【 TiDB 使用环境】生产环境
【 TiDB 版本】V5.4.3
【复现路径】gc_life_time由10m设置为48h后,两天后出现此现象:tidb server计算节点内存在很短时间内被耗尽,反复自动重启。
【遇到的问题:问题现象及影响】
问题现象:重启tidb后,用户访问量多时,系统运行缓慢。
影响:系统无法正常使用,查询异常缓慢,查询时间为之前的上百倍。
【资源配置】

【附件:截图/日志/监控】
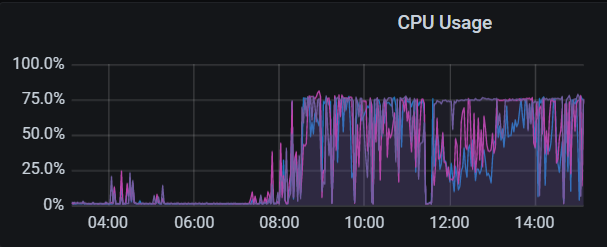
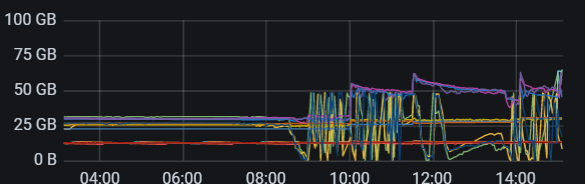
【 TiDB 使用环境】生产环境
【 TiDB 版本】V5.4.3
【复现路径】gc_life_time由10m设置为48h后,两天后出现此现象:tidb server计算节点内存在很短时间内被耗尽,反复自动重启。
【遇到的问题:问题现象及影响】
问题现象:重启tidb后,用户访问量多时,系统运行缓慢。
影响:系统无法正常使用,查询异常缓慢,查询时间为之前的上百倍。
【资源配置】
【附件:截图/日志/监控】
调大GC时间,如果集群删除数据比较多的话,可能会造成大量的mvcc版本堆积,可以找一些大的sql 看下 process_key 和 total_key 的差值来确认是否是这个问题
明显的慢查询堆积。优化sql吧
先看慢查询
gc设置的太大了吧,长时间不gc,查询会变慢
update太多的库gc时间不适合调很长,会让 查询执行速度慢很多
那请问现在查询变慢,tidb有提供机制解决此问题吗?
那请问有什么解决措施吗?
您好,那请问这个问题如何解决呢?您清楚这个问题的解决办法吗?
请问有什么及时的解决措施吗?优化sql语句是个长期的解决办法。
请问这个慢查询有解决办法嘛?
既然和gc时间有关,你调回去试试?
我们调过了,但是此问题仍然存在,gc限流也操作了,但是没有改善。
gc才48小时根本不是主要原因,我的集群现在设置的72小时都没问题,还是去优化sql吧
1、设置48小时的gc 导致内存上涨较快,频繁重启。调整回去后,集群是否恢复正常,不再重启?
2、在重启集群后,访问量较大时,查询异常缓慢。是否对比过重启前后请求量、业务版本、监控指标方面有无差异。
要想定位,还得看监控,尤其是tikv 相关的,比如region、Coprocessor。 如果想排除gc,可以看看gc 相关的指标,比如gc tasks duration。
拉上你们业务研发,再拉上DBA,一起优化看下
你这个问题,看看能否把GC时间调小,比如恢复为默认的10min。观察集群运行情况是否有好转。
然后,分析慢查询,可以从dashboard 入手排查和处理
直接拉到最慢的sql那块,看下delete_skipped_count是不是很多,如果是的话,就是删除了很多数据,gc未清理导致扫描数据量过大
调高GC的频率
把gc配置还原试试