【 TiDB 使用环境】生产环境
【 TiDB 版本】V7.1.1
【遇到的问题:问题现象及影响】
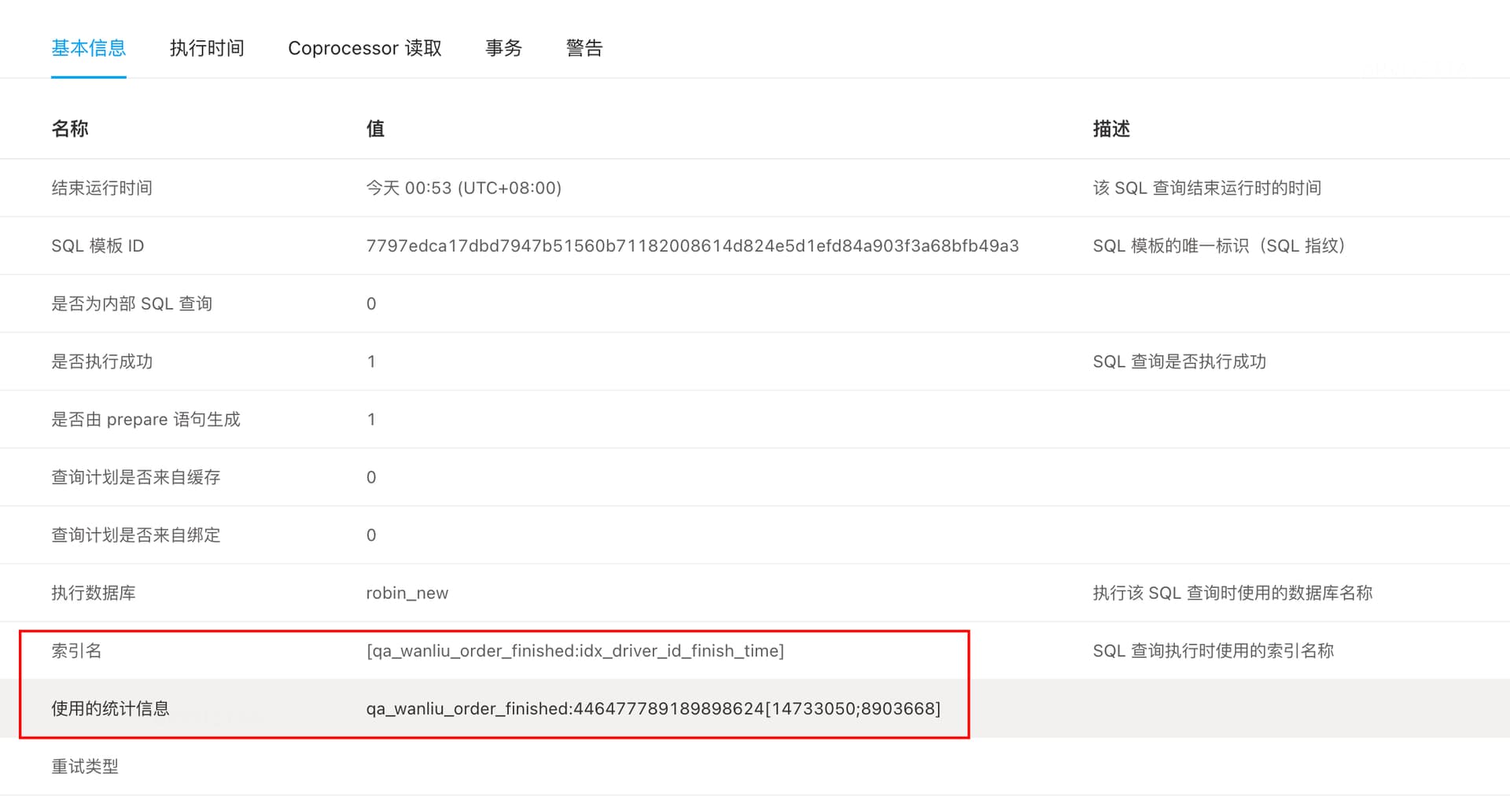
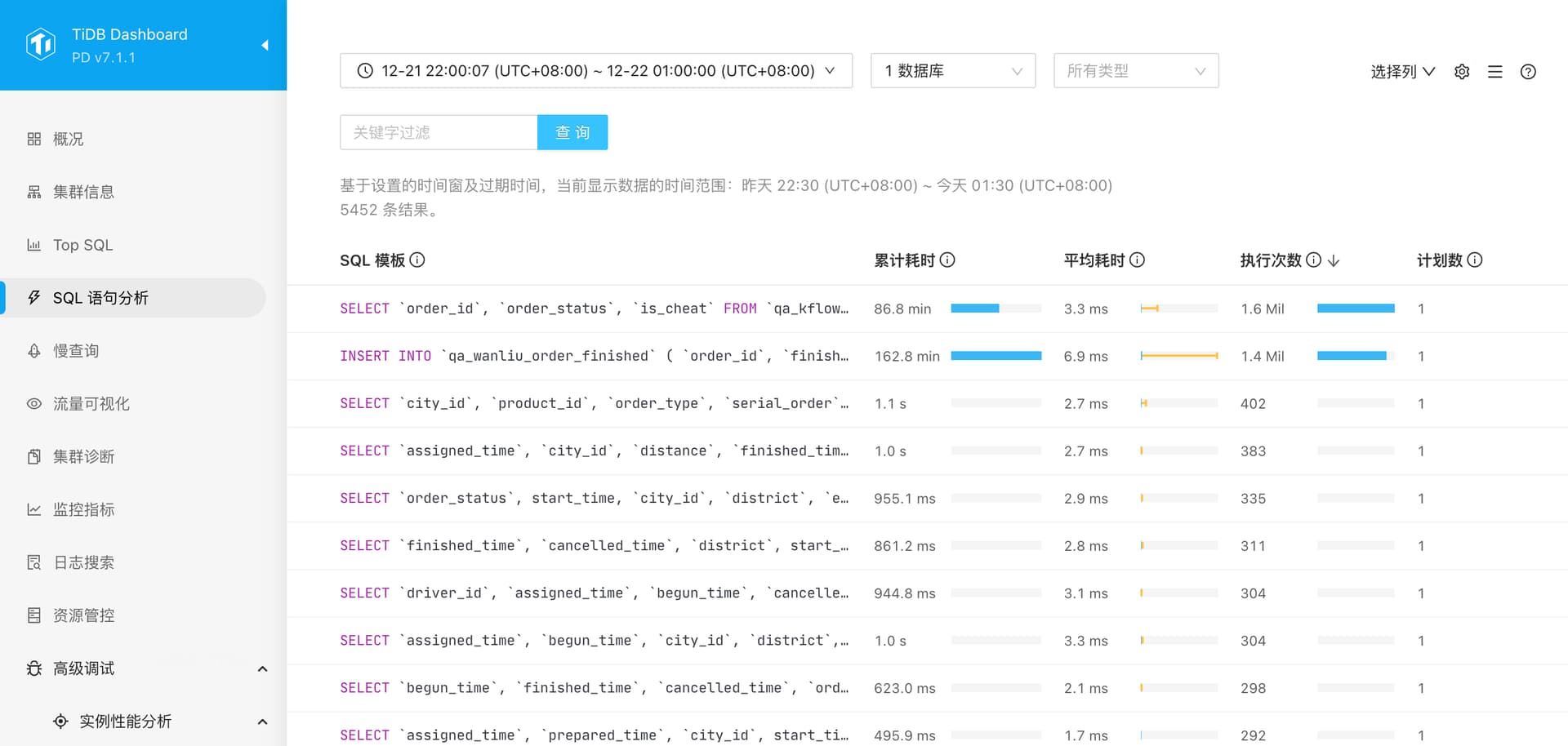
1.命中索引的扫描,扫描行数在14-700条之间,但执行期间偶尔会从几十ms抖动到几百ms
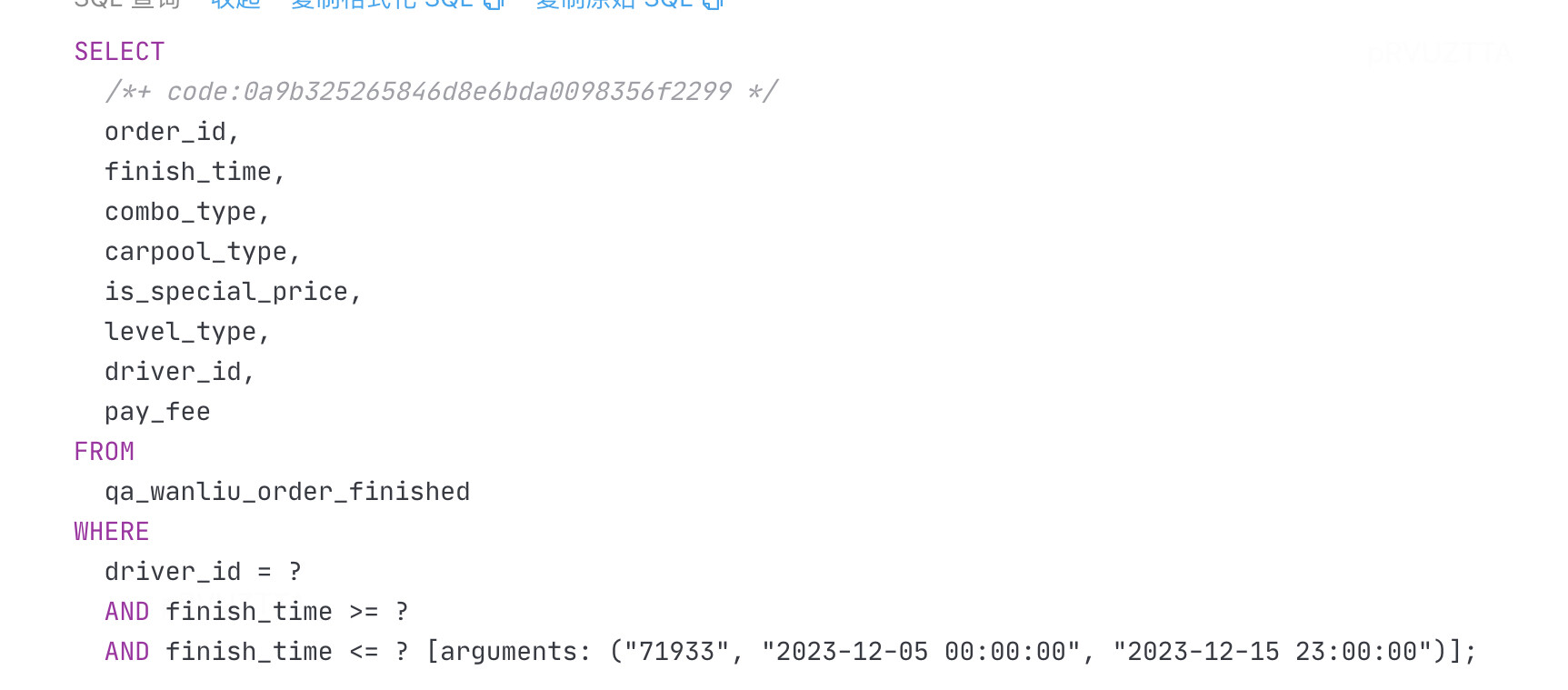
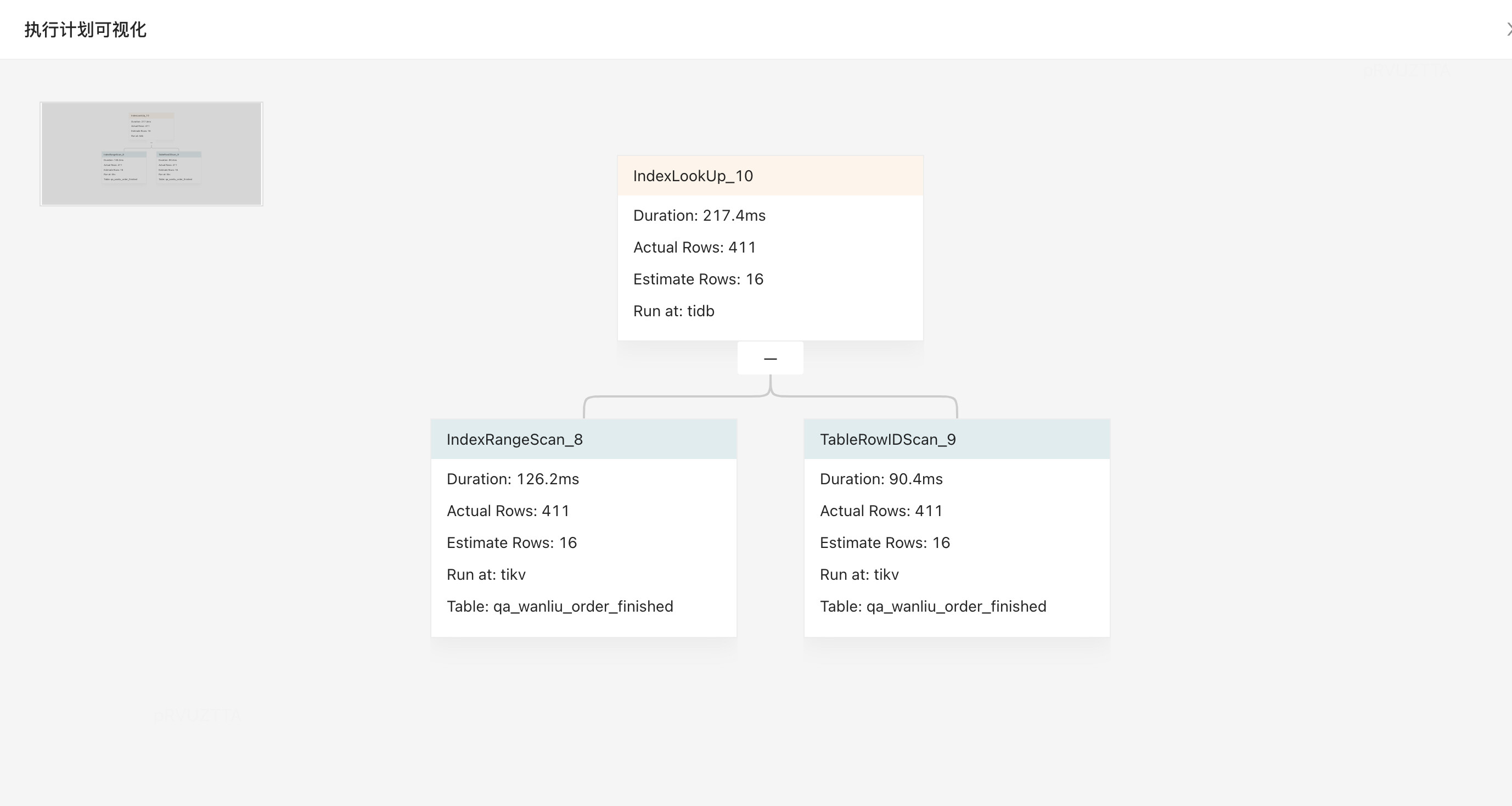
执行计划
| id | task | estRows | operator info | actRows | execution info | memory | disk | |
