Zealot
2023 年12 月 15 日 15:59
1
TiDB版本:7.1.2
现象:
建表DDL:dw_company_extend (id varchar(20) NOT NULL DEFAULT ‘’ COMMENT ‘公司ID’,staff_size varchar(255) DEFAULT ‘’ COMMENT ‘人员规模’,id) /*T![clustered_index] NONCLUSTERED */
随缘天空
2023 年12 月 16 日 05:35
3
可能是由于TiDB和TiSpark在处理字符串时的差异导致的。TiDB字符串默认使用utf8编码,而TiSpark默认使用latin1编码,你调整编码试试
1 个赞
这正常操作不应该会有这种情况,把这些语句的执行计划都贴一下
Kongdom
2023 年12 月 16 日 06:49
5
explain analyze table之后在查询试试?或者用mysql客户端连接查询试试
Zealot
2023 年12 月 18 日 01:43
11
我感觉似乎是主键索引没有被创建,我插入相同的主键ID,不会报错
Zealot
2023 年12 月 18 日 01:58
12
org.apache.spark.SparkException: Job aborted due to stage failure: Task 4 in stage 24.0 failed 4 times, most recent failure: Lost task 4.3 in stage 24.0 (TID 473) (hadoop-0002 executor 2): com.pingcap.tikv.exception.CodecException: Unsupported collation: latin1_bin
TiSpark真的支持这个编码吗?
select id from where id
Zealot
2023 年12 月 18 日 02:05
14
这种方法可以查到数据,加上and id= ?后就查不到了
dba远航
2023 年12 月 18 日 02:23
15
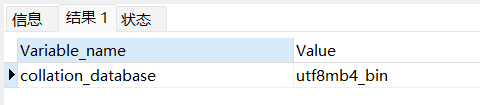
检查一下数据库的排序规则:collation_database
dba远航
2023 年12 月 18 日 02:31
17
我本地测试结果 ,没有发现异常
mysql> select * from dw_company_extend where id = ‘95100000101705142Q’;
mysql> select id from dw_company_extend limit 1;
Zealot
2023 年12 月 18 日 02:40
18
你复现的方式不对,我正常使用mysql端的insert select也是没问题的,问题在于,使用TiSpark插入大量数据的时候,执行insert into select,数据量在5000万-1亿,执行成功后,查询出现异常现象,这个问题不好复现,因为我在数据量小的时候(10条数据),也是正常的
Zealot
2023 年12 月 18 日 03:14
19
admin check table dw_company_extend
Zealot
2023 年12 月 18 日 04:39
20
重新跑完正常了,看来真的是两个表字符集不一致导致的问题,不知道算不算是bug