【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.10
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
Scheduler - batch_get 中 Scheduler scan details [lock]
与查询耗时增加基本吻合,请问这种怎么定位以及优化


3kv+3pd+3tidb+3pump
3台机器 48c258g
看起来是扫描数据量变多了,dashboard 慢查询里面 按 process_key 和 total_keys 倒排序看下呢。
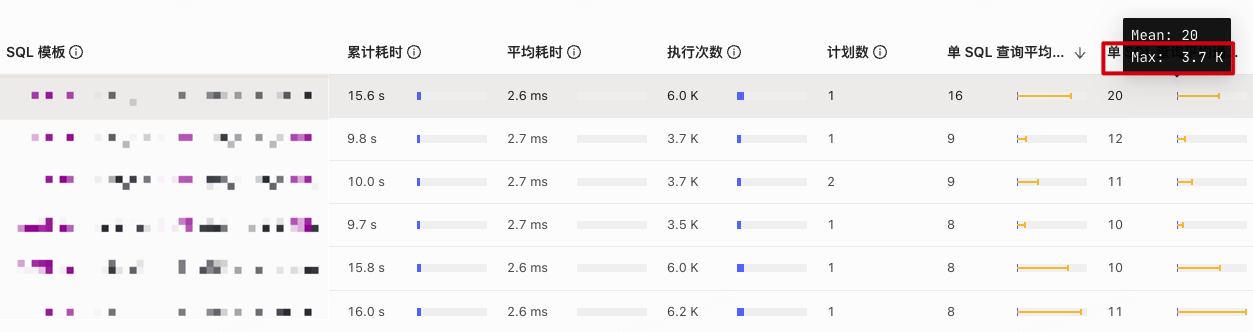
可以根据慢查询看下 扫描key多的sql 是否走到了错误的执行计划? 比如本来索引扫描走到了全表扫描,这样就会非预期的扫描到更多数据
你看看region的增长情况
老版本坏境,应该使用好几年了。首先检查下健康度。SHOW STATS_HEALTHY。健康度低的重新生成下。如果最近改过程序 或执行脚本,看看执行计划,看看索引情况。或者删除重建索引。还有看看tikv各个实例 region分布是否均匀。有没有热点情况。
目前看慢查询收集到的只有两条sql执行计划失效
4版本有dashboard了吧,去看看dashboard 的语句分析,不同时段同一SQL执行情况
按照这2篇文章的思路排查一下集群问题
好的,感谢
嗯嗯,目前看执行计划只有个别查询有问题
看着也没有什么问题的 ![]()
不仅仅是执行计划啊,那里也有执行时间分析啊
查询这个时间点的DML语句
这个时间是不是整个数据库延迟都增加了?
有没有没加索引的表在执行啊
耗时增加不是单纯的技术问题,要结合你自己的业务特性来看
首先你的业务场景是不是那个时间段高并发,如果高并发带来的资源紧张本身就会造成查询耗时增加,毕竟大家都在争抢同一个池子的资源。第二,找处特定sql,跟前面对比,是不是有些sql莫名出现在慢查中,查询计划是否有突变