春风十里
2023 年12 月 18 日 09:15
1
【 TiDB 使用环境】 测试/ Poc
问题重现:
分别通过sysbench导入一张200万条记录的表到TiDB V7.5和MySQL V5.12
分别计算大小
MySQL表大小截图
春风十里
2023 年12 月 18 日 09:22
2
还有一个疑问,information_schema.tables视图中说明 * DATA_LENGTH:数据长度。数据长度 = 统计信息中的行数 × 元组各列存储长度和,这里尚未考虑 TiKV 的副本数。
TiDB 的tikv节点实用的RocksDB,RocksDB的默认压缩算法为:[no:no:lz4:lz4:lz4:zstd:zstd]
表示 level0 和 level1 不压缩;
level2 到 level4 采用 lz4 压缩算法;
level5 和 level6 采用 zstd 压缩算法。
no 表示没有压缩,lz4 是速度和压缩比较为中庸的压缩算法,zlib 的压缩比很高,对存储空间比较友好,但是压缩速度比较慢,压缩的时候需要占用较多的 CPU 资源。
原文链接:TiDB的tikv节点的压缩算法_tidb 压缩算法-CSDN博客
1 个赞
zhanggame1
2023 年12 月 18 日 09:32
4
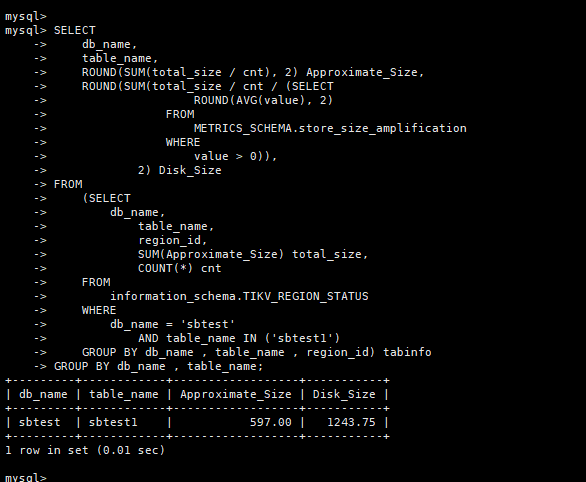
SELECT@dbname @table_name )
store_size_amplification 表示集群压缩比的平均值。除了使用 SELECT * FROM METRICS_SCHEMA.store_size_amplification; 语句进行查询以外,你还可以查看 Grafana 监控 PD - statistics balance 面板下各节点的 Size amplification 指标来获取该信息,集群压缩比的平均值即为所有节点的 Size amplification 平均值。
小龙虾爱大龙虾
2023 年12 月 18 日 11:07
7
information_schema.tables中的data_length是根据统计信息得到的吧,想真正测试压缩率,建议搞大点数据,最后看文件系统使用的对比,这样最真实
春风十里
2023 年12 月 18 日 12:36
8
看了下官方文档,感觉是和数据量太小有关系,
改天把测试环境数据导进来再试试
江湖故人
2023 年12 月 18 日 13:57
9
oltp_read_write里面有delete之类操作,单测insert比较公平,而且要尽量多的行数
tidb菜鸟一只
2023 年12 月 19 日 00:36
11
压缩之后1/3,然后三副本差不多大小一样了吧。。。sysbench准备的数据mysql和tidb大小对比是这样的。