【 TiDB 使用环境】生产环境
【 TiDB 版本】 5.3.3
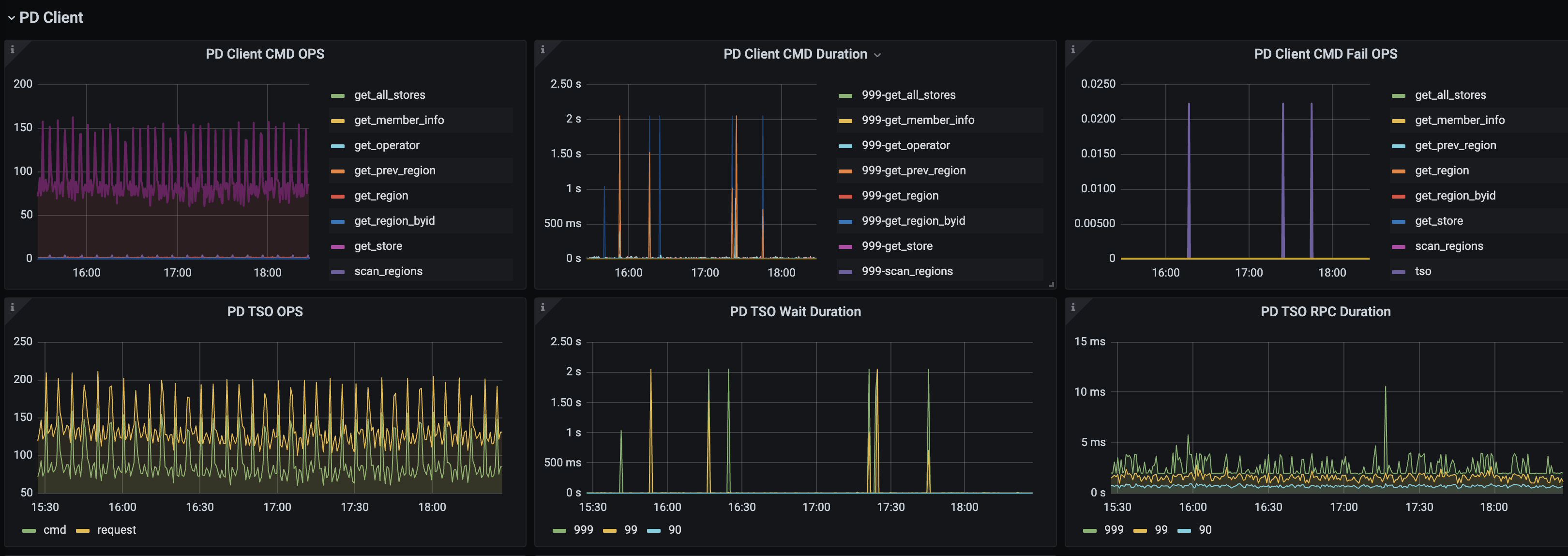
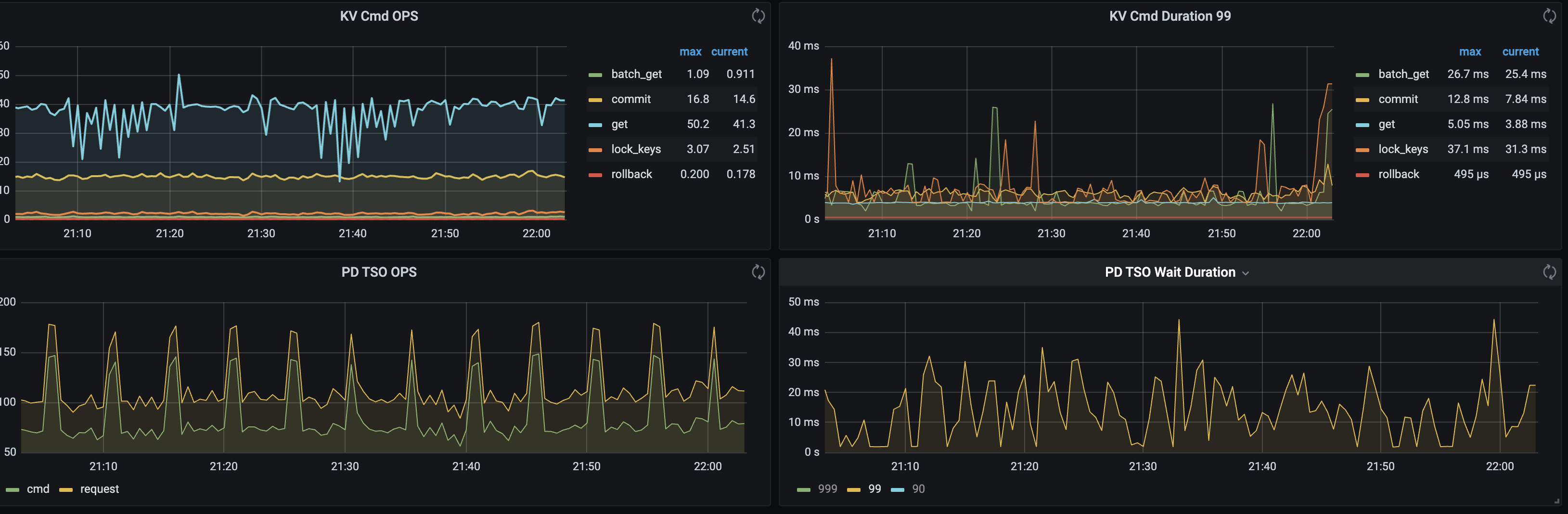
tidb监控显示获取tso 时间长
慢查询里面确实显示是获取tso时间长:
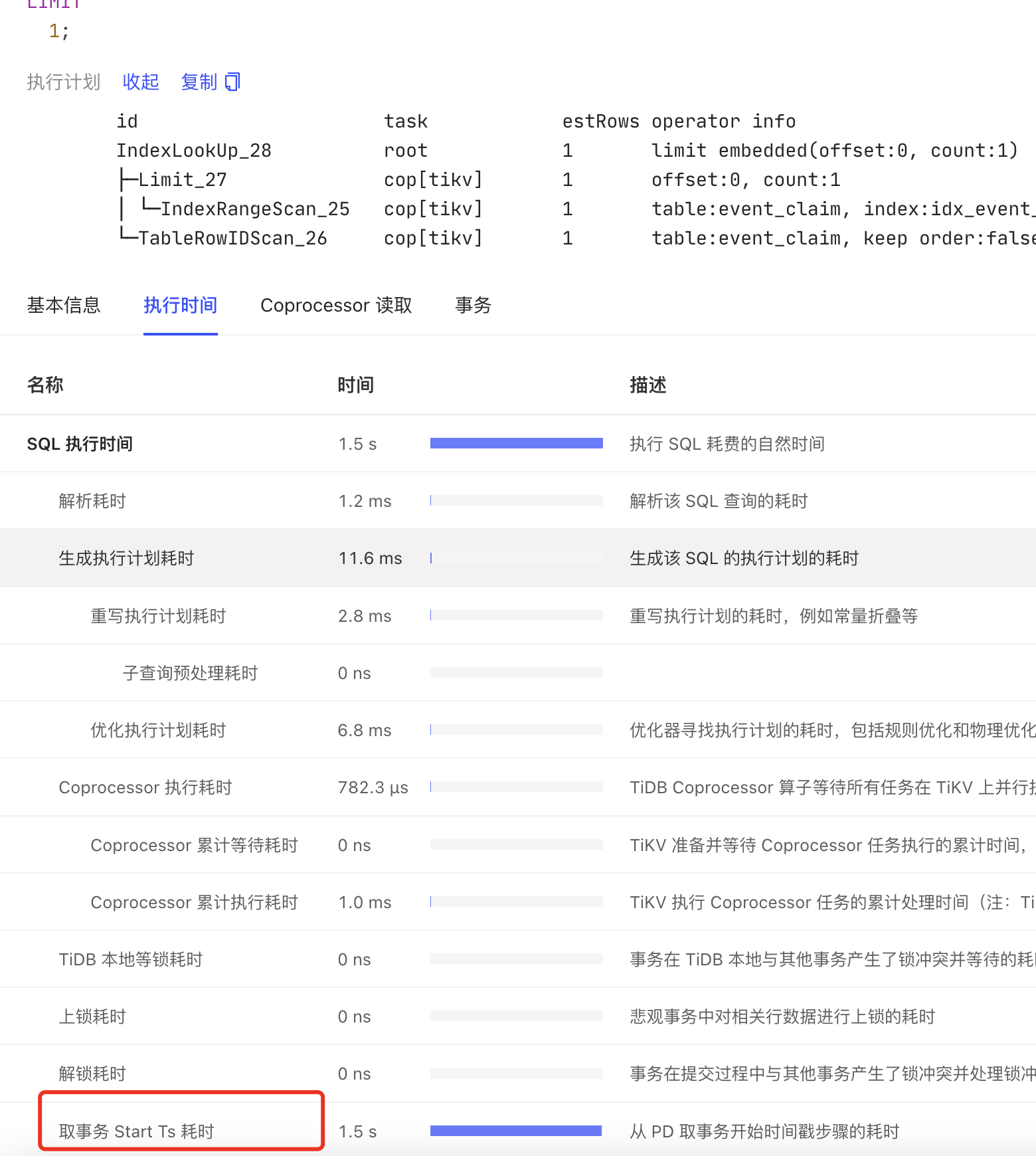
