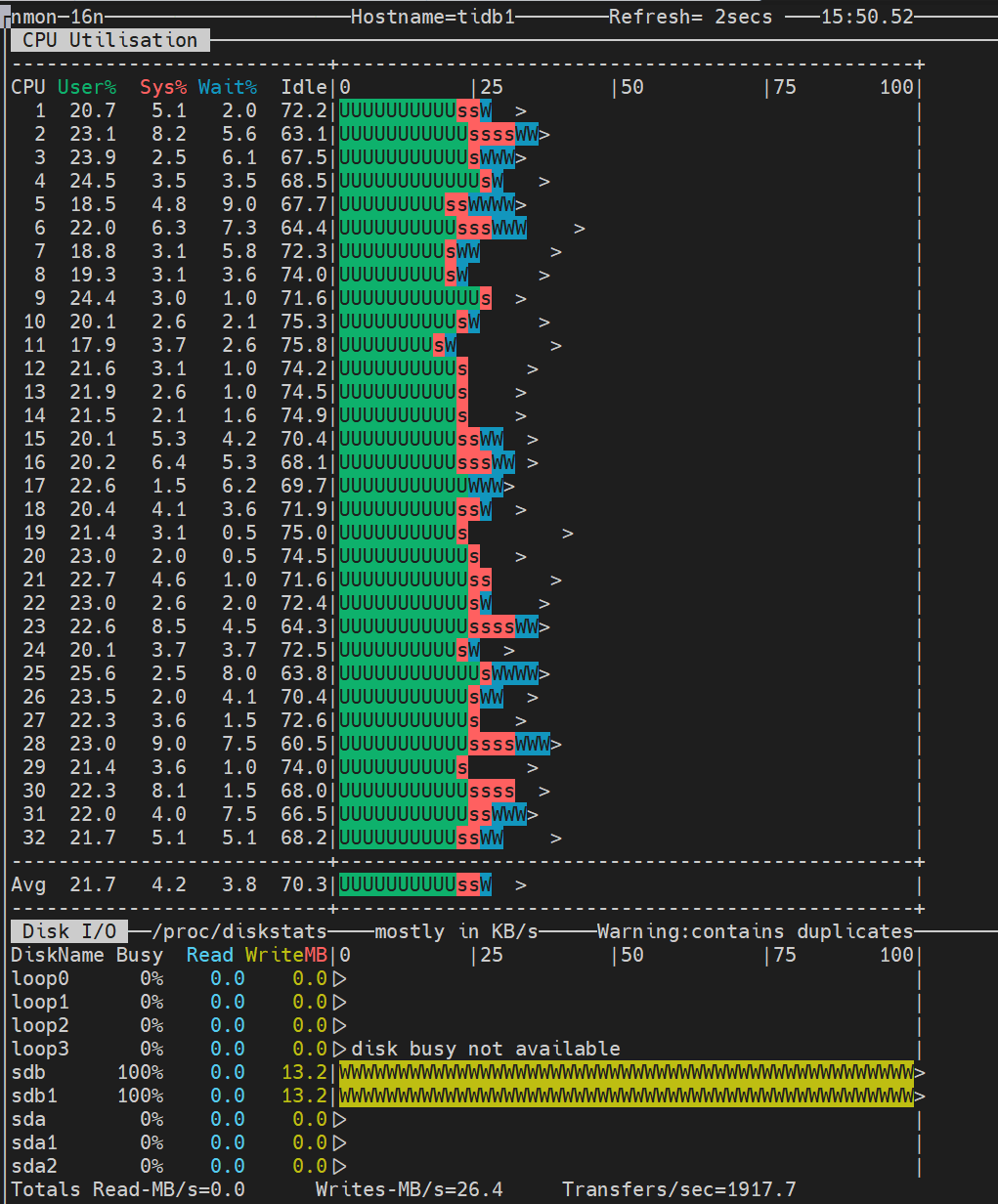
sata的ssd,fio测试结果:
root@tidb1:/tidb-data# fio --bs=64k --ioengine=libaio --iodepth=64 --direct=1 --rw=write --numjobs=32 --time_based --runtime=30 --randrepeat=0 --group_reporting --name=fio-read --size=10G --filename=/tidb-data/fiotest
fio-read: (g=0): rw=write, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=64
...
