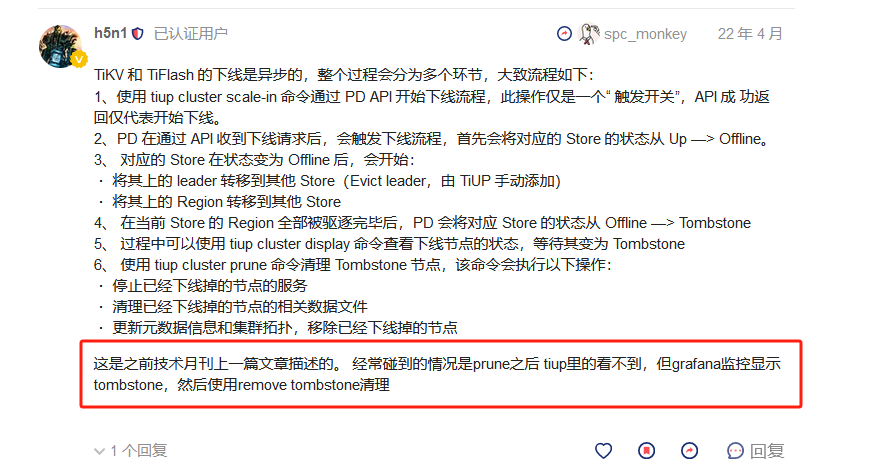
【复现路径】因为tikv label配置错误最近做的操作:扩缩容了三台tikv,目前扩缩容已完成 ,最后一个下线tikv节点(192.168.80.212),pd层面显示为墓碑模式,执行了 store remove-tomstone,然后发现执行tiup cluster prune xx提示找不到该已经下线的tikv节点,使用tiup cluster scale-in xxx --force移除了该节点(tikv下线步骤错误怎么清理集群下线tikv缓存
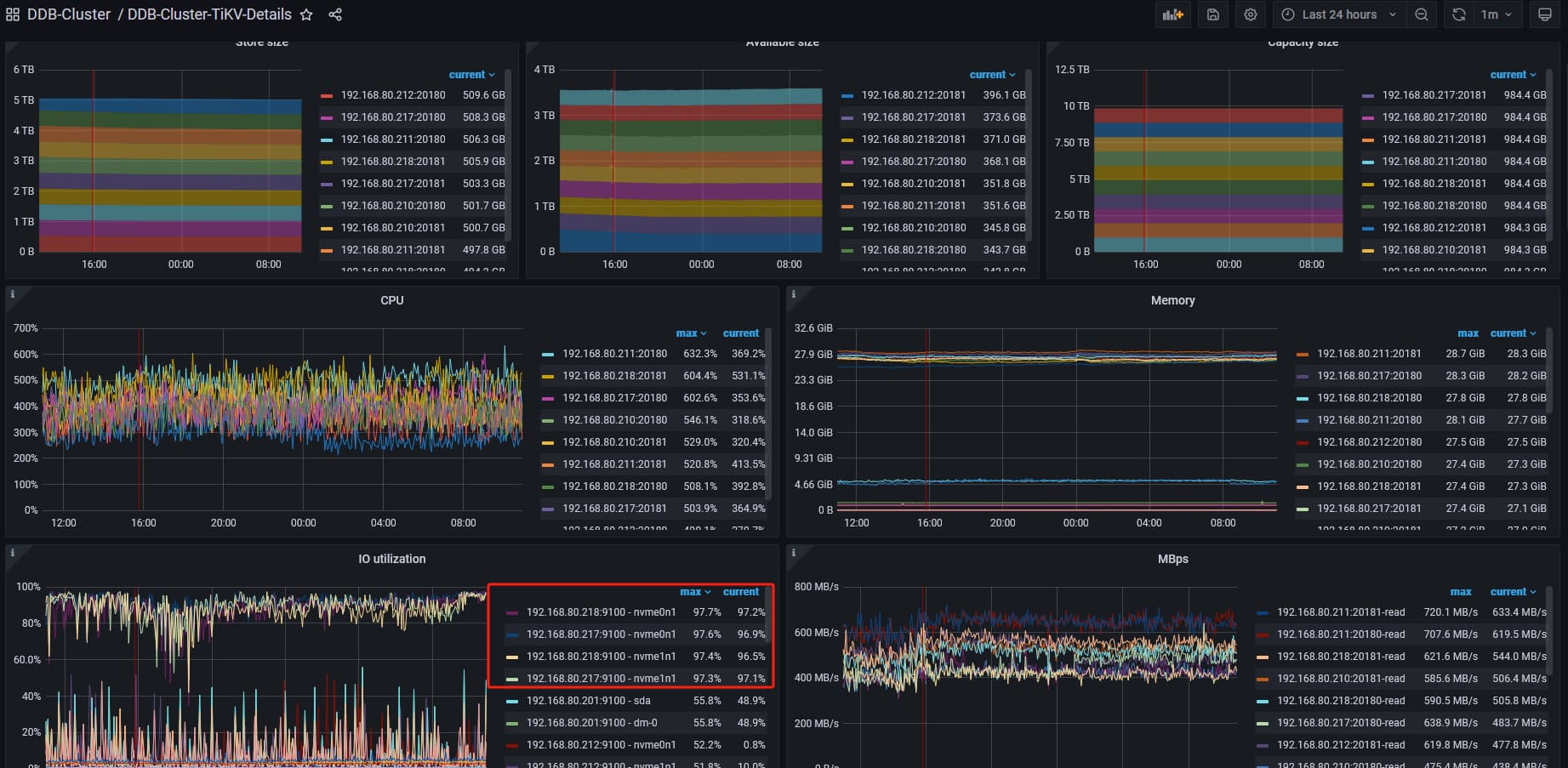