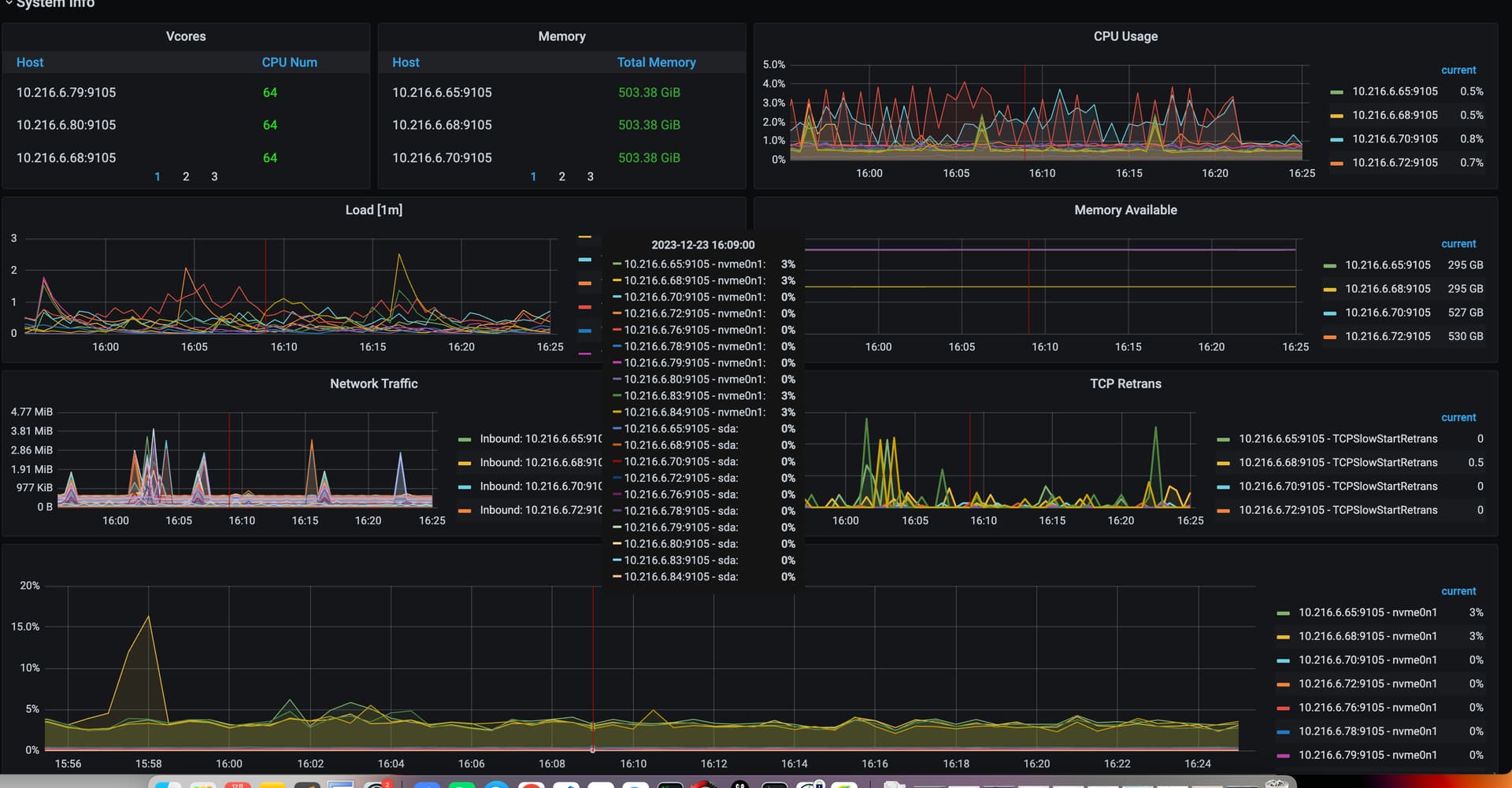
机器配置是64c512G,磁盘是nvme的
获取 startTS 是 tidb-server 去访问 PD Leader 拿到的 TSO,这块时间比较久,就需要排查这条链路的相关监控情况。
可以分下面几个方向进行排查和确认:
1.持续ping了一会,网络时延和网络抖动应该都没有。
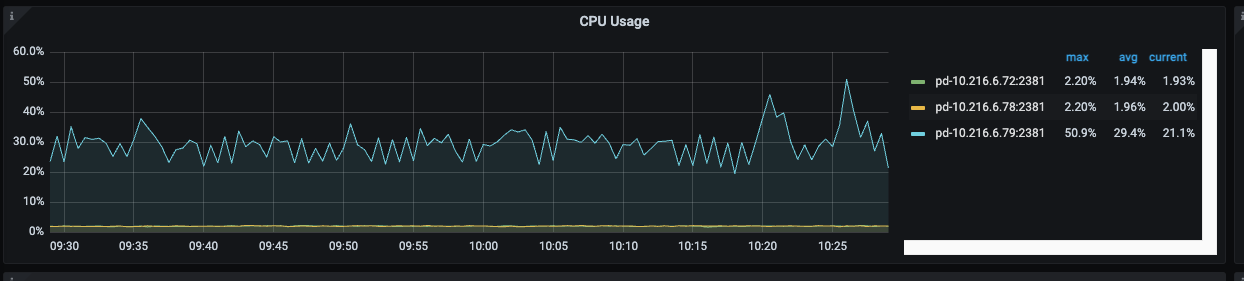
