脚本小王子
(脚本小王子)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.3.0
【复现路径】生产环境无法人为复现
【遇到的问题:问题现象及影响】
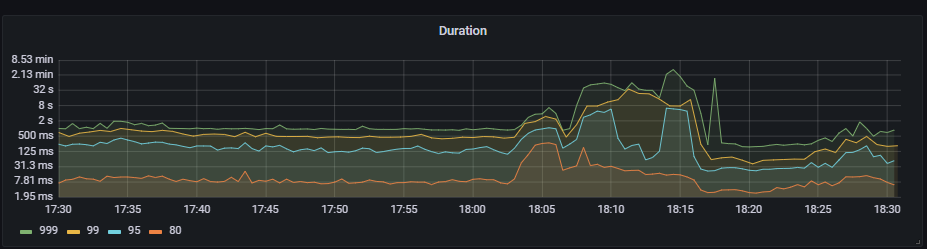
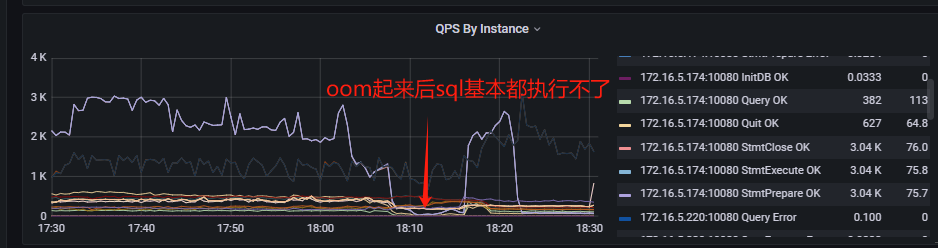
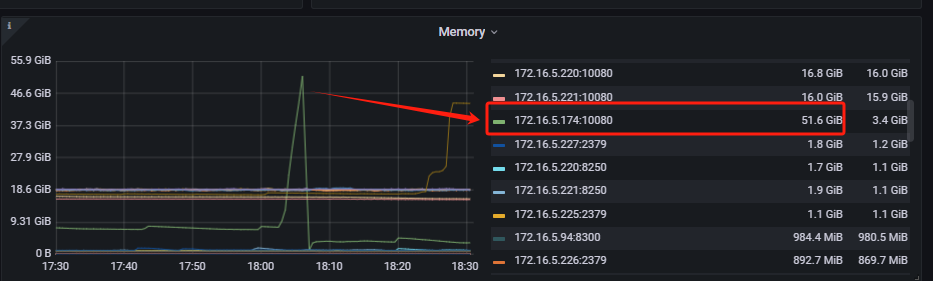
其中一台TiDB-Server发生OOM,服务起来后,执行SQL慢(甚致是执行不出来),大量sql语句堆积,某个表流量很高,执行show stats_healthy无任何结果输出,即使把业务停掉,把sql全kill掉,查询一些小表也依然查不出来,执行ANALYZE TABLE一张只有几条记录的表也没反应,只能等约十分钟左右,执行show stats_healthy有结果输出后,所有sql才能恢复正常。
这个问题从本周一第一次发生,然后每天基本都会发生1~2次,以前也经常发生过oom,但服务起来后TiDB-Server是正常的。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
log.rar (347.8 KB)
没头脑123
2
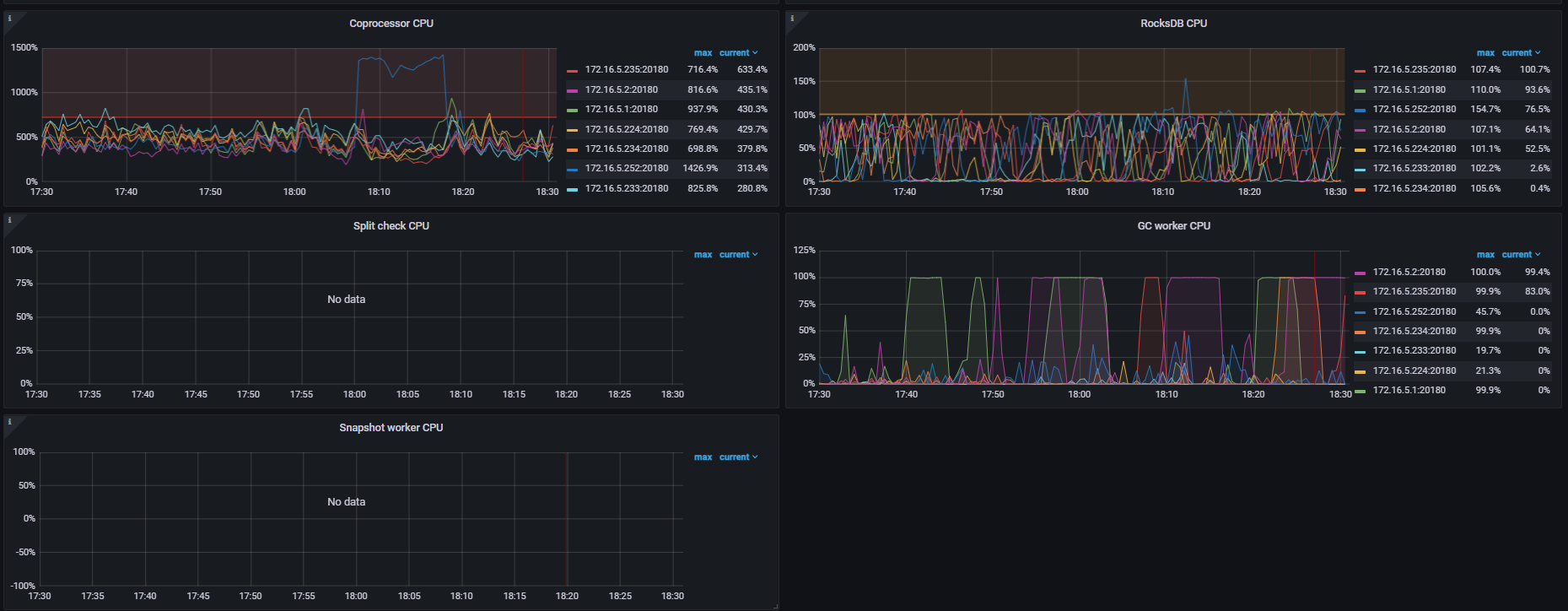
读写慢可能是TiKV 重启后重新选举,同时查看下 block-cache是否配置太大
zxgaa
(Ti D Ber Ji W Bubwr)
3
如果给的缓存比较大的,是比较慢,我现在重启我们集群的tidb-Server,至少要等个一两个小时才能加载完
1 个赞
脚本小王子
(脚本小王子)
5
以前也经常OOM,但起来后就好了,只是这周一开始才这样
小龙虾爱大龙虾
(Minghao Ren)
7
看下SQL跑的是不是都是错误的执行计划,看下启动日志,关注下init stats
1 个赞
tidb-server重启的时候会重新加载统计信息,如果加载时间过长就会强制停止加载后直接启动,这时候有一些sql可能会走到错误的执行计划上,导致对tikv的数据进行大量的扫描造成数据库大量的慢sql。我觉得你还是先分析你oom的原因吧,tidb-server虽然是无状态的,但是老是oom对业务也是有影响的。