fio-3.28
Starting 32 processes
fio-read: Laying out IO file (1 file / 10240MiB)
Jobs: 32 (f=32): [W(32)][100.0%][w=889MiB/s][w=14.2k IOPS][eta 00m:00s]
fio-read: (groupid=0, jobs=32): err= 0: pid=55609: Fri Dec 15 08:06:36 2023
write: IOPS=14.1k, BW=878MiB/s (921MB/s)(25.8GiB/30021msec); 0 zone resets
slat (usec): min=12, max=26231, avg=2261.86, stdev=1810.65
clat (msec): min=5, max=240, avg=143.15, stdev=15.15
lat (msec): min=10, max=243, avg=145.41, stdev=15.31
clat percentiles (msec):
| 1.00th=[ 101], 5.00th=[ 118], 10.00th=[ 125], 20.00th=[ 133],
| 30.00th=[ 138], 40.00th=[ 142], 50.00th=[ 144], 60.00th=[ 148],
| 70.00th=[ 153], 80.00th=[ 155], 90.00th=[ 161], 95.00th=[ 165],
| 99.00th=[ 176], 99.50th=[ 180], 99.90th=[ 190], 99.95th=[ 197],
| 99.99th=[ 205]
bw ( KiB/s): min=627878, max=1030656, per=99.67%, avg=896516.98, stdev=1800.37, samples=1888
iops : min= 9810, max=16104, avg=14008.07, stdev=28.13, samples=1888
lat (msec) : 10=0.01%, 20=0.02%, 50=0.10%, 100=0.84%, 250=99.04%
cpu : usr=0.74%, sys=5.20%, ctx=514522, majf=0, minf=417
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.2%, >=64=99.5%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwts: total=0,421935,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
WRITE: bw=878MiB/s (921MB/s), 878MiB/s-878MiB/s (921MB/s-921MB/s), io=25.8GiB (27.7GB), run=30021-30021msec
Disk stats (read/write):
sdb: ios=0/408267, merge=0/14825, ticks=0/7087369, in_queue=7087370, util=100.00%
root@tidb1:/tidb-data# fio --bs=4k --ioengine=libaio --iodepth=64 --direct=1 --rw=write --numjobs=32 --time_based --runtime=30 --randrepeat=0 --group_reporting --name=fio-read --size=10G --filename=/tidb-data/fiotest
fio-read: (g=0): rw=write, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
...
fio-3.28
Starting 32 processes
Jobs: 32 (f=32): [W(32)][100.0%][w=642MiB/s][w=164k IOPS][eta 00m:00s]
fio-read: (groupid=0, jobs=32): err= 0: pid=55716: Fri Dec 15 08:07:35 2023
write: IOPS=163k, BW=637MiB/s (668MB/s)(18.7GiB/30006msec); 0 zone resets
slat (usec): min=3, max=5428, avg=193.15, stdev=195.33
clat (usec): min=462, max=49280, avg=12355.59, stdev=1834.97
lat (usec): min=807, max=49450, avg=12549.13, stdev=1853.74
clat percentiles (usec):
| 1.00th=[ 8979], 5.00th=[ 9896], 10.00th=[10421], 20.00th=[10945],
| 30.00th=[11469], 40.00th=[11863], 50.00th=[12256], 60.00th=[12649],
| 70.00th=[13042], 80.00th=[13566], 90.00th=[14484], 95.00th=[15270],
| 99.00th=[17695], 99.50th=[19268], 99.90th=[27132], 99.95th=[31065],
| 99.99th=[36963]
bw ( KiB/s): min=402097, max=704703, per=100.00%, avg=652565.98, stdev=1394.31, samples=1888
iops : min=100524, max=176172, avg=163139.81, stdev=348.57, samples=1888
lat (usec) : 500=0.01%, 750=0.01%, 1000=0.01%
lat (msec) : 2=0.01%, 4=0.01%, 10=6.01%, 20=93.62%, 50=0.37%
cpu : usr=1.59%, sys=54.20%, ctx=2344372, majf=0, minf=424
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwts: total=0,4893391,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
WRITE: bw=637MiB/s (668MB/s), 637MiB/s-637MiB/s (668MB/s-668MB/s), io=18.7GiB (20.0GB), run=30006-30006msec
Disk stats (read/write):
sdb: ios=0/4847188, merge=0/40007, ticks=0/7442861, in_queue=7442860, util=99.97%