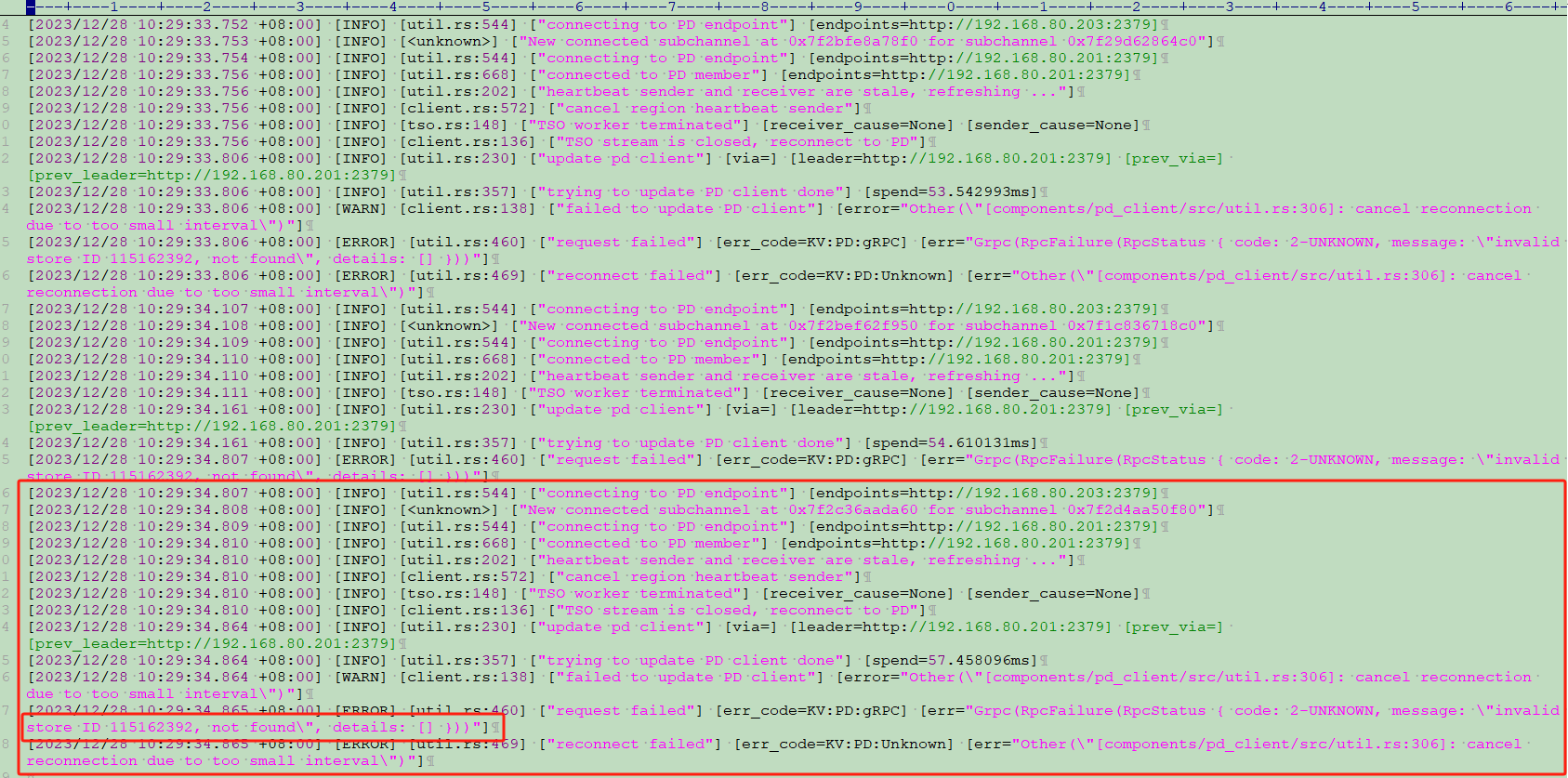
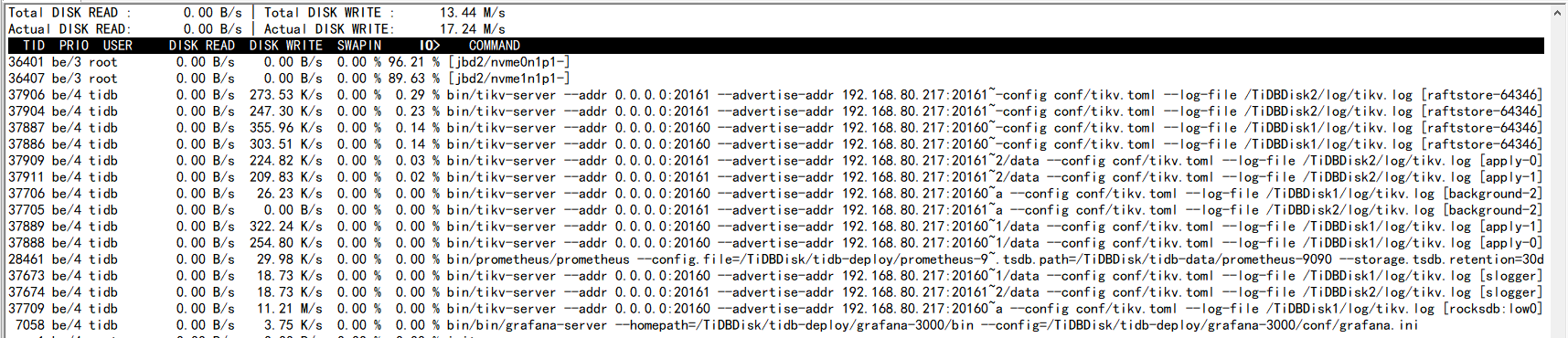
【遇到的问题:问题现象及影响】今天查看监控,发现在线的tikv节点的IO 占用率基本都接近100%,在系统使用iostat查看tikv所在的io使用率一直高,iotop查看占用高的进程为tikv服务,查看了tikv日志,所有的日志提示都是去找已经下线的tikv节点(192.168.80.212),不知道是不是这个影响导致io高,应该怎么剔除这个节点,该节点实际已经没了;
【资源配置】
【附件:截图/日志/监控】
store 115162392就是已经下线的192.168.80.212