2.pd leader 的cpu使用率很低,pd使用的是64核的物理机,nvme的磁盘。
3. 这块看起来pd是没有问题;但是pd client 的cmd duration操作确实很慢。
切下pd leader试试
日志呢,确认一下 tidb.log 和 pd.log 有无异常日志
日志检查也没有什么发现。
查看PD的负载情况,还有网络状况
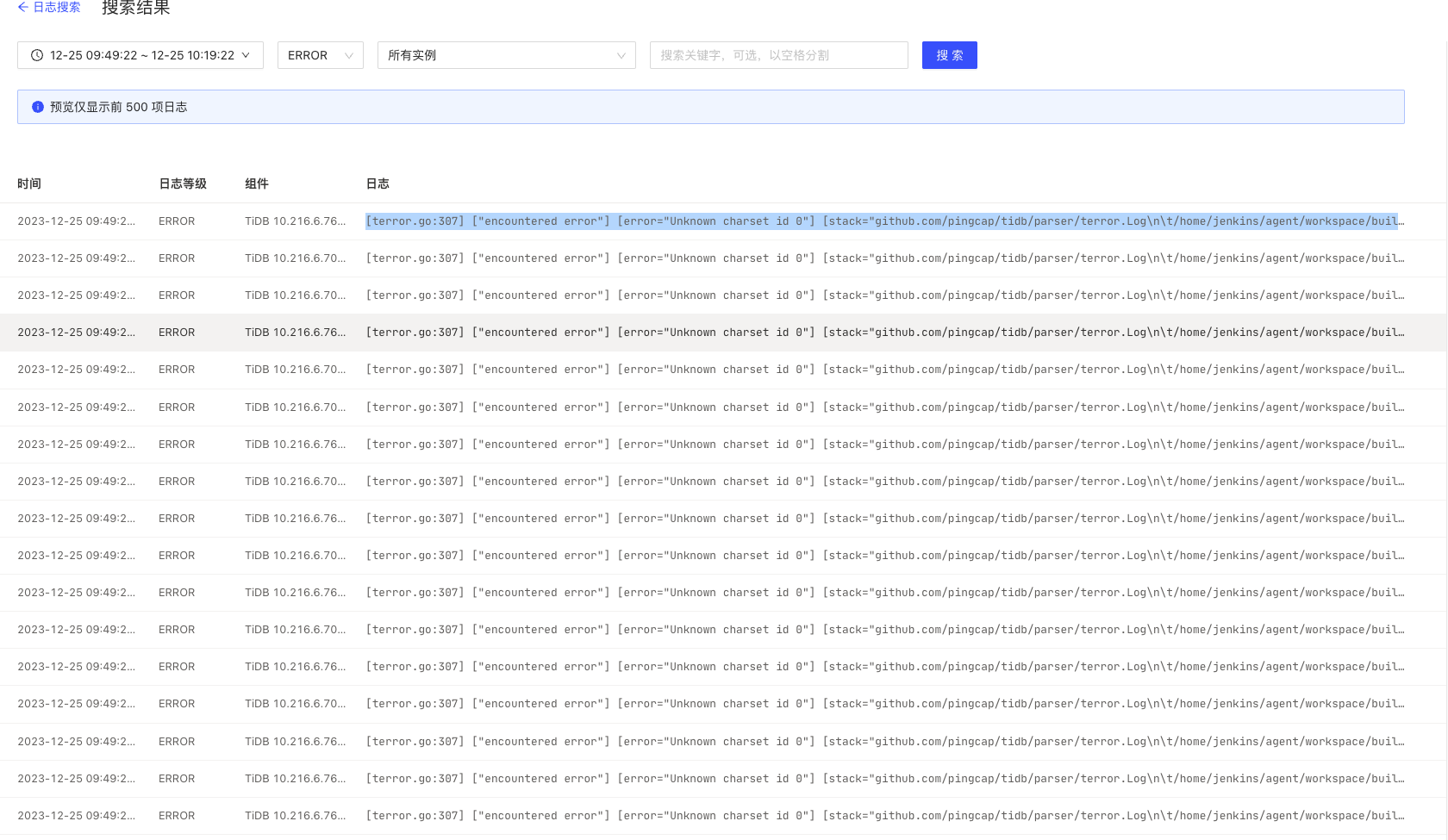