|---|---|---|---|---|---|---|---|---|
| IndexLookUp_10 | root | 16.03 | 411 | time:217.4ms, loops:2, index_task: {total_time: 126.2ms, fetch_handle: 126.2ms, build: 980ns, wait: 3.75µs}, table_task: {total_time: 91ms, num: 1, concurrency: 5}, next: {wait_index: 126.3ms, wait_table_lookup_build: 497.5µs, wait_table_lookup_resp: 90.4ms} | 94.5 KB | N/A | ||
| ├─IndexRangeScan_8(Build) | cop[tikv] | 16.03 | table:qa_wanliu_order_finished, index:idx_driver_id_finish_time(driver_id, finish_time), range:[71933 2023-12-05 00:00:00,71933 2023-12-15 23:00:00], keep order:false | 411 | time:126.2ms, loops:3, cop_task: {num: 2, max: 65.1ms, min: 60.9ms, avg: 63ms, p95: 65.1ms, max_proc_keys: 224, p95_proc_keys: 224, tot_proc: 820.9µs, tot_wait: 124.5ms, rpc_num: 2, rpc_time: 126ms, copr_cache_hit_ratio: 0.00, build_task_duration: 26.3µs, max_distsql_concurrency: 1}, tikv_task:{proc max:0s, min:0s, avg: 0s, p80:0s, p95:0s, iters:6, tasks:2}, scan_detail: {total_process_keys: 411, total_process_keys_size: 