WalterWj
(王军 - PingCAP)
3
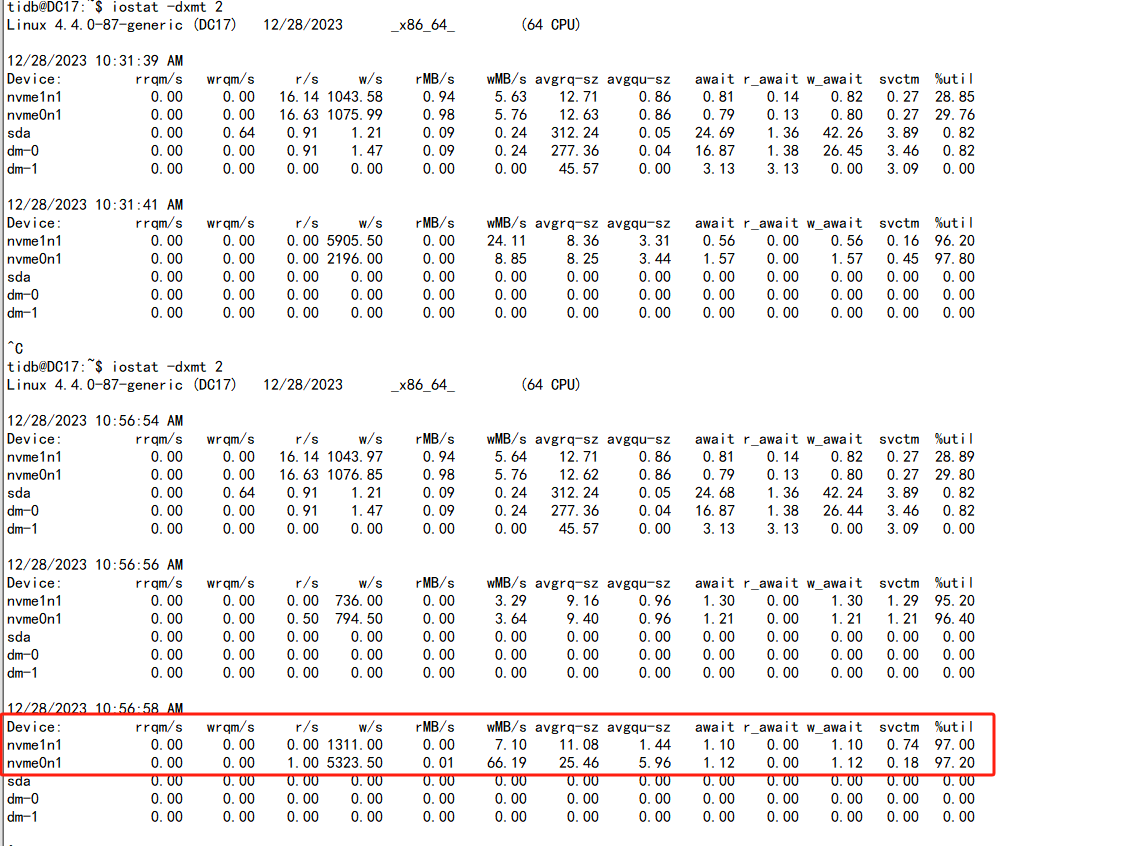
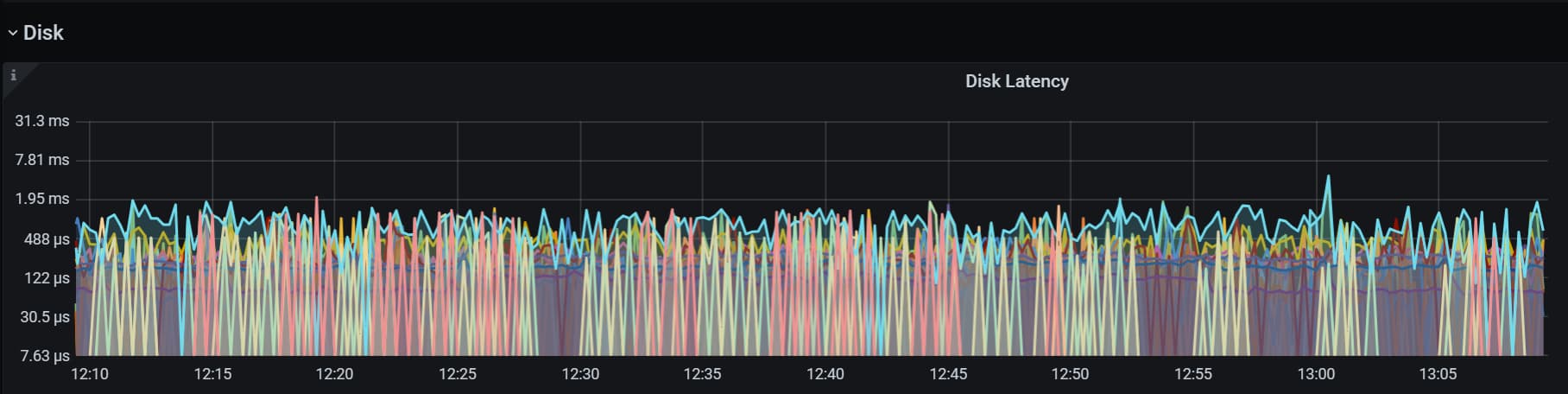
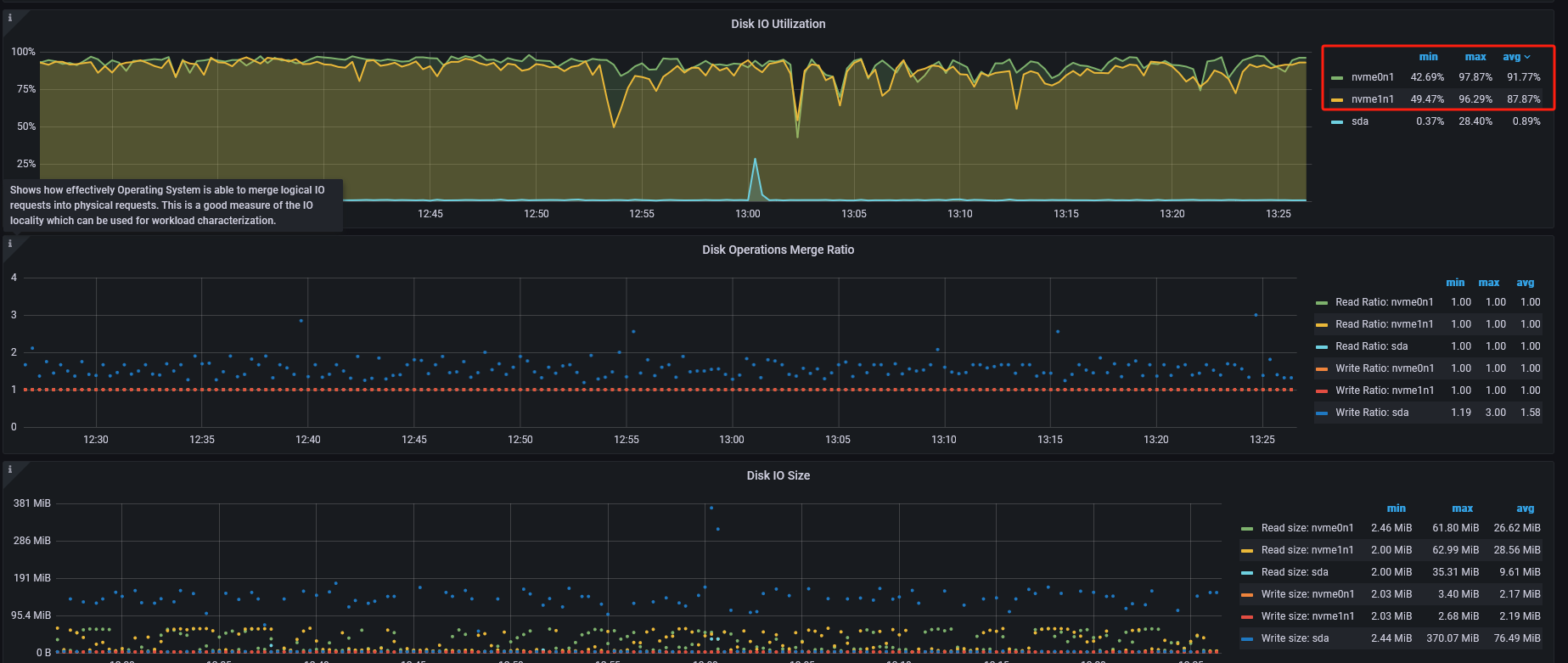
NVME 的盘的话,不要看 IO util,那玩意不准,看下 disk performance,看看响应时间是否高,正常都是 us 级别的。
IOPS 和 读写流量,可以用 fio 测试下盘的性能,对比下使用率,就知道大概用了多少性能了。
1 个赞
zhanggame1
(Ti D Ber G I13ecx U)
4
你说的disk performance是看这个延时吗