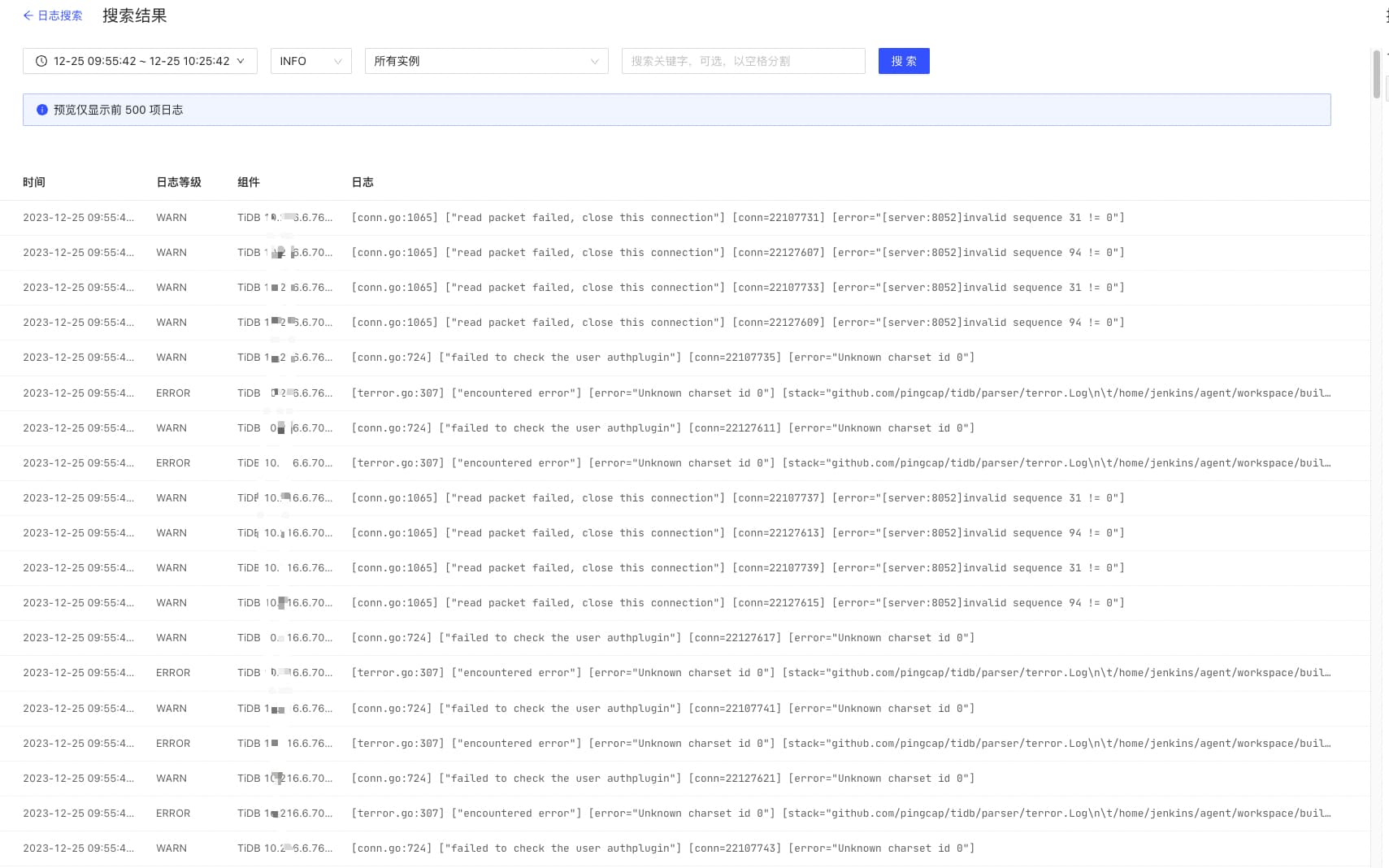
tidb server上 报错信息如下:
[terror.go:307] [“encountered error”] [error=“Unknown charset id 0”] [stack=“github.com/pingcap/tidb/parser/terror.Log\