【 TiDB 使用环境】生产环境
【 TiDB 版本】
4013
【复现路径】做过哪些操作
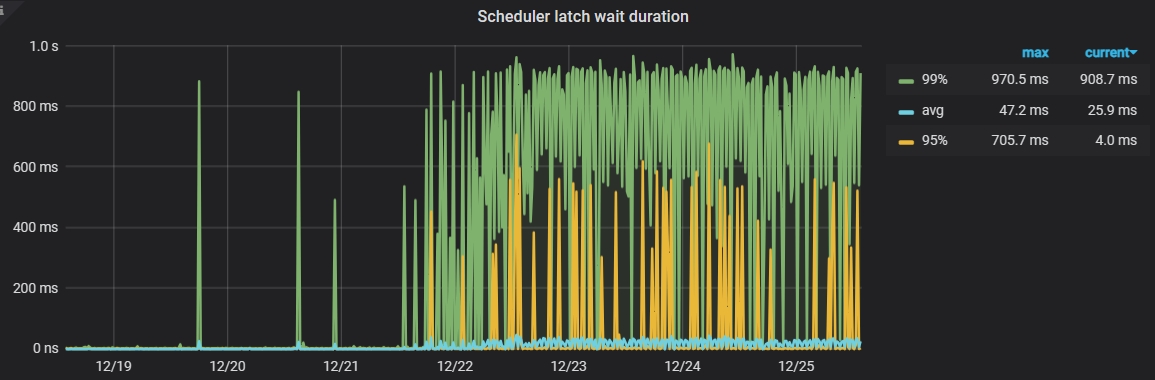
没有做出任何操作,前几天开始出现大量TiKV_scheduler_command_duration_seconds.1s
【遇到的问题:问题现象及影响】
目前业务没有啥影响
【资源配置】*
对应下图
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】
4013
【复现路径】做过哪些操作
没有做出任何操作,前几天开始出现大量TiKV_scheduler_command_duration_seconds.1s
【遇到的问题:问题现象及影响】
目前业务没有啥影响
【资源配置】*
对应下图
【附件:截图/日志/监控】
增加scheduler-concurrency是可以加速调度的执行速度
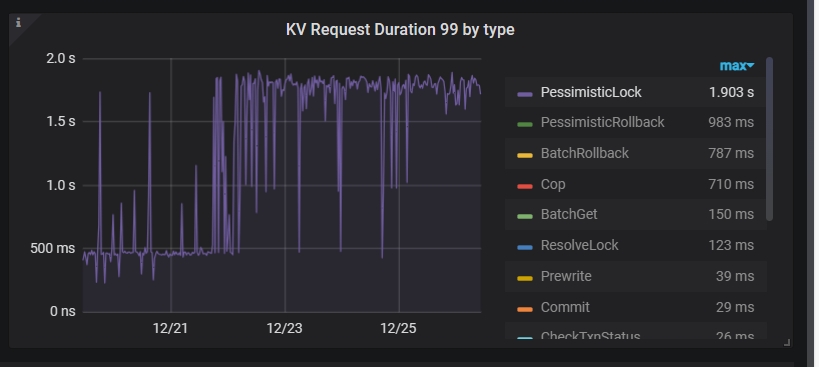
这个监控图指标高说明是分布式事务两阶段提交的第一阶段 Prewrite 比较慢。
这个阶段做的事情有两个:
所以,排查思路大概如下:
但是确实也没有发现特别慢的写入,慢日志也没啥增加,而且业务那边也没有反应,只要稍微慢一点,业务都会通知的
scheduler_latch_wait_duration 这个值一般都是在微妙级别,你的集群截图是达到了ms级别。
重点分析一下 TiDB 监控面板,看看对应 KV Errors 里的情况,尤其是 KV Backoff 相关的监控。
KV Backoff 这个告警已经关了
这个图里写得很清楚了,是有很高的锁冲突。
业务侧应该会有感知的,确认一下具体SQL,然后优化业务访问方式吧,适当减小并发或优化SQL。
for update啊,这个一般很容易造成锁冲突吧,跟开发确认下为啥要用这个吧。。。
嗯,就是这个语句导致的,平均2S,单独吧这个业务迁移到mysql了,报警就消失了
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。