还是这个
普罗米修斯
6
怎么真正剔除已经下线的tikv 不让再去访问该节点了 我觉得和这方面频繁访问以及打印日志有关系 ,之前io没这么高
WalterWj
(王军 - PingCAP)
7
你 tikv 安装的 data 目录是 nvme 的盘么? 为啥看你监控每个 tikv 的盘容量是 900 多 GB?
普罗米修斯
10
最大的使用量是60%左右 现在region迁移也没啥问题,现在问题是上面这个怎么剔除已经下线的tikv 不让在去频繁访问它了
WalterWj
(王军 - PingCAP)
11
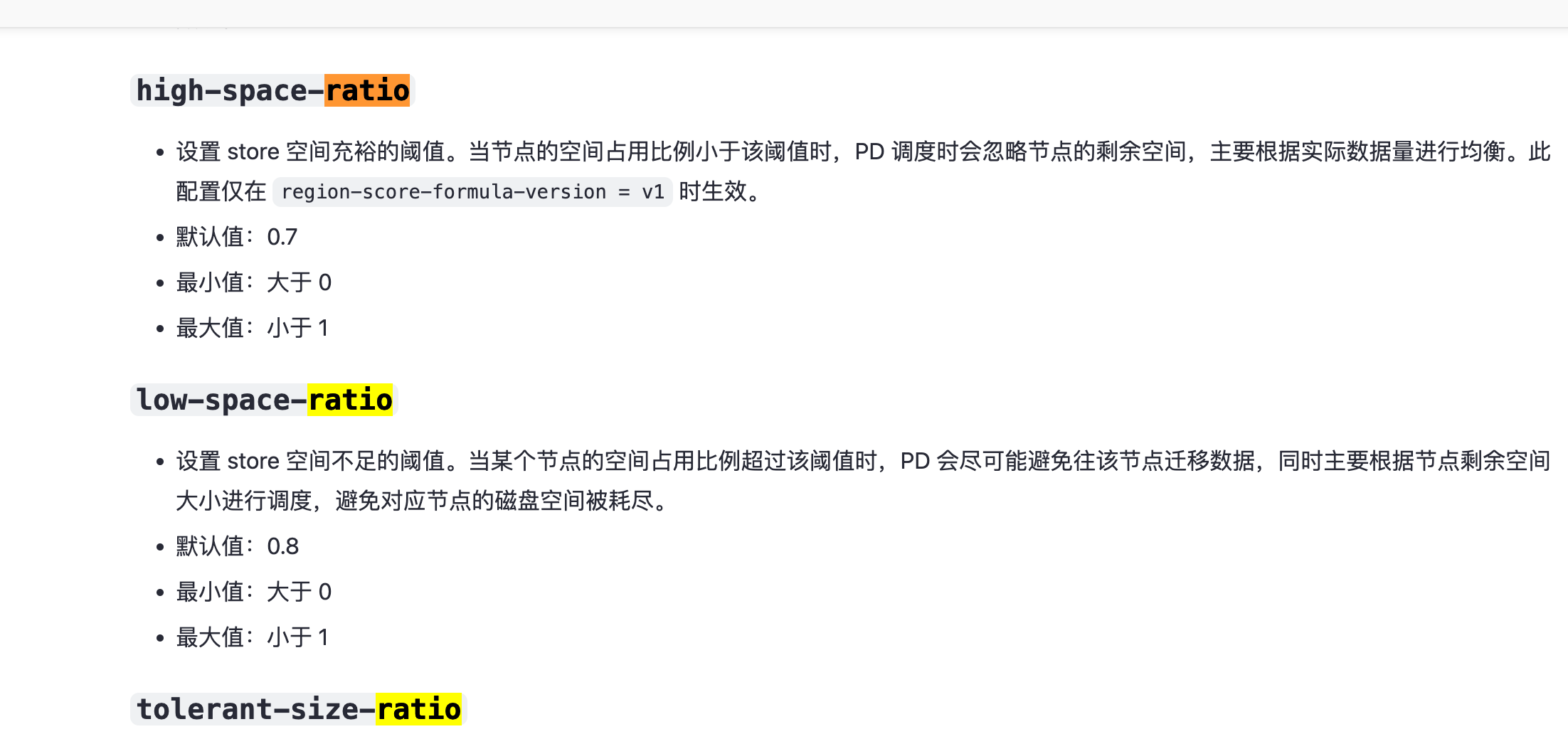