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/parser/terror/terror.go:307\ngithub.com/pingcap/tidb/server.(*Server).onConn\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/server/server.go:520”]
tidb-server的所有日志:
[conn.go:1065] [“read packet failed, close this connection”] [conn=22107731] [error=“[server:8052]invalid sequence 31 != 0”]
[conn.go:724] [“failed to check the user authplugin”] [conn=22107735] [error=“Unknown charset id 0”]
pd的性能问题吧
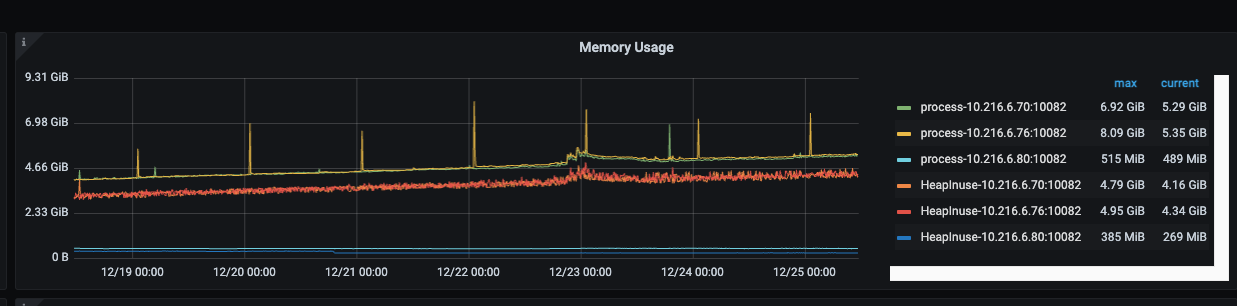
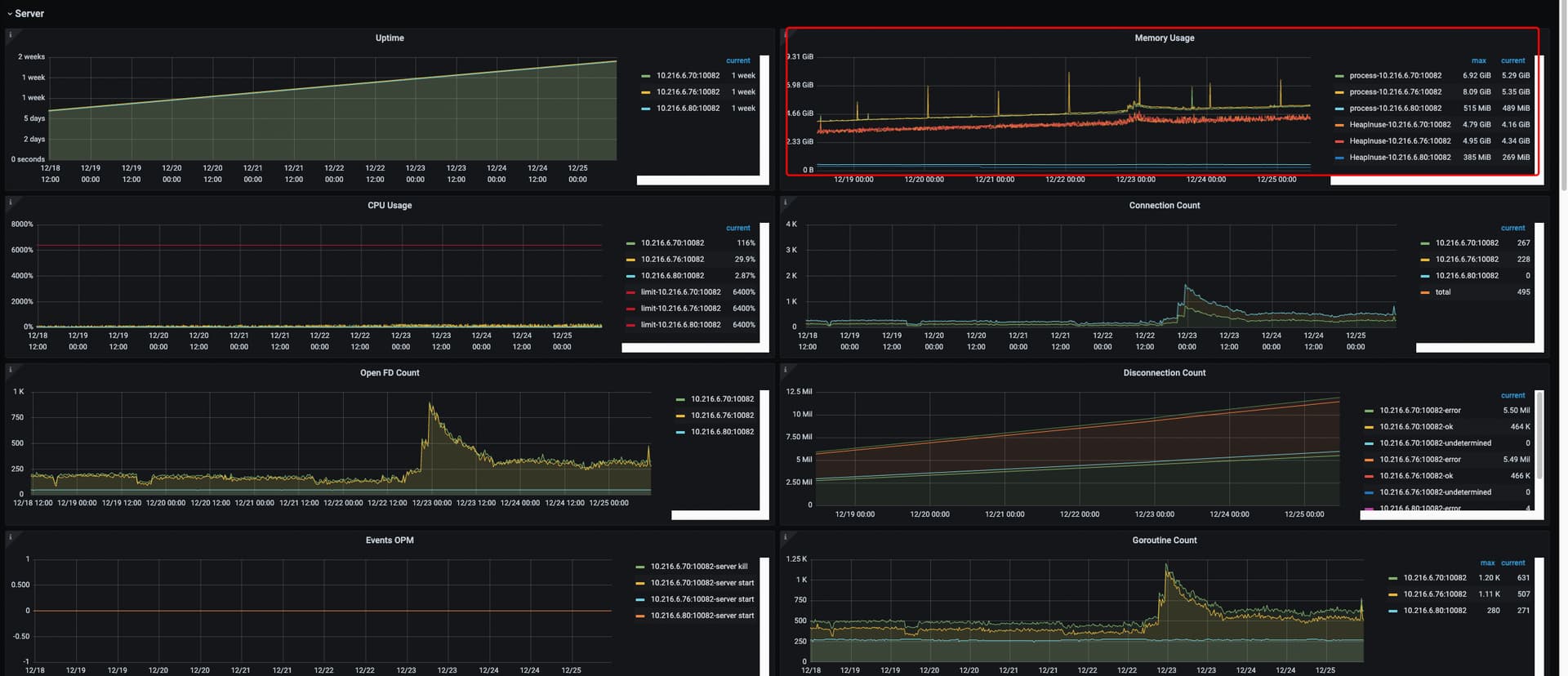
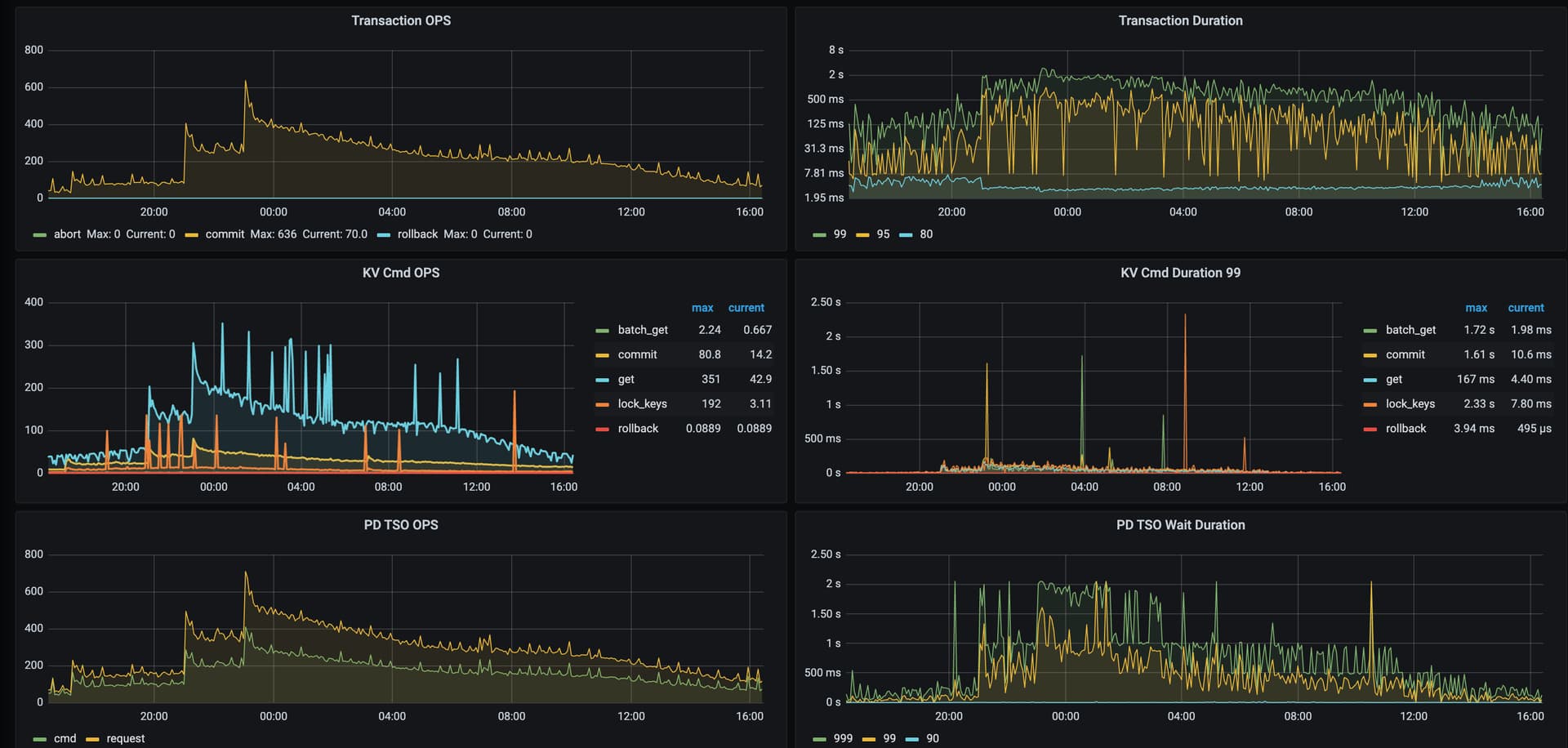
看监控感觉像是tidb-server的问题;但是是什么问题,还看不出来。
不知道服务器的numa没有关闭会不会导致这个问题?
