【 TiDB 使用环境】生产环境 /测试/ Poc
我这有一个集群只有3个kv、3pd、3个tidb,平均qps也不高一千左右,prometheus每天产生的数据有3G多,保留半年数据需要靠近600G磁盘,这正常吗?
你们在生产环境用上了吗?我还在学习阶段呢。前不久刚接触。不过我们能用上的可能性较小。
用的人挺多的啊
蹲一下。我们有个生产集群一天30g,不知道啥情况 ![]()
我这个是从库,只有6台机器,基本没什么访问量,感觉数据量不正常。
截图里是wal目录下的内容吗?
prometheus各子目录占用是什么情况?wal多吗?
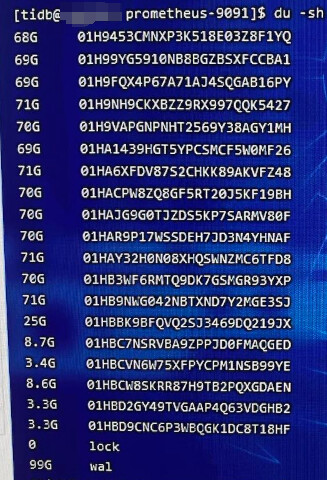
我还说少了,是70g左右。看起来wal也不少
看了下我们的一天最多3G 你们这磁盘挺大的 ![]()
1、prometheus data 01开头的目录占用多,说明采集到的数据多,可以通过curl tidb/tikv/pd各组件的metrics接口, 看下返回行数。如果返回行数在数十万、百万行的话,确实不正常,这就需要抛弃掉一些metrics了。一般来讲tikv的metrics可能会异常,可以在 prometheus.yml文件 - job_name: "tikv"处最下方增加如下配置来减少数据采集,然后通过tiup 重启下prometheus。不过拓扑变更的话此配置会被回滚掉。
metric_relabel_configs:
- source_labels: [name]
separator: ;
regex: tikv_thread_nonvoluntary_context_switches|tikv_thread_voluntary_context_switches|tikv_threads_io_bytes_total
action: drop
- source_labels: [name,name]
separator: ;
regex: tikv_thread_cpu_seconds_total;(tokio|rocksdb).+
action: drop
2、如果wal多,可能是prometheus没有及时checkpoint, 一般是因为采集数据量大
可以在log/promethues.log日志文件过滤Starting TSDB …和TSDB started关键词,看prometheus是否经常重启。不过按照第1步操作的话会减少这种情况。
3 个赞
感谢解答 ![]()
![]()
![]()
![]()
tidb采集的metric太多了,如果都按照这样配置是不是太麻烦了。
是挺麻烦的,reload等操作配置都会被覆盖,tiup cluster edit-config没有找到可以这样配置的地方。要么就是tiup操作之外再封装一层对prometheus.yml的操作
看下prometheus ui中的指标统计信息,是不是有指标泄漏的情况,如果有某个指标占用空间过大,请参考这个配置不收集该指标项:
https://docs.pingcap.com/zh/tidb/stable/customized-montior-in-tiup-environment#自定义-prometheus-scrape-配置
1 个赞
这个可以的,不过我们最高5.2版本,用不了 ![]()
是tiup cluster edit-config 编辑集群配置然后在monitoring_servers这边添加metric_relabel_configs规则?这样是否每个节点都会生效?
我看文档写的不够详细。

你去prometheus配置文件看下最终生成的配置文件就好了
应该不影响,这个功能是tiup实现的功能,升级下tiup就好了
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。