低版本我记得 low 应该就是 0.6. 已经下线的 tikv 不会再访问,除非你下线没成功。
普罗米修斯
12
已经下线完成了 和这个问题是一样的 不过不知道后面是怎么处理的
WalterWj
(王军 - PingCAP)
13
怎么感觉最近有 1/2 个贴在说这个事情了。正常官网不就是缩容,等墓碑之后执行 prue 操作即可。不需要手动删除 pd 中的信息的。。。。。
zhanggame1
(Ti D Ber G I13ecx U)
14
我也挺纳闷的,不知道是不是老版本和新版本不一样。
正常应该是scale-in,然后tiup cluster display 看状态,到可以删除时候提示执行prue命令,命令都贴在display输出最后面了
普罗米修斯
16
因为ssd的存储容量够 ,v5版本low 和 high百分比是0.8 和0.7,没有容量方面的顾虑问题;tikv日志里面报出error(无效的store id),且频繁打印日志,所以IO高的调查方向转到处理这个报错和报错日志频繁打印上;
上面store remove-tomstone这个操作是在缩容完成后grafana仍然异常显示已下线监控节点,这个官网也有介绍 可以去看看
zhanggame1
(Ti D Ber G I13ecx U)
17
store remove-tomstone执行只下修改了pd,又不会修改监控,当然grafana会报错,正常应该用tiup处理的
普罗米修斯
18
不是 哥们 别纠结这个了 这个情况我们遇到很多次了,都是这么处理的,下线完成后,tikv状态转化为tombstone,grafana仍然显示该节点,pd-ctl中执行store remove-tomstone,异常节点显示就消失了,因为数据是从2379 pd中读取;
WalterWj
(王军 - PingCAP)
19
这个命令是清理掉 pd 中的 tikv 墓碑信息。
这里的完全下线状态是:执行完 scale in 和 prune 操作之后。
WalterWj
(王军 - PingCAP)
20
 如果没有执行 prune 的话,你去缩容的节点看看。。。 tikv 进程还在不在。。。
如果没有执行 prune 的话,你去缩容的节点看看。。。 tikv 进程还在不在。。。