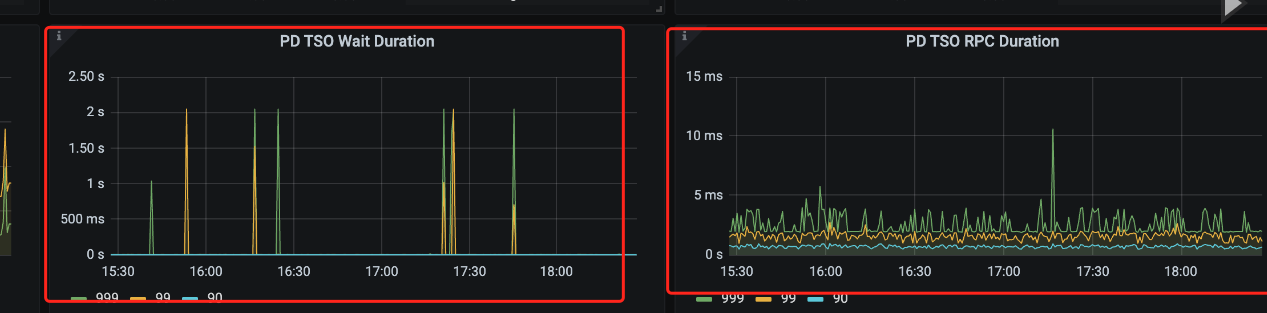
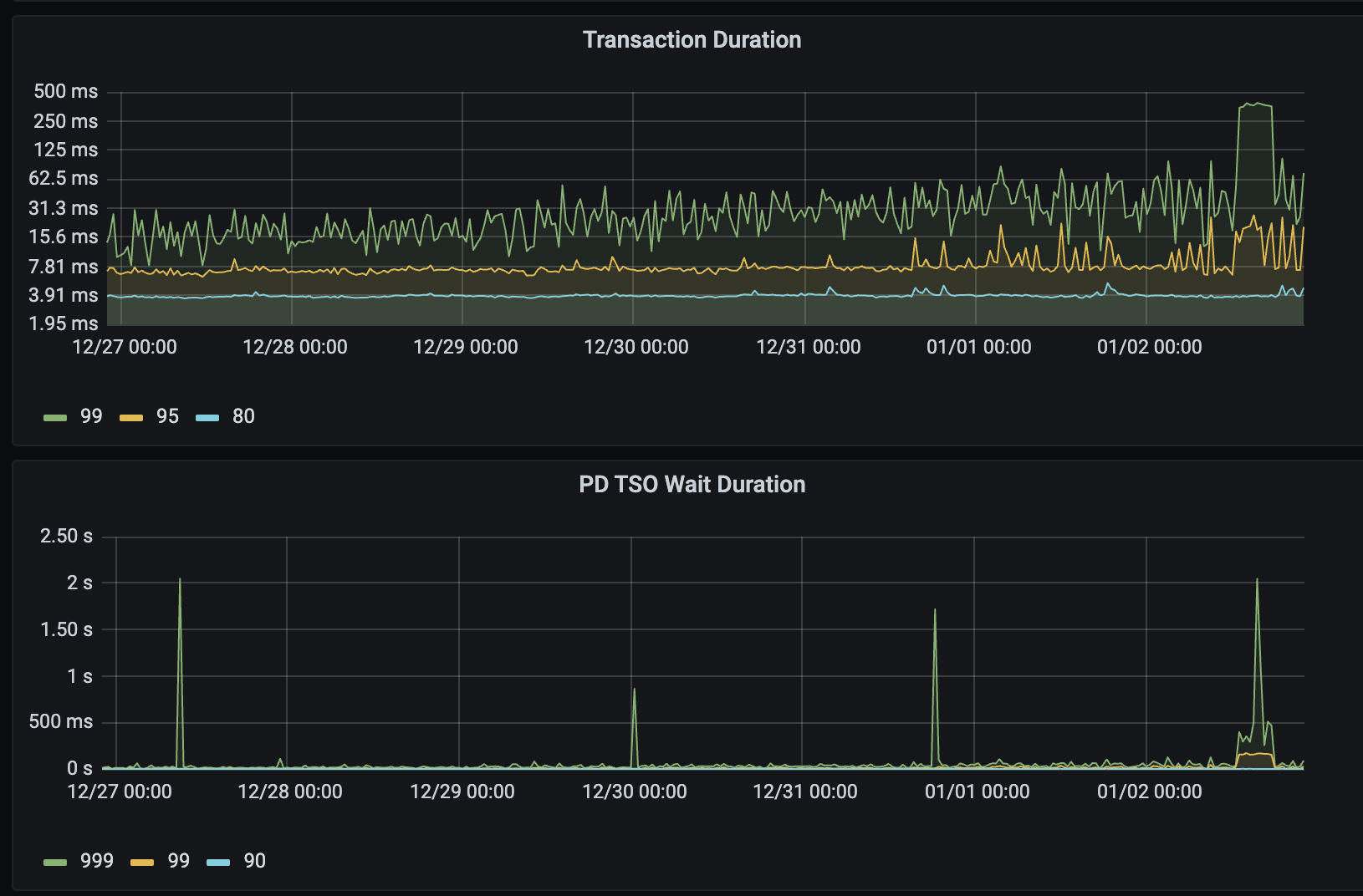
另外,start tso wait duration的监控图能发下么?
1、是混部了另外一个 tidb节点,但是这个混部的几乎没有访问;我下午准备把这个集群的节点拆到其他机器上看看。
目前用新的机器tidb-server拆出去后,获取tso到10毫秒以内了,不过还得再观察。
也看一下业务运行的情况