48498, total_keys: 413, get_snapshot_time: 70.2ms, rocksdb: {key_skipped_count: 411, block: {cache_hit_count: 27}}} | N/A | N/A | |
| └─TableRowIDScan_9(Probe) | cop[tikv] | 16.03 | table:qa_wanliu_order_finished, keep order:false | 411 | time:90.4ms, loops:2, cop_task: {num: 34, max: 85.9ms, min: 2.14ms, avg: 15.5ms, p95: 56ms, max_proc_keys: 19, p95_proc_keys: 18, tot_proc: 22.5ms, tot_wait: 456.7ms, rpc_num: 34, rpc_time: 524.9ms, copr_cache_hit_ratio: 0.00, build_task_duration: 142.6µs, max_distsql_concurrency: 1, max_extra_concurrency: 14}, tikv_task:{proc max:31ms, min:0s, avg: 1.65ms, p80:1ms, p95:3ms, iters:34, tasks:34}, scan_detail: {total_process_keys: 411, total_process_keys_size: 120631, total_keys: 425, get_snapshot_time: 274ms, rocksdb: {key_skipped_count: 42, block: {cache_hit_count: 4352}}} | N/A | N/A |
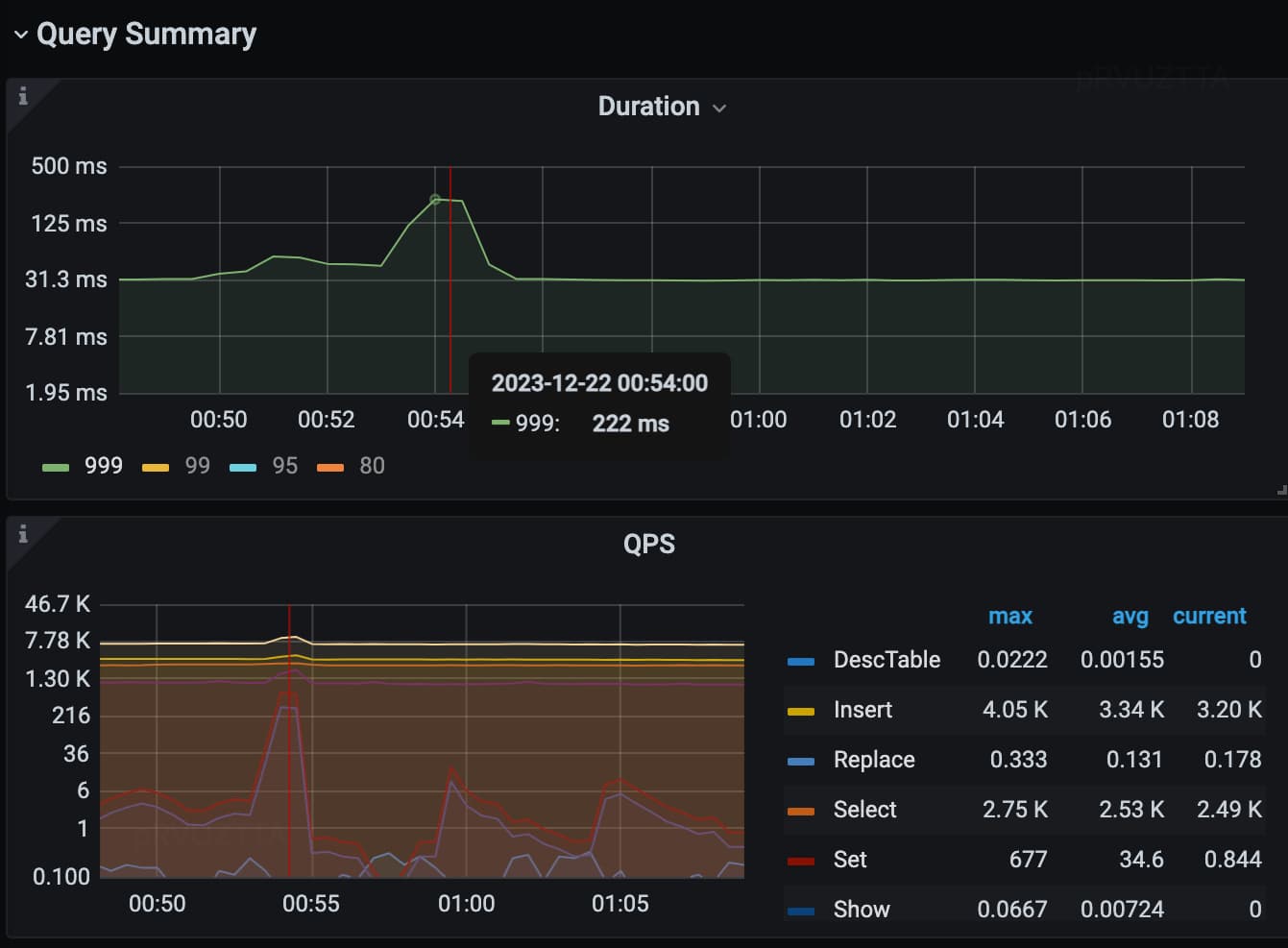
当时总体QPS
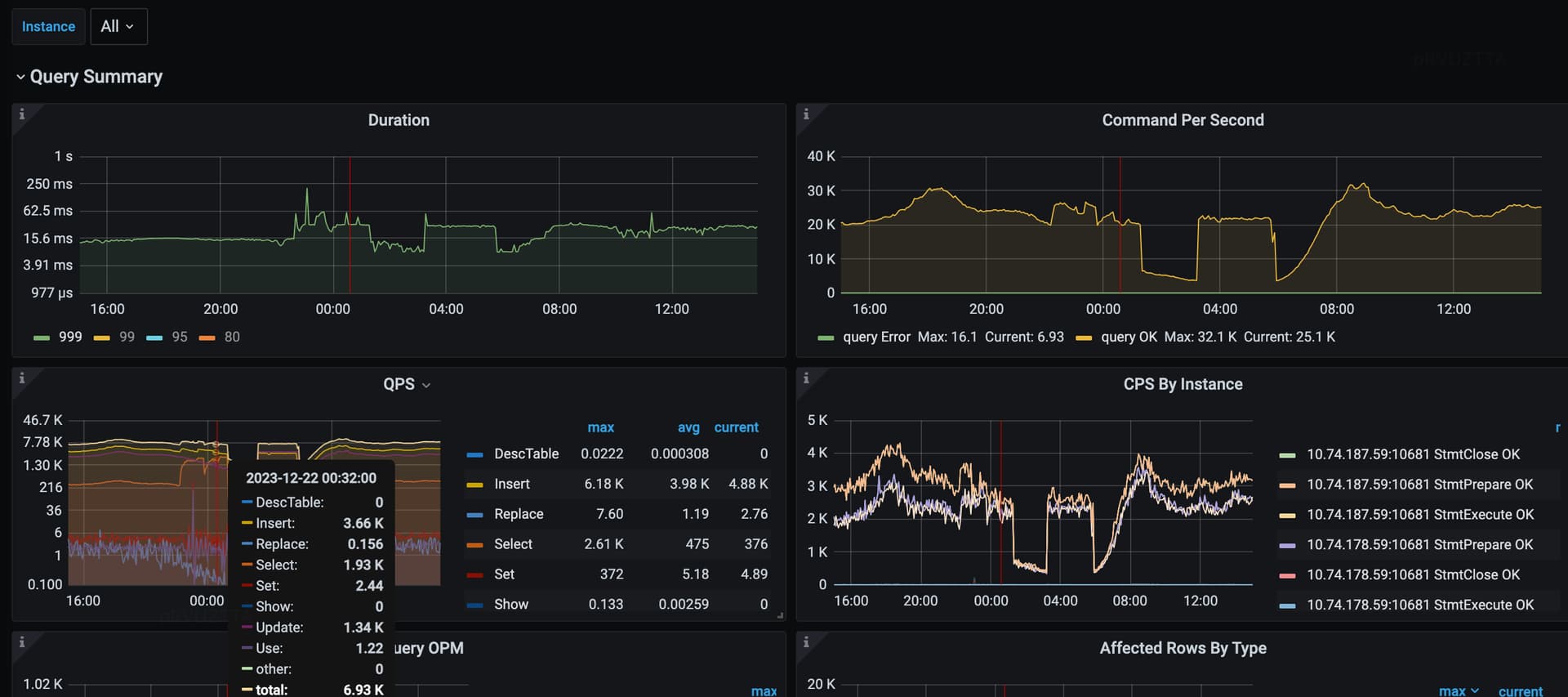
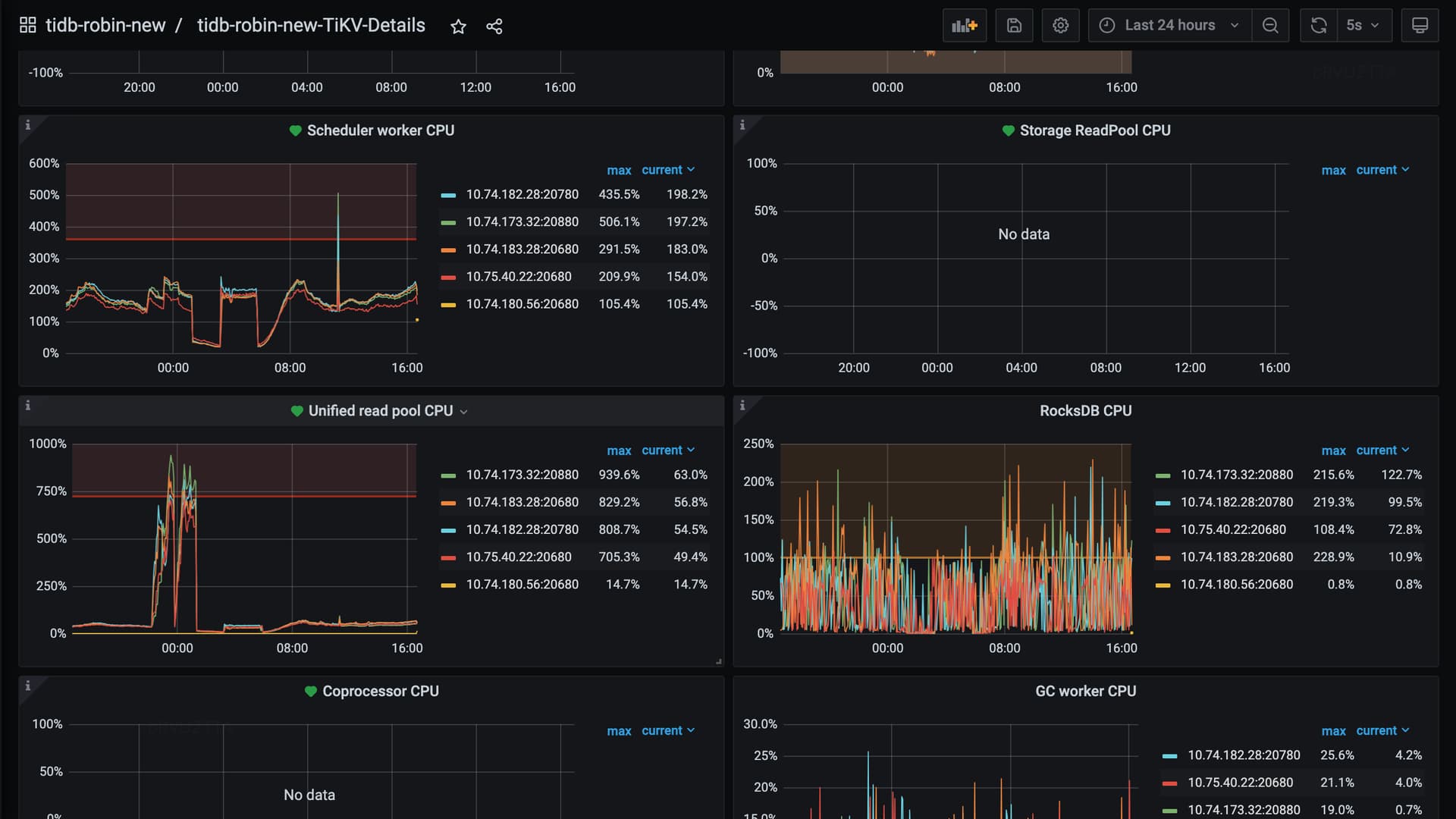
TIKV监控

【资源配置】
7T nvme,48超线程,125G内存