【 TiDB 版本】7.1.2
使用DataX或者是TiSpark写入数据时,会造成TiKV CPU被占满,应该如何处理?

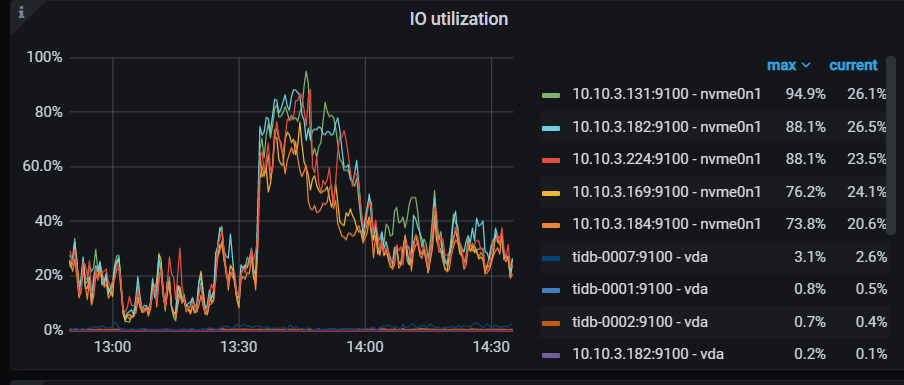
为什么我在写数据的时候,读的IO也会很高呢?

所有节点的IO都很高,应该不是写热点造成的,是真的写太快?
【 TiDB 版本】7.1.2
使用DataX或者是TiSpark写入数据时,会造成TiKV CPU被占满,应该如何处理?
为什么我在写数据的时候,读的IO也会很高呢?
所有节点的IO都很高,应该不是写热点造成的,是真的写太快?
使用 AUTO_RANDOM 处理自增主键
我这边是字符串做的主键,你是说,我改成用AUTO_RANDOM做主键,然后原来的主键做个索引?
AUTO_RANDOM这个不支持字符串啊,整型做主键可操作吗
我看了一下,感觉不是写热点造成的,我所有的节点IO都非常高,写入的数据量大概在20GB-50GB左右
你磁盘性能怎么样,感觉到磁盘读写极限了
另外compaction流量非常高,是否有大量的update、delete使得gc对磁盘造成很大的压力。
看截图中Read主要是compaction造成的,相对Write少了几倍。
RocksDB的compaction 包含2方面:一是memtable写满后flush到磁盘,这是一种特殊的compacttion,也称为minor compaction。二是从L0 层开始往下层合并数据,也被称为major compaction,也是常说的compaction。
Compaction 实际上就是一个归并排序的过程,将Ln层写入Ln+1层,过滤掉已经delete的数据,实现数据物理删除。其主要过程:
1、 准备:根据一定条件和优先级等从Ln/Ln+1层选择需要合并的sst文件,确定需要处理的key范围。
2、处理:将读到key value数据,进行合并、排序,处理不同类型的key的操作。
3、写入:将排序好的数据写入到Ln+1层sst文件,更新元数据信息。
5个节点,写IO都干到1GB/s了,已经很不错了 ![]()
主要是在用TiSpark在写数据,这个不太好控制写的速度,现在我还是TiSpark直接写到Hive去吧
io确实到一定的量了
这么高的写入量,高性能物理机和固态硬盘也难搞哇,只能加机器
这个IO,我感觉是没有到硬件极限的,我这边是用的华为云ECS,买的时候号称是1000MB/S的速度,不知道是不是因为写的时候也要占读IO的原因,实际的速度达不到1000*5的写速度,不过无所谓了,我不这样搞了,我还是直接写到hive了,而且我写到hive只要跑3分钟,写到tidb要跑1小时
有Hive还是写Hive吧 ![]()
这种不是写热点带来的问题,只能通过加机器来解决了
对于经常写入的表,去掉一些没用的索引,也能优化插入速度
正常的,你看你compaction的在写入读取里面占比都很高。
compaction的时候需要对一层进行排序写入,排序的时候当然会有高的读取占比。
逻辑导入就是这样的。要避免compaction的问题,就要使用物理导入,先排好序生成sst,直接放进tikv里面去。
tikv只想写入快,用聚簇表,除了主键不要加额外索引