1 个赞
脚本小王子
(脚本小王子)
10
感谢回复。
执行计划倒没错,我把卡住很久的sql取出来explan看是没问题的,另外TiDB-Server启动的时候日志报“[ERROR] [client.go:845] [“[pd] update connection contexts failed”] [dc=global] [error=“rpc error: code = Canceled desc = context canceled”]” 和较多的"get timestamp too slow" 不知有没影响
脚本小王子
(脚本小王子)
11
感谢回复。
方法应该是可行的,就是如果有其它解决办法还是不希望通过升级数据库来解决,毕竟升级可能会有很多未知的风险
脚本小王子
(脚本小王子)
13
不同TiDB-Server对应不同的业务,因此配置差得有点多
单个tikvcpu 高可以在topsql中查看那些sql使用资源多
脚本小王子
(脚本小王子)
15
是的,刚启动的时候基本什么sql都执行不出来,但切到另外一台tidb是可以正常执行出来
脚本小王子
(脚本小王子)
16
单个tikv cpu高应该是有一个表存在大量的读导致,但这也不能解释在刚启动的tidb-server里sql执行不出来,同样的sql在另一台tidb-server是可以很快执行出来
脚本小王子
(脚本小王子)
17
感谢回复。
奇怪的是,执行不出来的sql,在同一台的tidb-server里explain看执行计划是正常的。
oom是需要解决,但tidb很难根本杜绝oom,因此这个问题也需要解决
wluckdog
(lili)
18
在oom的tidb实例上可以找到引起oom 相关的SQL,消耗资源比较大的SQL关键字expensive_query ,查看执行计划是否有全表扫描,避免OOM,你这里tikv实例才32G内存比较小,一旦 有全表扫描对集群io影响比较大吧,show stats_healthy只能查看表的统计信息是否健康
1 个赞